数据是人工智能时代的石油,但是由于监管法规和商业机密等因素限制,"数据孤岛"现象越来越明显。联邦学习(Federated Learning)是一种新的机器学习范式,它让多个参与者可以在不泄露明文数据的前提下,用多方的数据共同训练模型,实现数据可用不可见。
字节跳动联邦学习系统架构师解浚源近期在火山引擎智能增长技术专场,以《联邦学习原理与实践》为主题,分享了联邦学习在广告投放和金融等场景中的应用模式、算法研究、软件系统及实践经验。
首先,我们简单介绍联邦学习的定义。
大数据是机器学习的石油,但数据孤岛问题普遍存在。由于用户隐私、商业机密、法律法规监管等原因,各机构无法将数据整合在一起,用来训练一个效果更好的大模型。
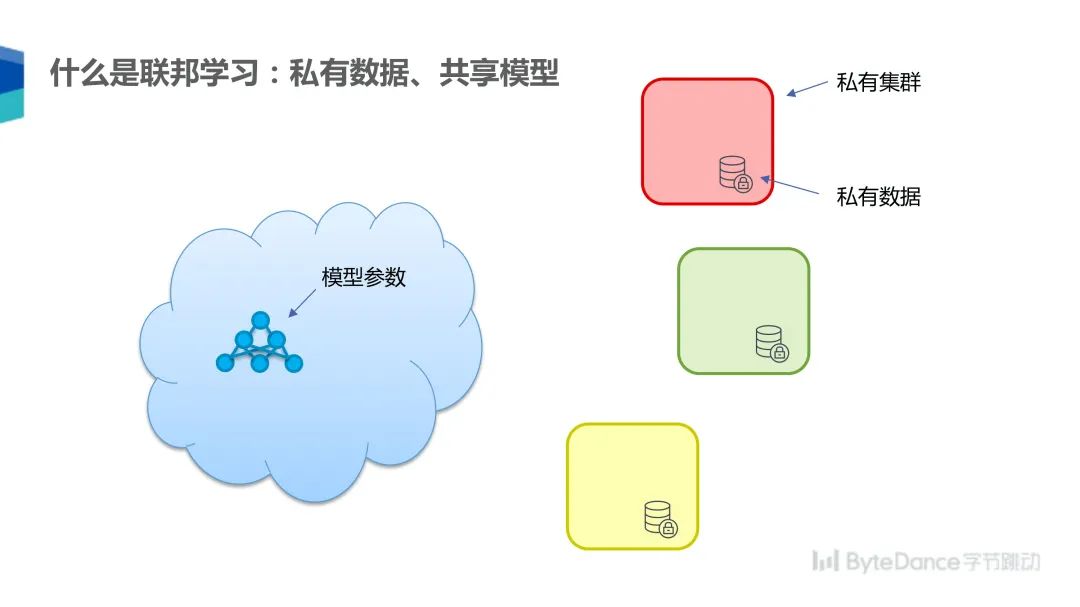
联邦学习是一种为了解决数据孤岛问题而提出的机器学习算法,目标是实现私有数据、共享模型。例如现在有三个参与方,每个参与方拥有一个私有集群和数据,这些参与方想共同训练一个模型,联邦学习就可以解决该问题。
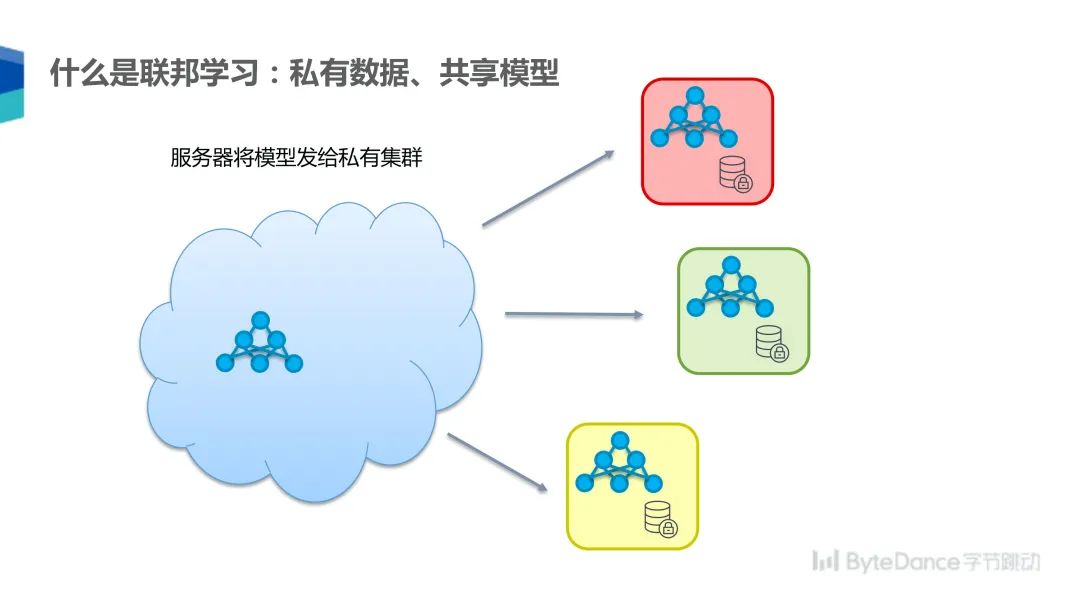
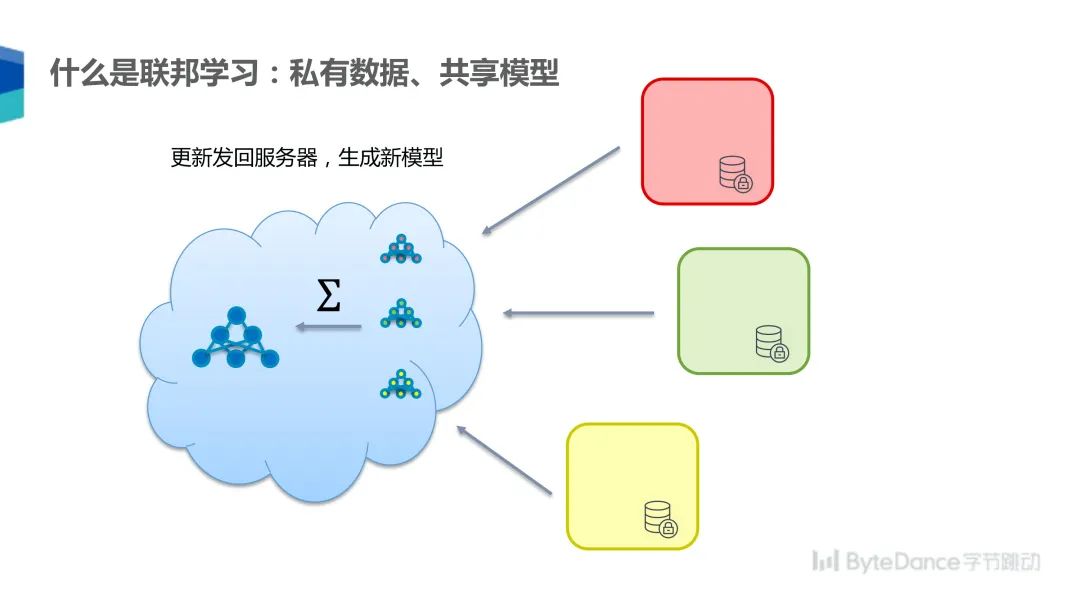
在联邦学习的模式下,可以由一个中央服务器首先将参数发送给每个参与方,然后每个参与方依据自己的私有数据更新模型,模型更新后再将梯度汇总发送至中央服务器,由服务器更新模型,然后开始下一个循环。
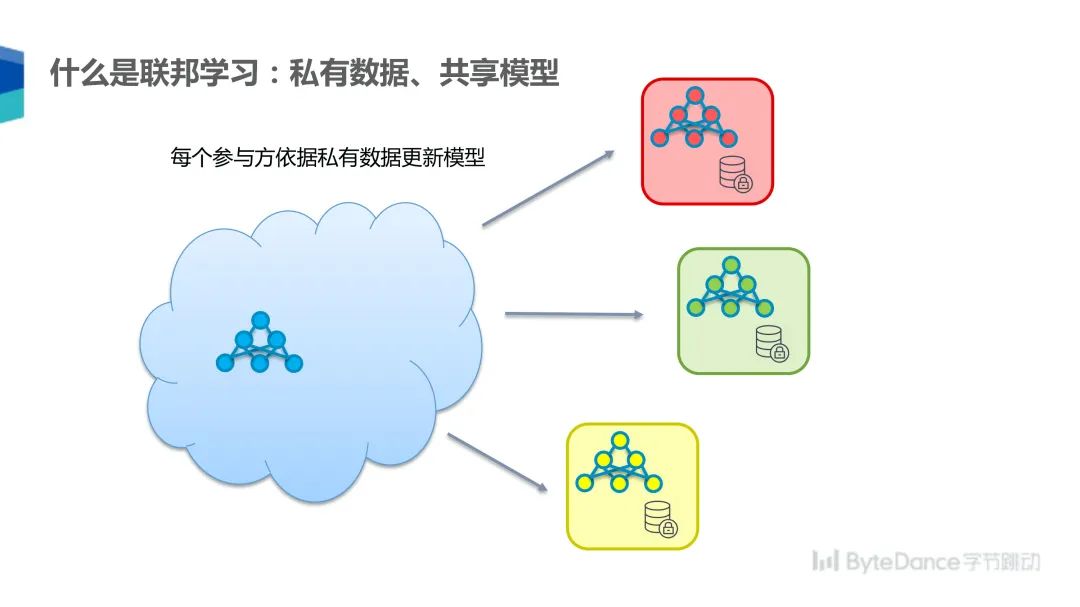
通过这样的方式,各参与方可以在不互相透露原始数据的情况下训练一个共享参数的模型。
常见的联邦学习范式有纵向联邦学习和横向联邦学习两种。纵向联邦学习有两个参与方,各自拥有同一条样本的不同特征,比如一个参与方拥有用户浏览历史,另一个参与方拥有购买历史。
在这种情况下,我们可以在两个集群各跑一部分模型,通过跨集群的方式交换中间结果,来达到训练一个模型的效果,这与机器学习中模型并行的训练方式类似。
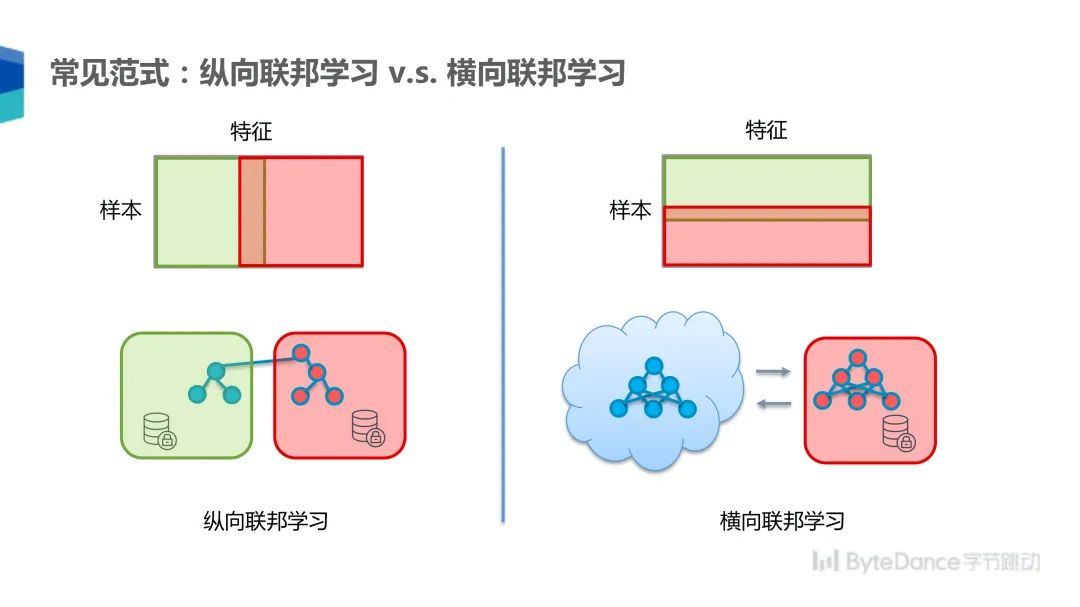
横向联邦学习是两个参与方拥有不同样本的相同特征,比如两个参与方都拥有用户的年龄、性别等,但是用户并不相同。在这种模式下,每个参与方都可以拥有整个模型,但是各自用不同的数据更新模型,最终汇总模型的梯度来训练模型,这与分布式机器学习中的模型数据并行训练方式类似。
如果探究联邦学习的历史,其经历了大概 3 到 5 年的发展。起初是 2015 年,Privacy-Preserving Deep Learning 这样的概念被提出,而后谷歌的 McMahan 提出若干深度学习方面的训练和应用模式。2018 年,微众发布联邦学习白皮书。
究其本质,联邦学习最重要的就是保护数据的可用而不可见,也就是数据的隐私保护,其研究有如下方面:一是基于差分隐私的数据保护;二是基于秘密共享的加密计算方法;三是基于同态加密的加密计算方法。
如下图,第一个场景是联邦学习在深度转化广告投放领域的应用。在广告投放场景下,媒体侧的流程是用户发起请求,媒体通过模型预测用户最可能感兴趣的广告,并将它展示给用户,用户一旦点击广告就会跳到一个落地页,这个落地页会导向广告主侧的购物网站。
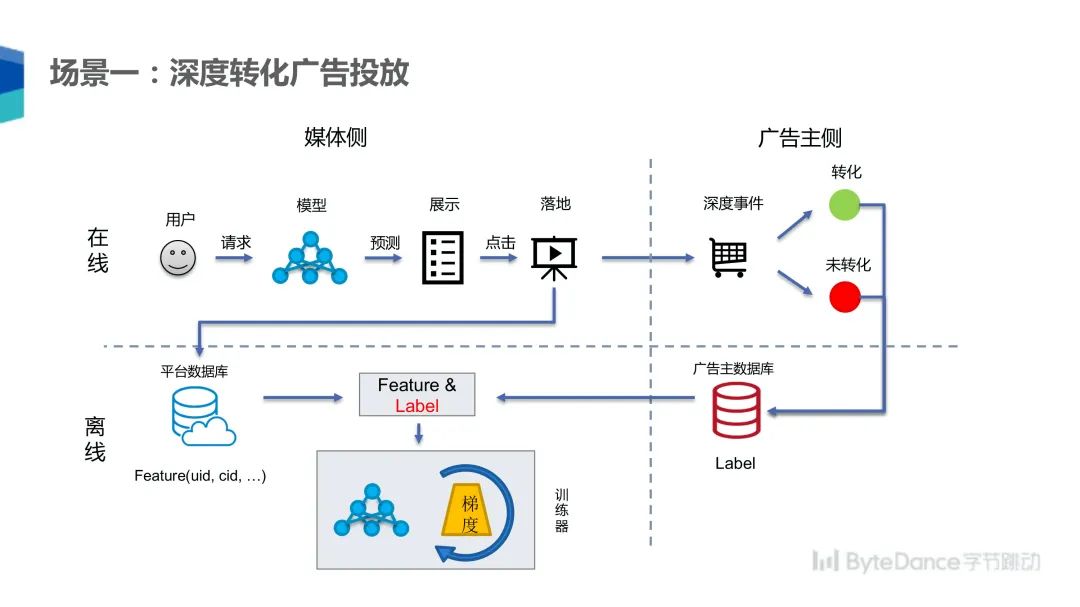
对广告主而言,在这个过程中发生的深度事件为用户是否转化。以电商场景为例,转化指的是用户购买了产品,而未转化就是指用户没有购买行为,广告主会将转化事件记录到数据库里面,媒体侧也会把这些信息记录到数据库里面。在该领域的传统做法是广告主将标签返回到媒体这一侧,然后媒体组合数据和标签用以训练模型,使用该模型知道投放优化效果。
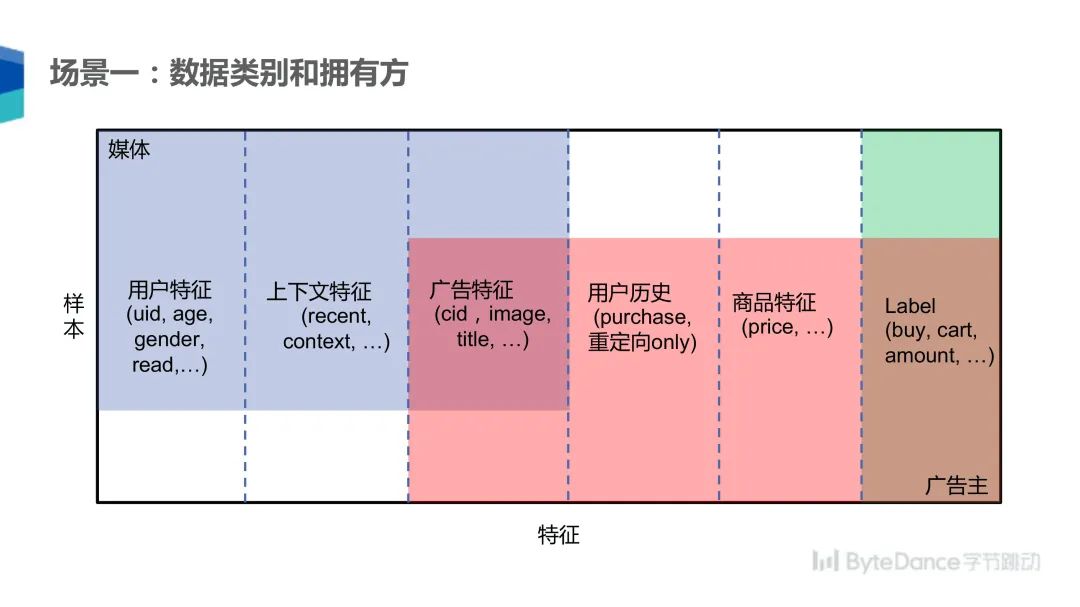
在这个场景下,媒体和广告主分别拥有点击样本的不同信息,比如媒体侧拥有用户的特征、年龄、性别,上下文特征(用户点击该广告前后看了哪些文章,点击发生的时间及用户所处位置);双方共有的信息是广告相关的特征,比如广告图片、标题等;广告主拥有的是用户历史特征,比如用户以前在该广告主处购买的商品,以及商品更细节的特征(商品价格、商品评论),广告主不会将这些信息同步到媒体侧。最后是深度事件,用户是否确实发生购买行为还是仅将商品添加至购物车。
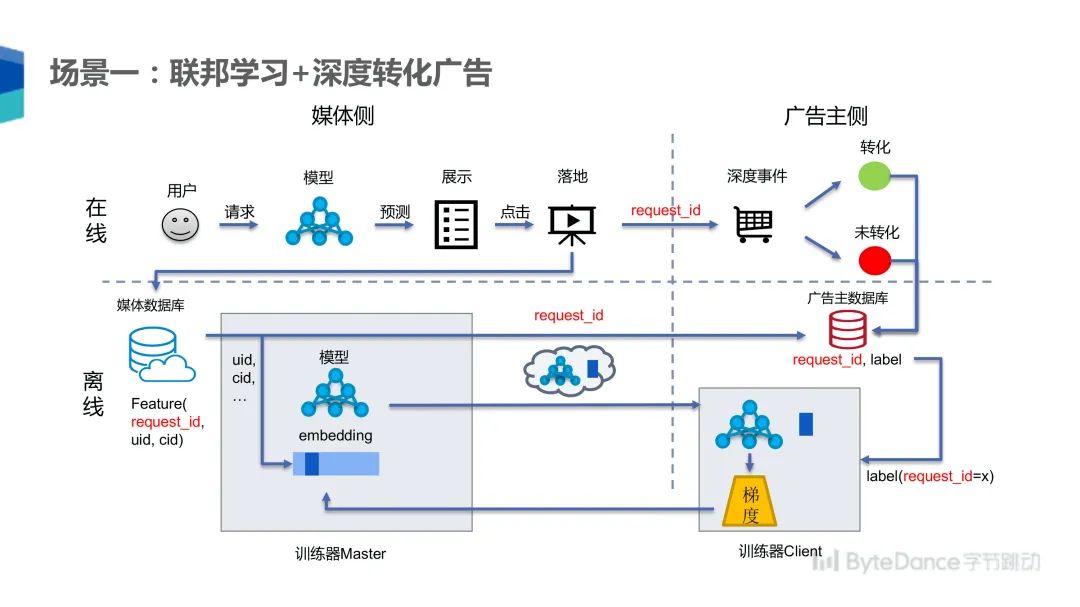
如果应用联邦学习对该场景进行优化,在线部分保持不变,但是用户的每个点击需要附加 request_id,这就唯一标识了用户的一次点击,并在媒体侧和广告主侧共用一个 ID,唯一标记这一次请求。广告主和媒体分别将 request_id 存到数据库中。离线训练时,媒体侧可以找到该条数据输入模型,最后将数据的 request_id 和输出的中间结果一起发送给广告主。广告主拿到 request_id 后就可以找到其对应的 label,然后用其计算样本的转化效果,再用该结果反向传播计算出梯度,最后将梯度发回媒体侧,两边分别用该梯度来更新模型。
第二个场景是金融信用场景。在该场景下,不同的金融机构希望可以综合多方数据提高对用户信用判断的准确度。如果各方拥有不同用户的相同特征,这样就可以采用横向联邦的方式。例如,不同的银行分别向不同的用户发放了信用卡贷款,要想建立一个更好的用户信用评估模型,多方就可以用各自拥有的不同用户特征,采用横向联邦的方式建立一个模型。
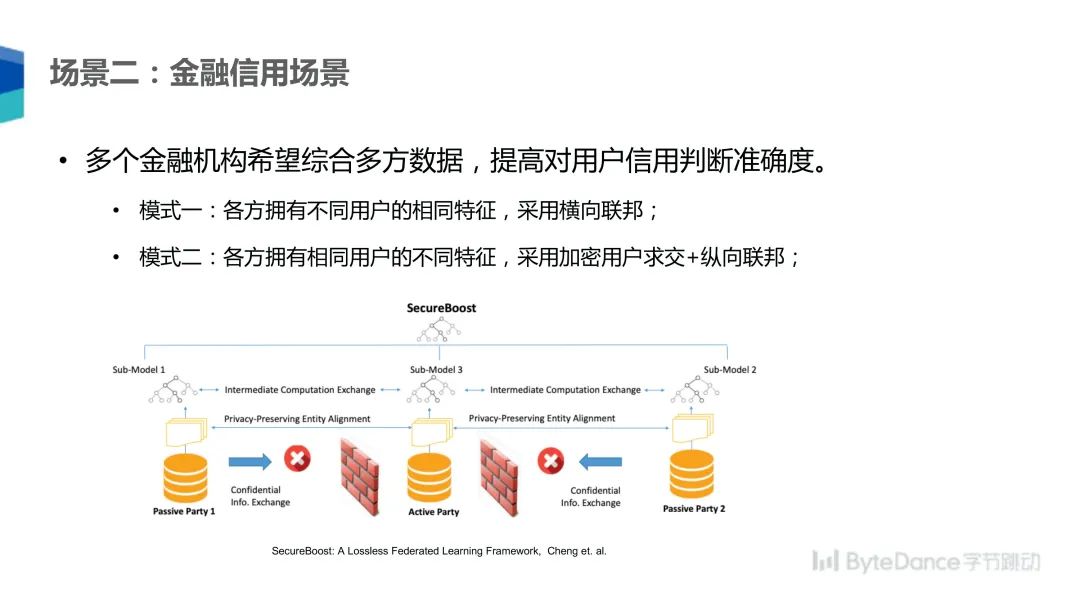
