宽表的Sqoop导入
 社区干货
社区干货
干货|字节跳动基于 Apache Hudi 的多流拼接实践
字节跳动存在较多业务场景需要基于具有相同主键的多个数据源实时构建一个大宽表,数据源一般包括 Kafka 中的指标数据,以及 KV 数据库中的维度数据。业务侧通常会基于实时计算引擎在流上做多个数据源的 JOIN 产出这个宽表,但这种解决方案在实践中面临较多挑战,主要可分为以下两种情况:## **1.1 维表 JOIN**- **场景挑战:** 指标数据与维度数据进行关联,其中维度数据量比较大,指标数据 QPS 比较高,导致数据可能会产出延迟。-...
干货|字节跳动基于 Apache Hudi 的多流拼接实践
字节跳动存在较多业务场景需要基于具有相同主键的多个数据源实时构建一个大宽表,数据源一般包括 Kafka 中的指标数据,以及 KV 数据库中的维度数据。业务侧通常会基于实时计算引擎在流上做多个数据源的 JOIN 产出这个宽表,但这种解决方案在实践中面临较多挑战,主要可分为以下两种情况:**01 - 维表 JOIN*** **场景挑战:**指标数据与维度数据进行关联,其中维度数据量比较大,指标数据 QPS 比较高,导致数据可能会产出...
字节跳动基于 Apache Hudi 的多流拼接实践
字节跳动存在较多业务场景需要基于具有相同主键的多个数据源实时构建一个大宽表,数据源一般包括 Kafka 中的指标数据,以及 KV 数据库中的维度数据。业务侧通常会基于实时计算引擎在流上做多个数据源的 JOIN 产出这个宽表,但这种解决方案在实践中面临较多挑战,主要可分为以下两种情况:## **1.1 维表 JOIN**- **场景挑战:** 指标数据与维度数据进行关联,其中维度数据量比较大,指标数据 QPS 比较高,导致数据可能会产出延迟。-...
达梦@记一次国产数据库适配思考过程|社区征文
文件等方式迁移导入**。这里记录一下迁移过程中遇到的问题,**在迁移的时候,报某些字段超长**。于是,查看了MySql中那些字段的类型及长度,都是varchar(50) 。这里应该是迁移有些字段,须在DM数据库中增加位宽,在MySql中varchar是表示字符,varchar(50)表示可以存放50个字符,但是DM的默认跟Oracle是一样的,varchar(50)表示50个字节。这就意味着,50个字节,如果存中文,在utf-8的字符集下,只能存最多16个。所以,如果MySql库到DM,varchar类...
 特惠活动
特惠活动
 宽表的Sqoop导入-优选内容
宽表的Sqoop导入-优选内容
 宽表的Sqoop导入-相关内容
宽表的Sqoop导入-相关内容
达梦@记一次国产数据库适配思考过程|社区征文
文件等方式迁移导入**。这里记录一下迁移过程中遇到的问题,**在迁移的时候,报某些字段超长**。于是,查看了MySql中那些字段的类型及长度,都是varchar(50) 。这里应该是迁移有些字段,须在DM数据库中增加位宽,在MySql中varchar是表示字符,varchar(50)表示可以存放50个字符,但是DM的默认跟Oracle是一样的,varchar(50)表示50个字节。这就意味着,50个字节,如果存中文,在utf-8的字符集下,只能存最多16个。所以,如果MySql库到DM,varchar类...
StarRocks表模型设计
导入日志数据或者时序数据,主要特点是旧数据不会更新,只会追加新的数据。 2.2 创建表例如,需要分析某时间范围的某一类事件的数据,则可以将事件时间(event_time)和事件类型(event_type)作为排序键。在该业务场景... 一般会采用大宽表方式来提升多维分析的性能,同时简化数据分析师的使用模型。而这种场景中的上游数据,往往可能来自于多个不同业务(比如来自购物消费业务、快递业务、银行业务等)或系统(比如计算用户不同标签属性的机...
