创建一个本地目录用于在拉取新代码后编辑代码
 社区干货
社区干货
2022技术盘点之平台云原生架构演进之道|社区征文
CI/CD:各业务代码仓库保护.gitlab.yml,利用Gitlab CI进行CI和CD过程- 镜像管理:构建出来的镜像使用镜像仓库Harbor进行管理- 容器编排:在CD过程中,利用kubectl set image进行容器编排部署,自建Kubernetes集群进行业务容器编排管理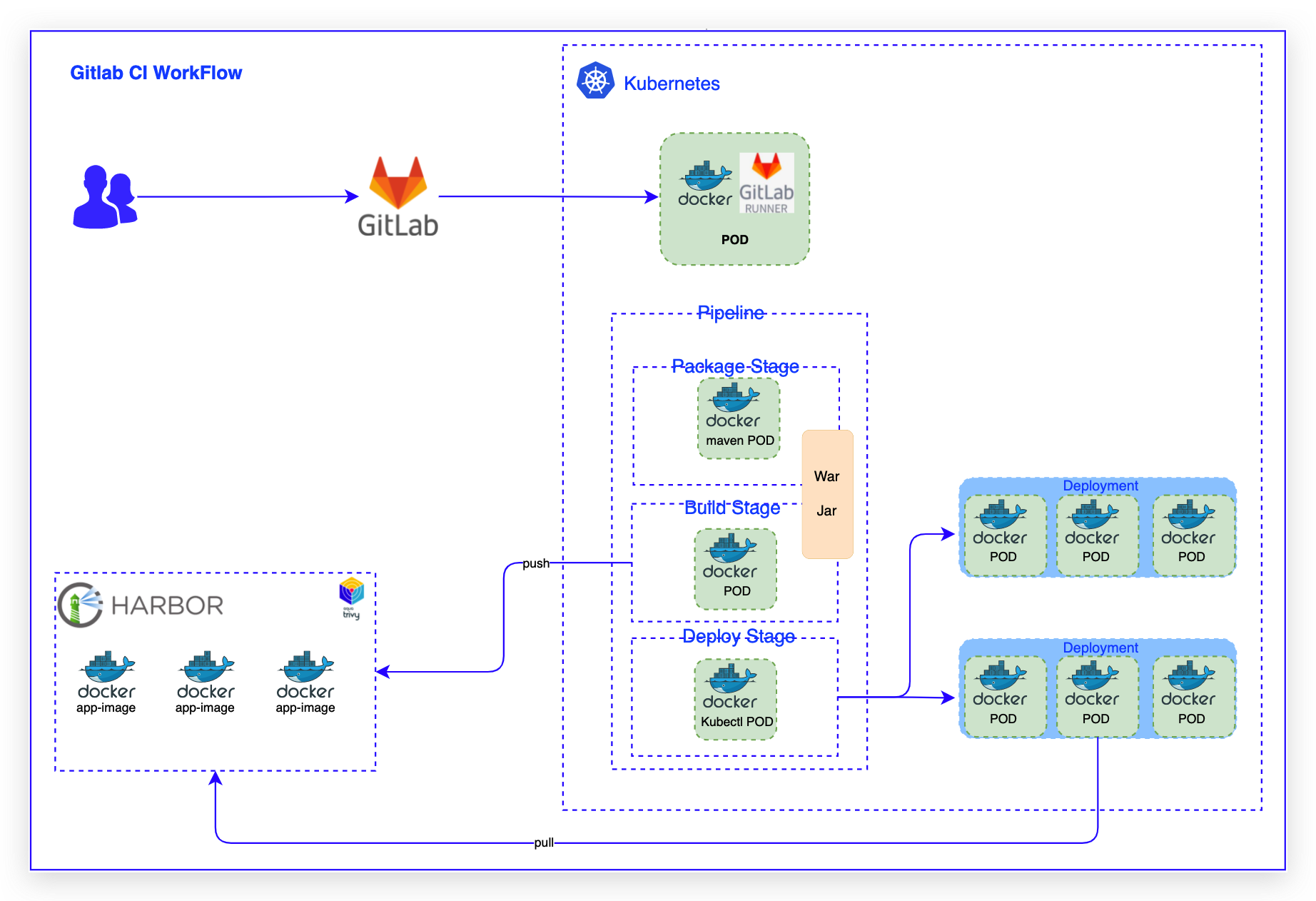- 高可用:当某个节点出现故障时,Kubernetes 会自动创建一个新的 GitLab-Runner 容器,并挂...
火山引擎 DataLeap 套件下构建数据目录(Data Catalog)系统的实践
通常是从外部系统拉取最新元数据,与当前Catalog系统的元数据做对比,并更新差异的部分 - MQ:用于暂存各类元数据增量消息,供Catalog系统近实时消费 - 与上游系统打交道的各类Clients,封装了操作底层资源的能力### 核心服务层系统的核心服务,根据职责的不同,细拆为以下子服务:- Catalog Service:支持元数据的搜索、详情、修改等核心服务- Ingestion Service:接受外部系统调用,写入元数据,或主动从MQ中消费增...
一文了解 DataLeap 中的 Notebook
你可以交互式地在其中编写你的代码、运行代码、查看输出、可视化数据并查看结果,使用起来非常灵活。在数据开发领域,Notebook 广泛应用于数据清理和转换、数值模拟、统计建模、数据可视化、构建和训练机器学习模型... Notebook 指的是代码文件,一般在文件系统中存储,后缀名为`ipynb`。Jupyter Notebook 后端提供了管理这些文件的能力,用户可以通过 Jupyter Notebook 的页面创建、打开、编辑、保存 Notebook。在 Notebook 中,用...
技术资讯:VSCode大更新,这两个. 功能终于有了
浮动编辑器窗口 - 将编辑器拖放到桌面上。- 无障碍视图工作流程 - 更顺畅地往返于无障碍视图。- 更精细的扩展更新控制 - 选择要自动更新的扩展。- 源代码控制传入和传出视图 - 轻松查看待处理的存储库... 再手动复制文件到相应目录中。但在最新版本中,增加了一个实用的新功能:可直接从操作系统的资源管理器中,粘贴文件到VSCode的目录里。这意味着,用户现在可以更方便的,从他们的电脑文件系统中复制需要的静态资源文...
 特惠活动
特惠活动
 创建一个本地目录用于在拉取新代码后编辑代码-优选内容
创建一个本地目录用于在拉取新代码后编辑代码-优选内容
 创建一个本地目录用于在拉取新代码后编辑代码-相关内容
创建一个本地目录用于在拉取新代码后编辑代码-相关内容
火山引擎 DataLeap 套件下构建数据目录(Data Catalog)系统的实践
通常是从外部系统拉取最新元数据,与当前Catalog系统的元数据做对比,并更新差异的部分 - MQ:用于暂存各类元数据增量消息,供Catalog系统近实时消费 - 与上游系统打交道的各类Clients,封装了操作底层资源的能力### 核心服务层系统的核心服务,根据职责的不同,细拆为以下子服务:- Catalog Service:支持元数据的搜索、详情、修改等核心服务- Ingestion Service:接受外部系统调用,写入元数据,或主动从MQ中消费增...
新功能发布记录
代码源敏感信息管控优化 编辑代码源时,不再显示代码源的密码、Token、SK 等敏感信息。 全部 2024-01-11 无 2023年12月功能名称 功能描述 发布地域 发布时间 相关文档 镜像构建支持指定通用构建参数 使用 docker b... 适配代码源类型更加丰富。 创建代码源支持选择通用 Git 类型。 流水线支持拉取通用 Git 代码源。 全部 2023-10-23 创建代码源获取通用 Git 的 Token 代码源支持接入 BitbucketCloud 新增支持接入 BitbucketCl...
使用文档
平台将其拼接在入口命令后Args: "" 标签Tags: [tag1,tag2] 本地的代码路径,如是目录且以 '/' 结尾,则将该目录下的所有内容上传到 RemoteMountCodePath,如是目录且不以 '/' 结尾,则将该目录及该目录下 所有内容上传... 在详情页中仅创建人可见 镜像 URL 地址ImageUrl: "replace with your ImageUrl" 当 ImageUrl 为私有仓库的镜像时需要填写仓库的用户名和密钥才能拉取镜像ImageCredential: RegistryUsername: "replace with you...
一文了解 DataLeap 中的 Notebook
你可以交互式地在其中编写你的代码、运行代码、查看输出、可视化数据并查看结果,使用起来非常灵活。在数据开发领域,Notebook 广泛应用于数据清理和转换、数值模拟、统计建模、数据可视化、构建和训练机器学习模型... Notebook 指的是代码文件,一般在文件系统中存储,后缀名为`ipynb`。Jupyter Notebook 后端提供了管理这些文件的能力,用户可以通过 Jupyter Notebook 的页面创建、打开、编辑、保存 Notebook。在 Notebook 中,用...
KubeWharf:构建下一代分布式操作系统的云原生力量|社区征文
构建大规模多租户集群、离线混合部署以及存储和机器学习云原生化场景的首选解决方案。# KubeWharf 案例分享**1.创建 Kubernetes 集群并安装 KubeWharf**首先,需要创建一个 Kubernetes 集群,并在其中安装 KubeWharf。这一步可以通过云服务提供商的控制台或者命令行工具来完成。**2.编写 Dockerfile 文件**接下来,需要编写一个 Dockerfile 文件,用于构建 Docker 镜像。假设 Web 应用程序代码都在一个名为 app 的目录中,可以...
使用持续交付实现 Kubernetes 部署
注意事项编译构建 任务中的 编译命令 需要根据具体业务代码进行调整,错误的路径信息可能导致流水线运行失败。 前提条件容器服务 已开通火山引擎容器服务。 已创建容器服务集群,具体操作请参见 创建集群。 已创建无状态工作负载 Deployment,具体操作请参见 创建无状态负载。并记录该 Deployment 的名称、所属的命名空间、对应的 Container 名称,用于后续配置 Kubernetes 镜像升级任务。 镜像仓库 已开通火山引擎镜像仓库服务。 ...
干货|ByteHouse+Airflow:六步实现自动化数据管理流程
Apache Airflow提供了一个强大的平台,用于设计和编排数据流程,更轻松的处理复杂的工作流程。搭配ByteHouse的云原生数据仓库解决方案,可以高效地存储和处理大量数据,确保数据流程的可扩展性和可靠性。 **二、自动化工作流管理:**Airflow的直观界面通过可视化的DAG(有向无环图)编辑器,使得创建和调度数据工作流程变得容易。通过与ByteHouse集成,可以自动化提取、转换和加载(ETL)过程,减少手动工作量,实现更高效的数据管理...
火山引擎部署ChatGLM-6B实战指导
发布的一个开源的对话机器人,由清华技术成果转化的公司智谱 AI 开源,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。