另一种情况是双方拥有相同客户的不同特征,这样就可以采用加密的纵向联邦方式。例如,一个银行和一个信贷机构分别拥有相同用户的不同特征,比如银行知道用户的存款信息,信贷机构知道用户的贷款信息,这样就可以综合训练出对用户的信用评估。考虑到金融场景的习惯和数据特点,一般是采用树模型进行建模,基于树模型的较著名的联邦学习算法是 SecureBoost,可以用多方数据在可用不可见的情况下进行加密的树模型训练。
在纵向联邦学习中,如果数据由线上请求产生,双方在存储该请求时可能出现丢失和顺序不一致的情况,这就需要训练前双方对齐数据,比如前面提到的深度转化广告投放场景,用户的点击数据在媒体侧和广告主侧是分别存储、分别落盘的,双方的落盘时间可能不一致,顺序也有可能由于双方的处理方式而打乱,这样就会产生一种对应关系,比如 request_id 0 存放在广告主的第一个位置,而 request_id 3 在媒体侧处于第一个位置。在这种情况下,我们需要把数据进行对齐,排除掉其中一方没有的数据。流式数据求交算法可以解决该问题,删掉对方没有的数据,把共有数据按照统一顺序排序。

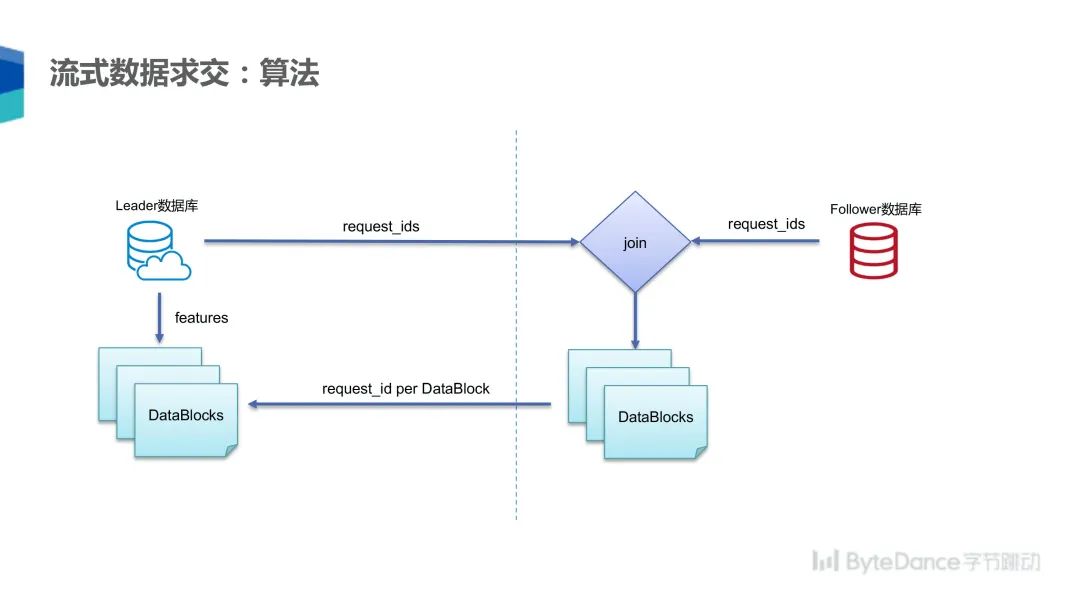
为了实现该功能,我们实现了分布式的流式数据求交算法。该算法中,一方作为 leader,另外一方作为 follower,leader 将数据按照自己的存储顺序将 request_id 顺序发送给 follower,follower 用自己的 request_id 和 leader 的 request_id 进行求交,求交结束按照 leader 的 request_id 顺序生成 DataBlocks 数据块,最后将生成的数据块发送给 leader,leader 按照数据块进行排序,并删除缺失数据,最后在两边形成相同对应的数据块。一个数据块在两方各有一半,在这个对应的数据块里,数据严格按照一致的顺序排序。需要提到是在流式数据求交的算法里面,只能使用类似于 request_id 这种不泄露用户隐私的随机数 ID 作为主键求交,如果是类似于用户的手机号这种敏感数据,就不能使用这种方式来求交。
