最终输出的问题
 社区干货
社区干货
万字长文带你弄透Transformer原理|社区征文
讲到这里,我相信大家已经知道问题就出在输入输出的维度上的,那么后文我们就会默认经过Attention模块后输入输出的维度保持不变。 这部分我没有修改这部分代码及图片以保证输入输出维度一致一方面是偷了个懒,另一方面是想让大家更加深刻的意识到这个输入输出维度的问题。 **还有一点需要注意,在下文介绍Multi-Head Attention时我们是通过最后乘一个$W^o$矩阵实现输入输出前后维度一致的,在相关部分我也会介绍。** 🌷🌷🌷🌷🌷...
排查Redis实例网络输入/输出速率高的问题
# **问题现象**查看 Redis 监控,发现网络 输入/ 输出速度较高,可能与预期不相符,甚至可能已经超过该规格的最大带宽。本文描述了排查 Redis 网络输入/输出速率高的问题。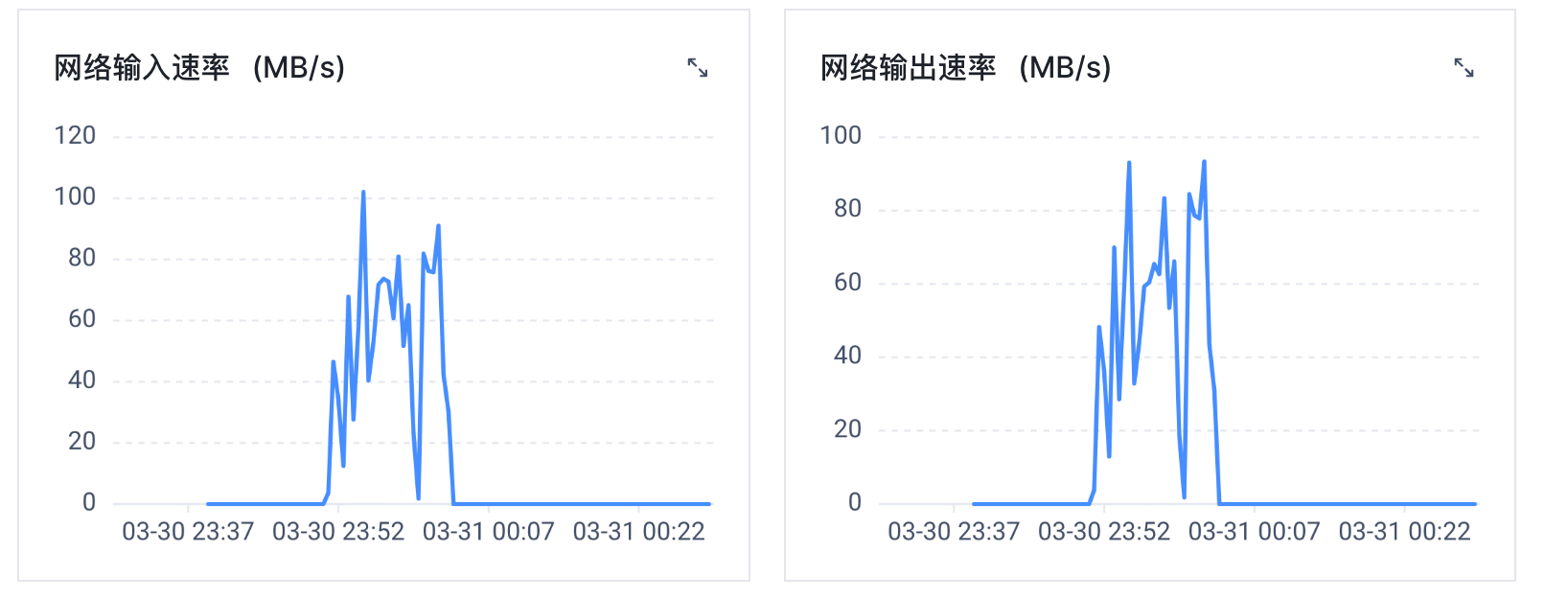# 问题定位当业务的访问量与预期带宽消耗不匹配,可以执行如下步骤进行排查。1. ## **是否存在非预期内的读写 QPS 突增**...
Java程序性能分析:内存
常用命令格式:jstat -gcutil 进程号 持续输出间隔毫秒数,下图每隔 1000毫秒输出一次- 前6列 输出各个内存区域使用百分比 (没有容量大小),依次是 幸存区survivor0、1、新生代Eden、老年代Old、元数据 Metaspace、Compressed class space- GC 结尾的列 表示 GC次数,GCT 结尾的 表示 GC耗时,依次是 Young GC 次数和耗时、Full GC、Compressed class space GC,最后一列 GCT 是 Total总GC耗时- 2次相邻的GC,可以快速判断那一次GC...
CVPR 2024 | CAMixerSR 动态注意力分配的超分辨率加速框架
超分辨率是一个经典的计算机底层视觉问题,该问题要解决的是通过低分辨率的图像输入,获得高分辨率的图像输出。目前该领域的算法模型主要是有CNN以及Transformer两大类别,考虑到实际的应用场景,超分的一个细分领域方... 将**Self-Attention**的结果合并后即可得到我们最后的输出结果。## 实验 特惠活动
特惠活动
 最终输出的问题-优选内容
最终输出的问题-优选内容
 最终输出的问题-相关内容
最终输出的问题-相关内容
字节跳动使用 Flink State 的经验分享
直到最后输出。为了防止作业失败,状态丢失,Flink 引入了分布式快照 Checkpoint 的概念,定期将 State 持久化到 Hdfs 上,如果作业 Failover,会从上一次成功的 checkpoint 恢复作业的状态(比如 kafka 的 offset,窗口内... 在使用 Flink State 时是否经常会面临以下问题:* 某个状态算子出现处理瓶颈时,加资源也没法提高性能,不知该如何排查性能瓶颈* Checkpoint 经常出现执行效率慢,barrier 对齐时间长,频繁超时的现象* 大作业的 ...
CVer从0入门NLP——GPT是如何一步步诞生的|社区征文
最后根据损失不断的调整两个表。当训练完成后,我们就得到了我们的Embedding表,也就是Q矩阵。🍗🍗🍗## RNN模型> 上一小节我们介绍了词向量,它解决的是我们NLP任务中输入问题。下面我们将一起来唠唠NLP任... `rnn_output`其实就是每个隐藏层的输出,而`state_final`则是最终的输出,在基础的RNN中,`state_final`的值就等于最后一个隐藏层的输出,我们从数值上也可以发现,如下: