数据存储:“没有这样的结构字段”
 社区干货
社区干货
9年演进史:字节跳动 10EB 级大数据存储实战
Yarn,Flink 的计算框架平台数据 - Spark,MapReduce 的计算相关数据存储![]()# **字节跳动特色的** **HDFS** **架构**在深入相关的技术细节之前,我们先看看字节跳动的 HDFS 架构。## **架构介绍** 字... 由于我们的 DanceNN 底层元数据实现了本地目录树管理结构,因此我们 DanceNN 的启动优化都是围绕着这样的设计来做的。#### **多线程扫描和填充 BlockMap**在系统启动过程中,第一步就是读取目录树中保存的信息并...
[数据库系统] 业界列式存储浅析
行存的实现一般是将一行数据完整的从头到尾连续存储(超长的字段一般会单独存储,行内记录逻辑地址),连续多行构成一个页,页的尾部通常会存储索引来解决record不定长时的快速查找问题,数据排列结构如下图所示: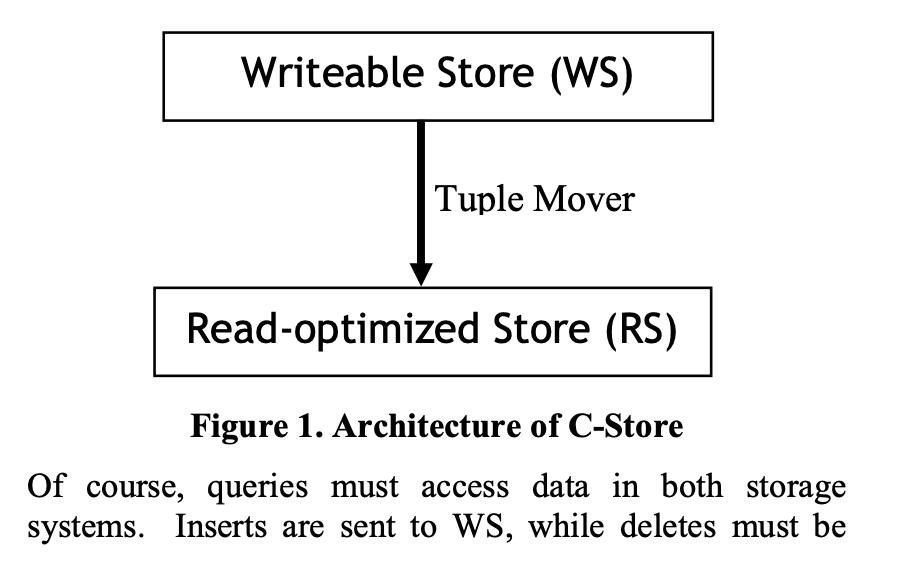系统分为两层:1. WS:Writeable store,作用是提供高性能的 inserts和...
数据表公式、模板字段新增数据存储功能
[picture.image](https://p6-volc-community-sign.byteimg.com/tos-cn-i-tlddhu82om/9f258c3c60834f969f69e23557eef584~tplv-tlddhu82om-image.image?=&rk3s=8031ce6d&x-expires=1715962817&x-signature=b0Xgz9EyWp76zkc8qABfcgKIYwQ%3D)为了提升用户轻松处理和组织大量的数据的效率,本周,集简云数据表将公式、模板字段增加了数据存储功能,让用户可以对数据进行计算、分析以及筛选排序等,以便更好地运用于业务场景中。...
9年演进史:字节跳动 10EB 级大数据存储实战
Kafka 数据存储* Yarn,Flink 的计算框架平台数据* Spark,MapReduce 的计算相关数据存储**02****字节跳动特色的 HDFS 架构**在深入相关的技术细节之前,我们先看看字节跳动... 数据实现了本地目录树管理结构,因此我们 DanceNN 的启动优化都是围绕着这样的设计来做的。##### **多** **线程** **扫描和填充 BlockMap**在系统启动过程中,第一步就是读取目录树中保存的信息并且填入 B...