EMR-2.2.0 版本说明
支持外部表方式访问数据; 【组件】presto-cli和trino-cli支持非明文方式输入密码,避免潜在的暴露密码风险; 【组件】Hue查询Presto、Trino时不再使用默认用户,需进行额外的用户认证;修复部分安全问题; 【组件】Iceberg适配TOS的读写,支持与PySpark的交互; 【组件】Dolphin Scheduler升级至3.1.3; 【组件】存算分离场景下,优化Spark引擎和MapReudce的写入性能。 已知问题通过Sqoop从SQL Server导入数据时,存在编码异常问题,...
基于火山引擎 EMR 构建企业级数据湖仓
导致了他们在演化过程中变得越来越相似。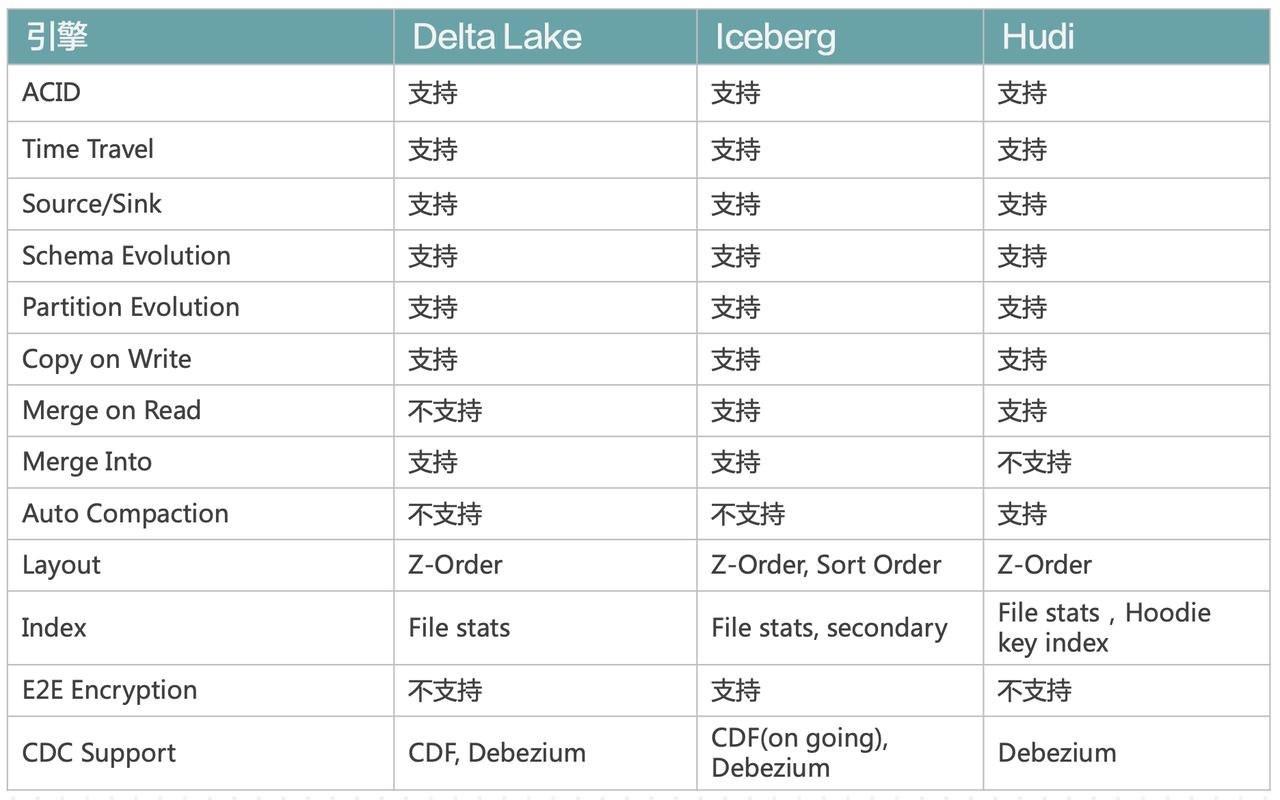可以看到,绝大部分特性这三者都是支持... 分析实时化的表现有(近)实时引擎和流引擎。- (近)实时引擎 - ClickHouse:近实时 OLAP 引擎,宽表查询性能优异 - Doris:近实时全场景 OLAP 引擎 - Druid:牺牲明细查询,将 OLAP 实时化,毫秒级...
