多个CTE和group by
 社区干货
社区干货
基于ClickHouse的复杂查询实现与优化|社区征文
## 项目背景ClickHouse的执行模式与Druid、ES等大数据引擎类似,其基本的查询模式可分为两个阶段。第一阶段,Coordinator在收到查询后,将请求发送给对应的Worker节点。第二阶段,Worker节点完成计算,Coordinator在收到各Worker节点的数据后进行汇聚和处理,并将处理后的结果返回。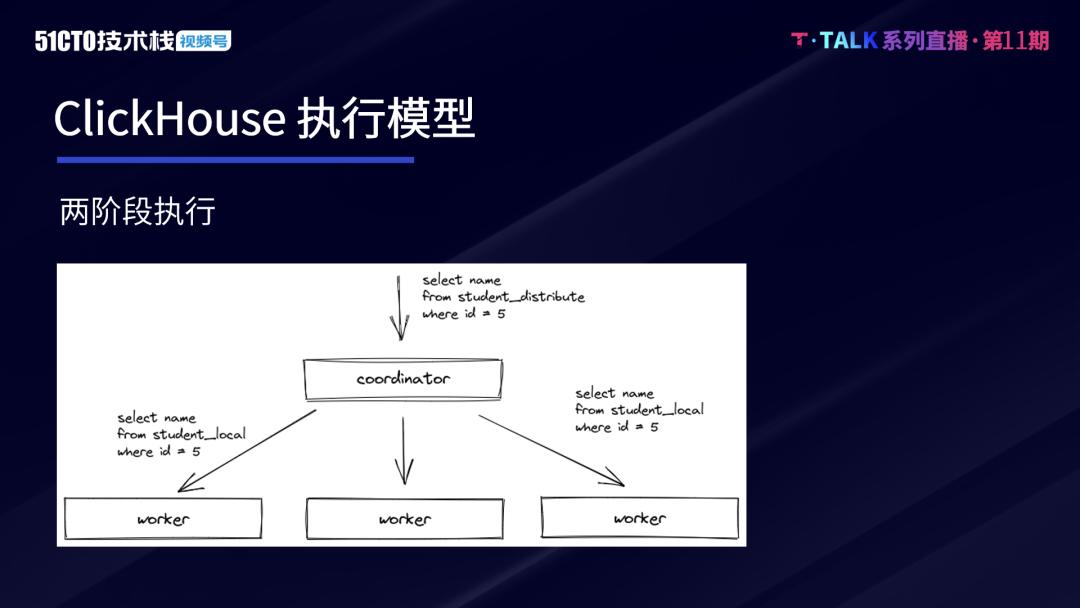两阶段的执行模式能...
字节跳动 Spark Shuffle 大规模云原生化演进实践
与此同时作业量与 Shuffle 的数据量还在增长,相比去年,今年的天任务数增加了 50 万,总体数据量的增长超过了 200 PB,达到了 50% 的增长。Shuffle 是用户作业中会经常触发的功能,各种 ReduceByKey、groupByKey、Join... Shuffle 的过程可以分为两个阶段— Shuffle Write 和 Shuffle Read。Shuffle Write 的时候,Mapper 会把当前的 Partition 按照 Reduce 的 Partition 分成 R 个新的 Partition 并排序后写到本地磁盘上。生成的 Map ...
干货 | 基于ClickHouse的复杂查询实现与优化
(https://p6-volc-community-sign.byteimg.com/tos-cn-i-tlddhu82om/5b0c5e11c061421d8530644503540bd4~tplv-tlddhu82om-image.image?=&rk3s=8031ce6d&x-expires=1716222056&x-signature=fCS6R7QjKf%2BI3aoPIdrGpAIgttw%3D)**项目背景**ClickHouse的执行模式与Druid、ES等大数据引擎类似,其基本的查询模式可分为两个阶段。第一阶段,Coordinator在收到查询后,将请求发送给对应的Worker节点。第二阶段,Worker节点完...
2022技术盘点之平台云原生架构演进之道|社区征文
Gitlab-Runner 会自动创建一个或多个新的临时 Runner来运行Job。- 资源最大化利用:动态创建Pod运行Job,资源自动释放,而且 Kubernetes 会根据每个节点资源的使用情况,动态分配临时 Runner 到空闲的节点上创建,降低... `spring-boot-actuator/ spring-boot-actuator-autoconfigure` 两个包的引入,使得应用可以进行热更新,当configmap/secret发生变更的时候,可以不重启Pod或进程进行热变更配置。方案特点:- 优势:使用K8s内置资源...