 特惠活动
特惠活动
 数据存储:“没有这样的结构字段”-优选内容
数据存储:“没有这样的结构字段”-优选内容
 数据存储:“没有这样的结构字段”-相关内容
数据存储:“没有这样的结构字段”-相关内容
业务数据清洗,落地实现方案 | 社区征文
很多版本在当时没有时间去全局考虑,导致很多业务数据存储和管理并不规范,例如常见的问题:- 地址采取输入的方式,而非三级联动;- 没有统一管理数据字典获取接口;- 数据存储的位置和结构设计不合理;- 不... 读数据源:文件、缓存、数据库等;- 临时容器:清洗过程存储节点数据;- 写数据源:清洗后数据注入的容器;所以清洗数据的第一步就是明确整个流程下要适配多少数据源,做好服务的基础功能设计与架构,这是支撑...
Redis String 实现 ID 生成器,底层为啥用 SDS 存储数据?| 社区征文
用于存储登录后的用户信息,key = token,value = Java 对象序列化成 JSON 后的字符串。如下指令。```SET user:token:666 {"name": "码哥",“gender”: “M”,“city”:"shenzhen"}```接下来,我先带你深入了解 String 类型,底层数据结构和使用场景。> MySQL:“你都是用 C 语言开发出来的,C 语言本就有字符串,吓唬谁呢。”格局能不能打开一点,我并没有直接使用 C 语言的字符串,而是自己搞了一个 SDS 结构体来表示字符串...
数据服务基础能力之元数据管理 | 社区征文
字段面板:提供业务数据结构的字段映射,和常规字段类型配置,用来支撑组合面板的表单配置。 - 数据结构:对现有业务结构做映射,可能是文件、数据表、JSON等,生成相对标准的字段选项; - 拓补字段:维护一批基础的字段类型,用来做拓补操作,完善整个业务结构;- 组合面板:承载字段的组合管理,生成新的数据结构,根据业务场景,完成底层数据的抽取存储或者API服务生成。 - 业务主体:通过业务需求的判断,明确面板支撑的...
一种在数据量比较大、字段变化频繁场景下的大数据架构设计方案|社区征文
目前大数据中数仓建设方案有很多,但一般都是常规的设计方案,如果在数据量比较大,字段频繁变更,数据频繁刷新,大数据架构方面如何设计呢。大数据架构的设计方案需要考虑多个方面,包括数据存储、数据处理、数据传输... 但是要注意采集数据时需要能捕获到源系统表结构的变更,可以采用Flink CDC等。ODS层的数据落到Kakfa中,设置一个较长的保存周期。kafka直接作为数仓的存储层,优点是不关心数据的格式,不管源系统字段怎么变,都可以J...
添加/修改字段
1. 概述 字段(Field)用来描述和存储数据,字段表达式则用来描述该字段对应的逻辑内容。本产品支持用户通过自定义表达式的形式将一个或多个字段表达为一个新的字段。在当前字段内容不能满足分析需求时候,可以选择增加... 用于数据分析。例如:利用订单数量和订单价格字段,新建 GMV 字段。 2.2 添加字段第一步 :点击数据集名称右侧的设置,选择「添加字段」。第二步 :填写该字段名称,指定维度指标分类,编辑表达式,保存后即可查询。 2.3 ...
使用大数据文件存储静态存储卷
大数据文件存储(Cloud File System , 简称 CloudFS)是火山引擎面向大数据和机器学习生态的文件存储和加速服务,支持标准的 HDFS 协议访问和数据湖透明访问模式,为您提供低成本、高性能、高吞吐和高可用的大数据文件... 在存储卷管理页面,单击 创建存储卷。 在弹出的存储卷创建页面,完成参数配置。 配置项 说明 创建方式 选择存储卷的创建方式,目前支持 静态创建。 名称 自定义存储卷的名称,需确保存储卷名称在集群内唯一。 存储类...
火山引擎 LAS 数据湖存储内核揭秘
LAS 的整体架构存算分离,计算存储可以按需扩展,避免资源浪费,因为存算分离,所以一份数据可以被多个引擎分析。相较于存算一体,成本 TCO 可以下降 30%-50%,并且 LAS 支持动态弹性扩缩容,可进一步降低用户成本。