大数据学习架构实践|社区征文
Sqoop:Sqoop是关系型数据库和HDFS之间的一个桥梁,写的时候除了HDFS,还可以写Hive,甚至可以直接去建表。而且可以在源数据库设立是导整个数据库,还是导某一个表,或者导特定的列,这都是常见的在数据仓库中进行的ETL。2)Flume:采集日志系统等非结构化数据;## **4.2 数据存储**1)HDFS:分布式文件系统;2)HBase:建立在HDFS之上的列式数据库,HBase的存储依旧是以HDFS文件的形式存在的。## **4.3 数据计算**### **4.3.1 离线计...
一文读懂火山引擎云数据库产品及选型
其中主流的商业关系型数据库代表有 Oracle、SQL Server、DB2 等;主流的开源关系型数据库代表有 MySQL、PostgreSQL、MariaDB 等。**NoSQL**,Not Only SQL,"不仅仅是 SQL",广泛应用于以互联网业务为代表的场景。NoSQL 数据库又可以**细分为 KV 型 NoSQL 数据库(以 Redis 为代表)、文档型 NoSQL 数据库(以 MongoDB 为代表)、宽列型 NoSQL 数据库(以 HBase 为代表)、时序型 NoSQL 数据库(以 InfluxDB 为代表)以及图 NoSQL 数据库(以...
干货 | 这样做,能快速构建企业级数据湖仓
导致了他们在演化过程中变得越来越相似。可以看到,三种数据格式都基本能覆盖绝大部分特性。实时引擎和流引擎。 * **(近)实时引擎**+ ClickHouse:近实时 OLAP 引擎,宽表查询性能优异+ Doris:近实时全场景 OLAP 引擎+ Druid:牺牲明细查询,将 OLAP 实时化,毫秒级返回* **流引...
EMR-2.1.0版本说明
ZooKeeper 3.7.0 3.7.0 Flink 1.15.1 - HDFS 2.10.2 2.10.2 MapReduce2 2.10.2 - YARN 2.10.2 - Airflow 2.4.2 - Hive 2.3.9 - Hue 4.9.0 - Knox 1.5.0 - Presto 0.267 - Trino 392 - Spark 2.4.8 - Sqoop 1.4.7... sqoop 1.4.7 提供数据库与HDFS导入导出功能。 iceberg 0.12.0 Apache Iceberg 是一种适用于超大型分析数据集的开放表格式。 yarn_resourcemanager 2.10.2 分配和管理集群资源与分布式应用程序的 YARN 服务。 yarn...
EMR-2.1.1 版本说明
ZooKeeper 3.7.0 3.7.0 Flink 1.15.1 - HDFS 2.10.2 2.10.2 MapReduce2 2.10.2 - YARN 2.10.2 - Airflow 2.4.2 - Hive 2.3.9 - Hue 4.9.0 - Knox 1.5.0 - Presto 0.267 - Trino 392 - Spark 2.4.8 - Sqoop 1.4.7... sqoop 1.4.7 提供数据库与HDFS导入导出功能。 iceberg 0.12.0 Apache Iceberg 是一种适用于超大型分析数据集的开放表格式。 yarn_resourcemanager 2.10.2 分配和管理集群资源与分布式应用程序的 YARN 服务。 yarn...