 特惠活动
特惠活动
 多个CTE和group by-优选内容
多个CTE和group by-优选内容
 多个CTE和group by-相关内容
多个CTE和group by-相关内容
Kafka订阅埋点数据(私有化)
ConsumerGroup:确认好ConsumerGroup,以免冲突,导致数据消费异常; 确认需要消费的app_id:Topic中存在多个app_id,需要消费数据后从中过滤出自己关心的app_id。 2. 订阅方式 您可以根据需要选择不同的方式订阅流数据... properties.put("group.id", "test_group"); properties.put("auto.offset.reset", "earliest"); properties.put("key.deserializer", "org.apache.kafka.common.serialization.ByteArrayDeserializer")...
Kafka订阅埋点数据(私有化)
ConsumerGroup:确认好ConsumerGroup,以免冲突,导致数据消费异常; 确认需要消费的app_id:Topic中存在多个app_id,需要消费数据后从中过滤出自己关心的app_id。 2. 订阅方式 您可以根据需要选择不同的方式订阅流数据... properties.put("group.id", "test_group"); properties.put("auto.offset.reset", "earliest"); properties.put("key.deserializer", "org.apache.kafka.common.serialization.ByteArrayDeserializer")...
Kafka订阅埋点数据(私有化)
ConsumerGroup:确认好ConsumerGroup,以免冲突,导致数据消费异常; 确认需要消费的app_id:Topic中存在多个app_id,需要消费数据后从中过滤出自己关心的app_id。 2. 订阅方式 您可以根据需要选择不同的方式订阅流数据... properties.put("group.id", "test_group"); properties.put("auto.offset.reset", "earliest"); properties.put("key.deserializer", "org.apache.kafka.common.serialization.ByteArrayDeserializer")...
SQL Statements
[groupByClause][havingClause][orderByClause][limitByClause][limitClause][settingsClause]DISTINCT , only unique rows will remain in a query result. It works with NULL as if NULL were a specific value... SELECT id FROM test.havingClause GROUP BY id HAVING count(id)>2; -- only 1 is expected. array Join ClauseFor table contains array column, array join can produce a new table that has a column with e...
自定义看板
3位和4位。 Y轴 Y轴最大值和最小值,用于限制趋势图Y轴显示区间。 图例 趋势图下方是否展示图例。默认打开,表示展示图例。图例名称默认为指标名称。图例字段默认展示最大、最小、平均和当前的指标取值。 指标 支持选择需要查询的指标,允许添加多个。支持主机、进程、容器、服务、自定义指标相关的指标。 筛选 筛选维度。 时间区间统计方式 默认为Group by,自定义指标支持其他统计方式。 Group by:分组 AVG:SUM(每个时间...
SQL 语法
[ FILTER ( WHERE boolean_expression ) ]参数 GROUPING SETS对分组集中指定的表达式的每个子集的行进行分组。例如,GROUP BY GROUPING SETS (warehouse, product)在语义上等同于GROUP BY warehouse仓库和GROUP BY product的结果的联合。该子句是UNION ALL的简写,其中UNION ALL运算符的每个分支执行GROUPING SETS子句中指定的列子集的聚合。 grouping_set分组集由括号中的零个或多个逗号分隔表达式指定。语法: ( [ ] ) grouping...
从100w核到450w核:字节跳动超大规模云原生离线训练实践
两个部分——计算调度和数据编排,最后将结合前两部分分享字节跳动在实践中沉淀的4个案例。**作者|单既喜-字节跳动基础架构研发工程师**# **业务背景**计算每个执行计划的Cost,从中挑选Cost最小的执行计划。缩短查询日期范围,减少查询数据量 (2)增加过滤条件,减少查询数据量 可视化查询报错 Memory limit (for user) exceeded相似问题:可视化查询报... 即筛选的日期字段和图表中使用的日期字段并非同一个字段。 解决方案: 将需要筛选的业务日期字段作为筛选器,选出实际符合条件的数据。 可视化查询对单个字段筛选多个值相似问题: IN 和 arrayhas 的功能如何使用可视...