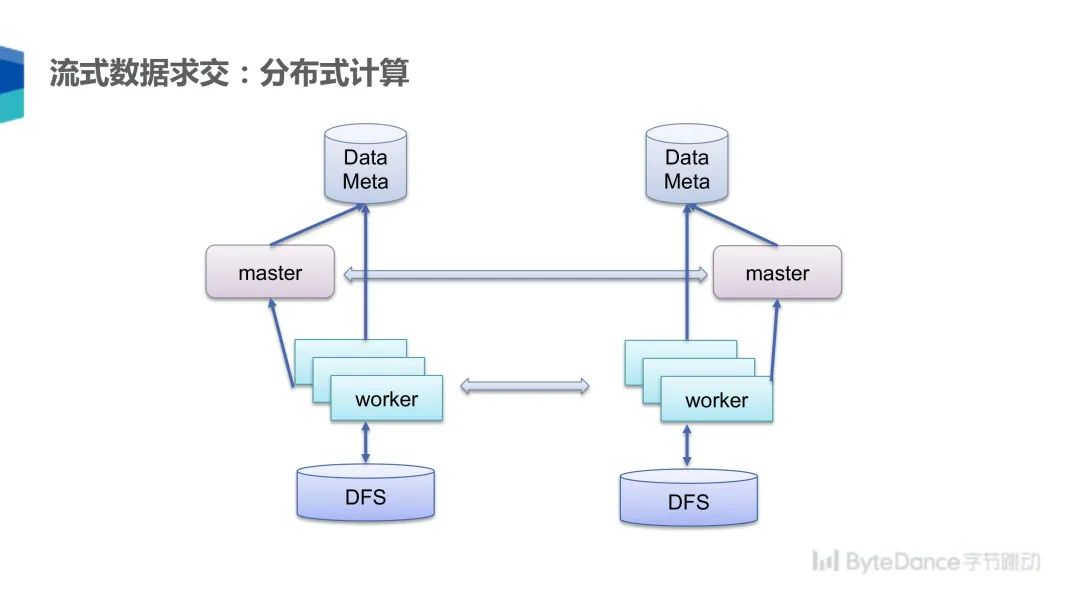
为了处理大规模数据,我们实现了一个基于分布式的流式求交算法,双方各自拉起一个 master 和 N 个 worker,worker 之间一一配对,配对后的两个 worker,其中一个作为 leader,另一个作为 follower,然后在一个分片上计算数据求交,从分布式文件系统上读取数据和写入结果。
上文提到流式数据求交只能用来处理非敏感的求交主键,但有时双方之间没有直接的跳转关系,所以不能用随机数关联双方的数据,比如在金融场景下,可能两个金融机构需要求交双方的共有用户,这种时候就需要用到 Private Set Intersection 求交方式。简单的哈希加密是无法在这种情况下保证数据安全的,如果把一个手机号的哈希值传给对方,虽然这不是明文的手机号,但是由于这个手机号的总体空间是有限的,所以另一方可以使用穷举的方法来破解。作为替代,我们使用 PSI 的方式,使用 RSA+Hash 双层加密可以有效避免撞库破解,保证求交之后的双方可以互相知道共同拥有的用户集,如果一方独有另外一方的用户,求交之后也不会泄露给对方。

具体来说,PSI 数据求交的方式需要 A 首先把自己的用户 ID 进行加盲,乘以随机数做加密,然后发送给 B,B 对加盲过的 ID 进行 RSA 加密的签名,把签名过后的数据发送回客户。
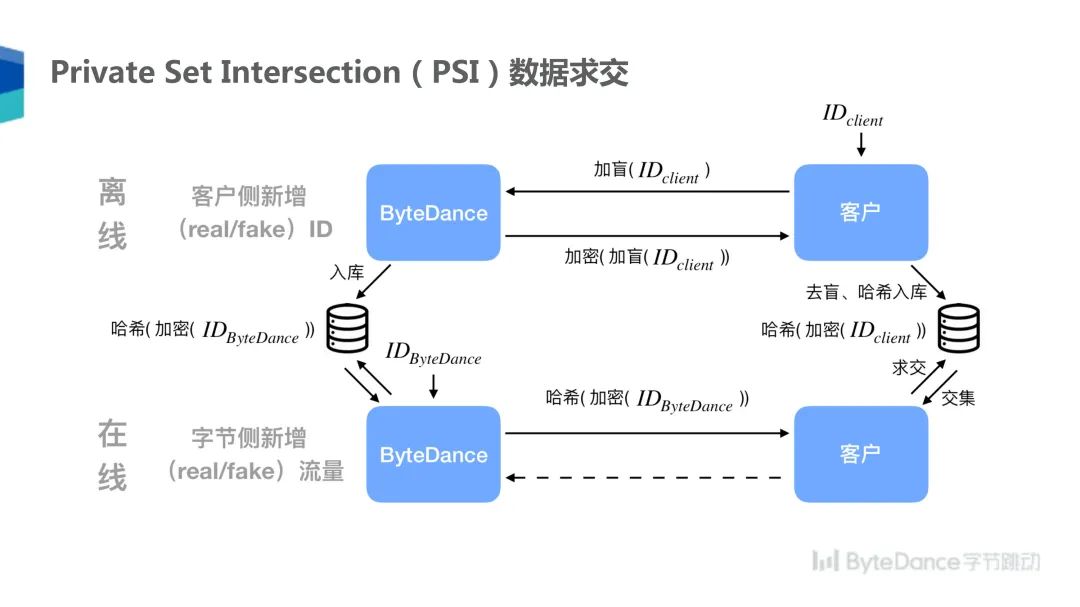
在这个过程中,B 无法得知客户 ID,因为进行了加盲处理,当然也无法解盲,但是 A 可以在加了密的 ID 上进行去盲,得到有 RSA 签名过的 ID,再在上面套一层哈希存到数据库里面。由于私钥只有 B 拥有,所以 A 得到了加密的哈希 ID 也无法进行伪造。另一方面,B 将自己的 ID 进行 RSA 签名加密,然后再哈希,并将哈希和加密过后的 ID 发送给 A,A 用这个哈希加密的 ID 可以和之前自己进行加密哈希的 ID 做匹配求交。这一过程中,A 和 B 都无法得知对方的原始 ID,同时也无法伪造一个 ID 来和对方求交,双方都可以控制用来求交的 ID 数据总量。
在纵向联邦学习中,有一方把 Label 泄露给另一方的风险,因为拥有 Label 的一方需要向另外一方发送每个样本的梯度。但是当正负样本不均衡的时候,负例的相关梯度会远远小于正例相关的梯度,因为正例很稀少,所以当正例出现的时候,模型对它的加权会比较大,它对梯度的影响也会比较大,接收方就可以根据梯度的范数判断是属于正样本还是负样本,最简单的方式是把梯度取一个范数然后排序,把超过一个阈值的所有样本认为是正例,否则就是负例。
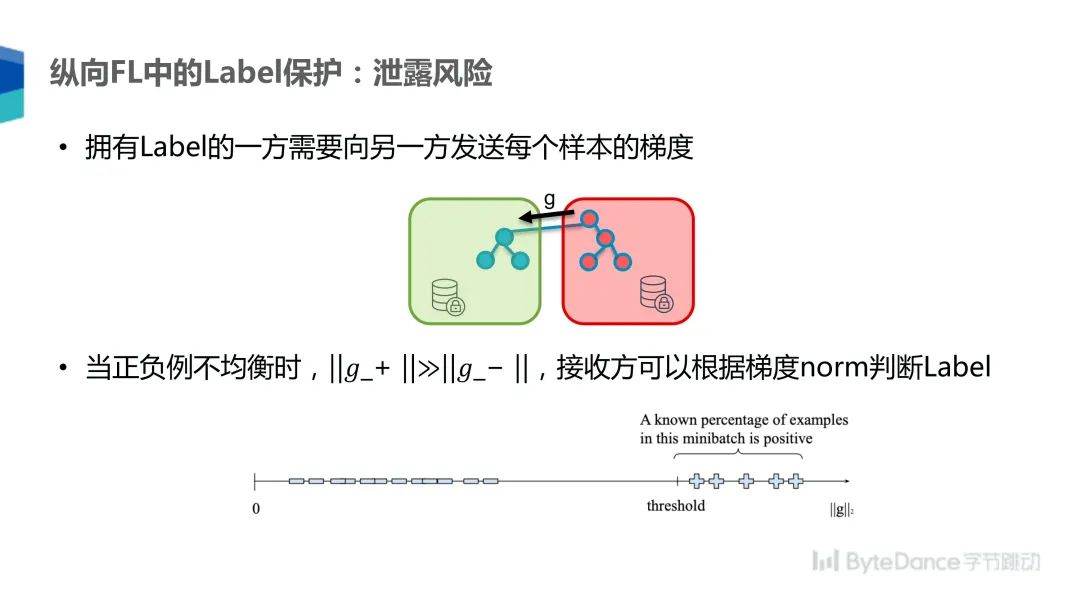
为了降低泄露风险,我们选择在梯度上叠加高斯噪声,通过最小化加入噪声的正负例之间的分布差异减少泄露。如下图,G+ 和 G- 分别是正负例对应的梯度,我们在其上加上正例和负例用的噪声,得到加过噪声的梯度,然后用 KL 散度最小化正例和负例之间的分布差异,同时为了避免噪声过大导致机器学习的效果过多受损,我们增加一个约束,分别计算正例和负例的相关性矩阵,然后约束它们的噪声大小在 P 的范围之内,这个 P 是一个可调的参数。
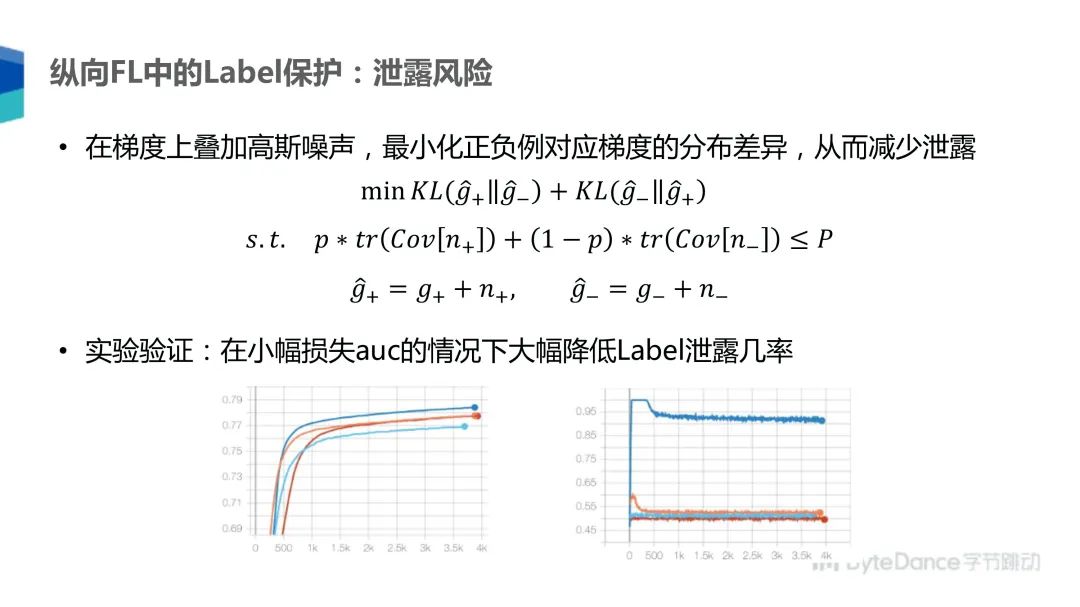
通过实验验证,我们可以在小幅损失 AUC 的情况下大幅降低泄露 Label 的机率。上图左边是在不同 P 值的情况下模型的 AUC,右边是接收梯度那一方通过梯度来判断正负例的准确度。我们可以看到蓝线是完全不进行噪声添加的训练场景,接收方可以 95% 的准确率判断 Label 是正例还是负例。其他的几条线是分别添加了不同程度的噪声,我们可以看到只要略微添加一些噪声,就可以大幅降低 Label 泄露的准确率到 50% 和 55% 中间,这就相当于泄露的机率非常低了,已经在随机猜测附近了,模型的 AUC 值下降 1% 左右。
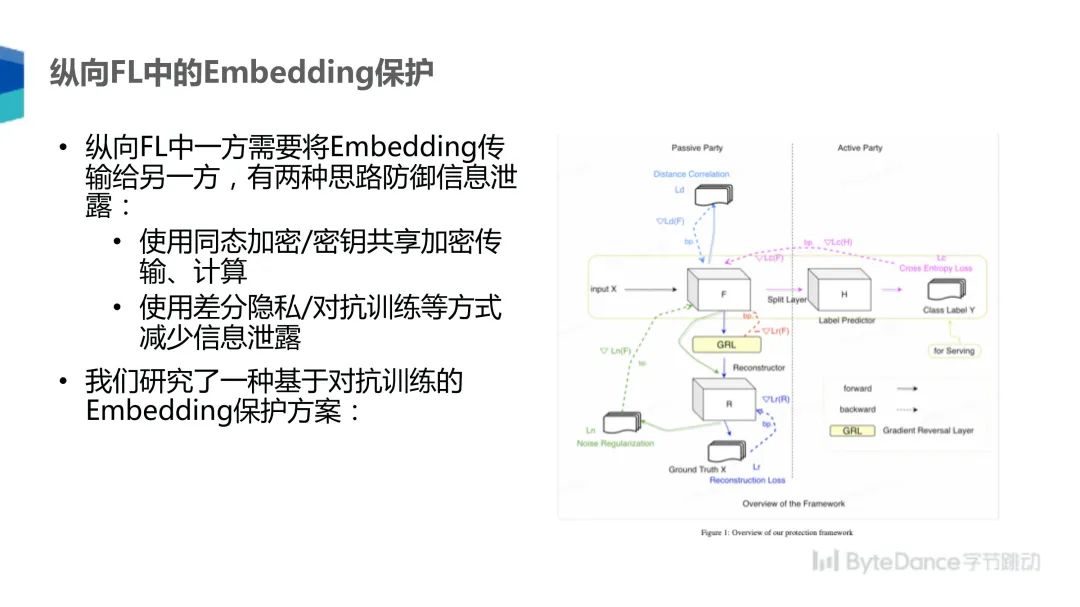
同时在纵向联邦学习中,一方还需要传 Embedding 给另一方,这也存在一些信息泄露的风险,有两种方法可以保护 Embedding 不泄露信息:一是采用同态加密或者密钥共享的方式加密传输 Embedding,来保证对方不能得到明文的 Embedding 信息;另一种方法是采用差分隐私对抗训练等方式,想办法降低 Embedding 中的信息含量,尽量减少隐私泄露。
接下来介绍我们开发的Fedlearner 联邦学习系统,目前该系统也已经在火山引擎有了大规模的 ToB 应用。
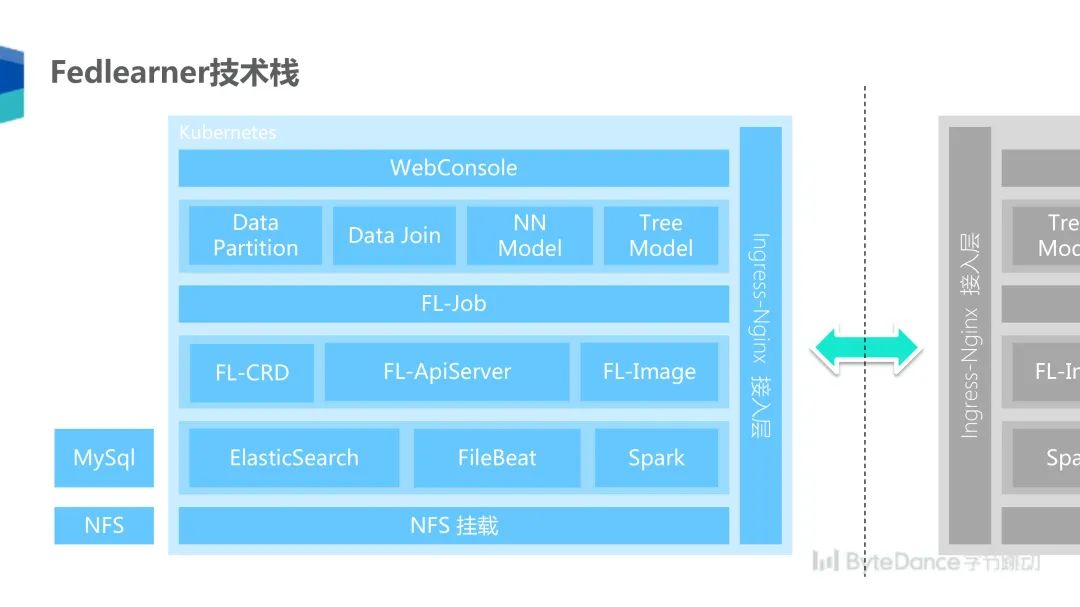
为了在客户侧部署一个我们的联邦学习系统,我们将整个系统都集成在了 Kubernetes 里面,其最底层是 NFS 挂载层,提供分布式的文件存储。之上使用 ElasticSearch、FileBeat 和 Spark 等来源处理日志和数据流。在此之上,我们实现了为联邦学习定制的任务资源管理调度器,以及用来查询任务信息的 ApiServer 和联邦学习镜像。这些基础设施完成后,我们就可以拉起联邦学习的任务了,我们支持多种任务,包括数据分片、数据求交、NN 模型、神经网络模型和树模型训练。在这之上,我们开发了一个可视化的 WebConsole 界面方便算法工程师操作,所有双方通信都经过 Ingress-Nginx 的接入层来进行加密的跨公网通信。
联邦学习的过程需要参与双方经过公网来传输数据,为了安全的经过公网通信,我们采用了 HTTPS 双向加密认证的方式来保证通信双方的身份可靠,而信息是加密并不可以被第三方监听的。同时,为了方便内部联邦学习任务的逻辑开发,我们采用了 Ingress-Nginx 来做透明加减密和域名转发。这样在 Ingress-Nginx 接入层后面的联邦学习任务可以使用普通的 gRPC 调用,透明的将信息传递到另外一个集群。
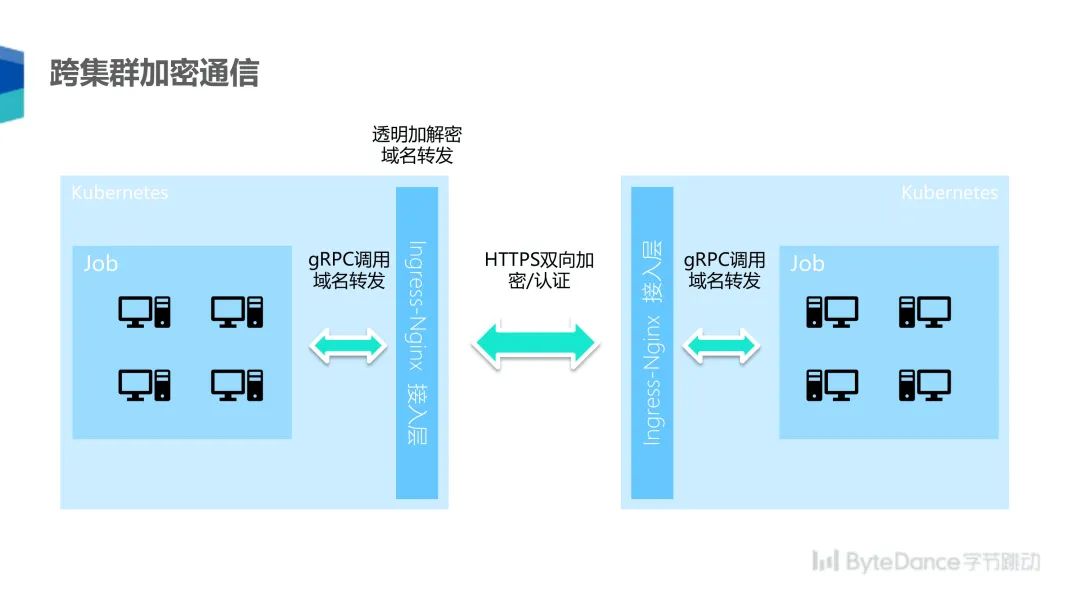
联邦学习任务的一大特点是需要双方同时各自拉起一个任务,配对以后进行通信才能开始学习任务。落地的过程中,我们发现双方要同时提交一个任务,而同时进行操作的沟通成本非常高,需要线下经过多轮协调,尤其是调优模型参数,或者是排查问题时,双方需要同时在线的沟通成本是很高的。
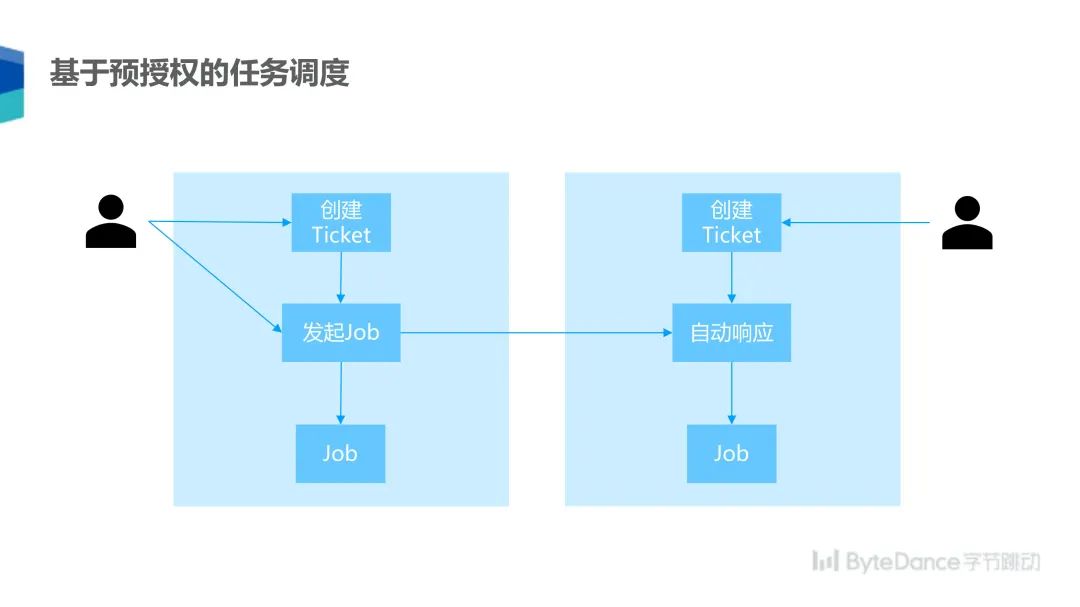
为了简化这个过程,我们开发了一套基于 Ticket 的预授权机制,使用这个机制的时候分为主动方和被动方,主动方可以创建一个 Ticket,被动方同时也创建一个 Ticket,Ticket 里面包含的信息主要是任务可以使用的数据和模型等,但不规定模型具体使用的超参数,比如学习率这些不敏感的超参数。一旦双方 Ticket 建立好,主动方就可以发起一个任务,被动方在接收到任务请求以后,系统就会自动响应拉起任务,这样双方可以各自拉起一个任务,这个过程可以重复很多次,每次拉起的任务可以使用不同的参数。这样,被动方在创建了一个 Ticket 以后,就可以不用进行操作了,只要在多轮训练结束以后查看一下结果就可以了。
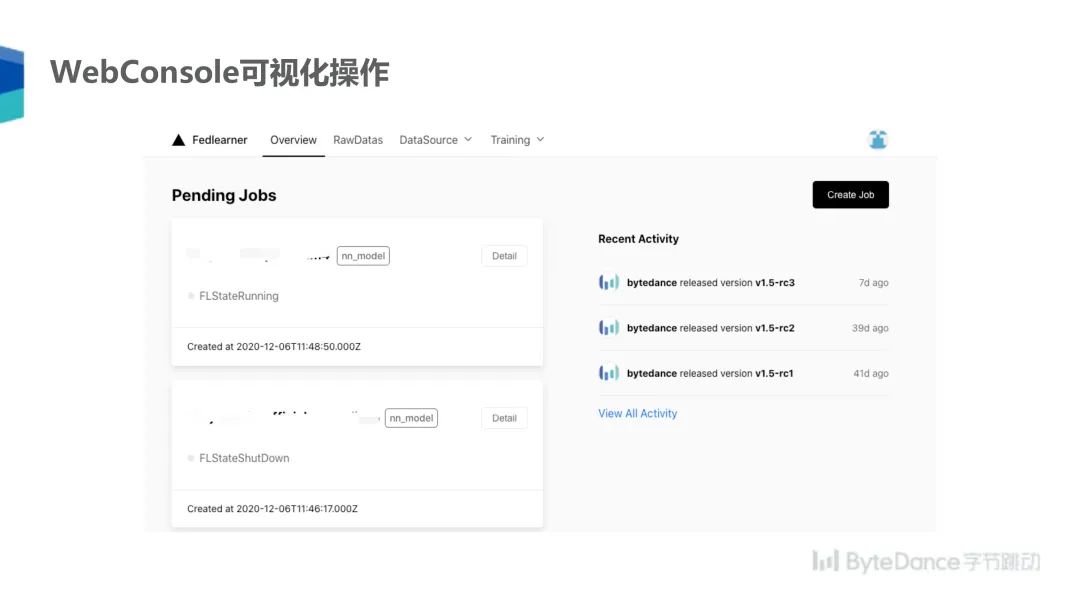
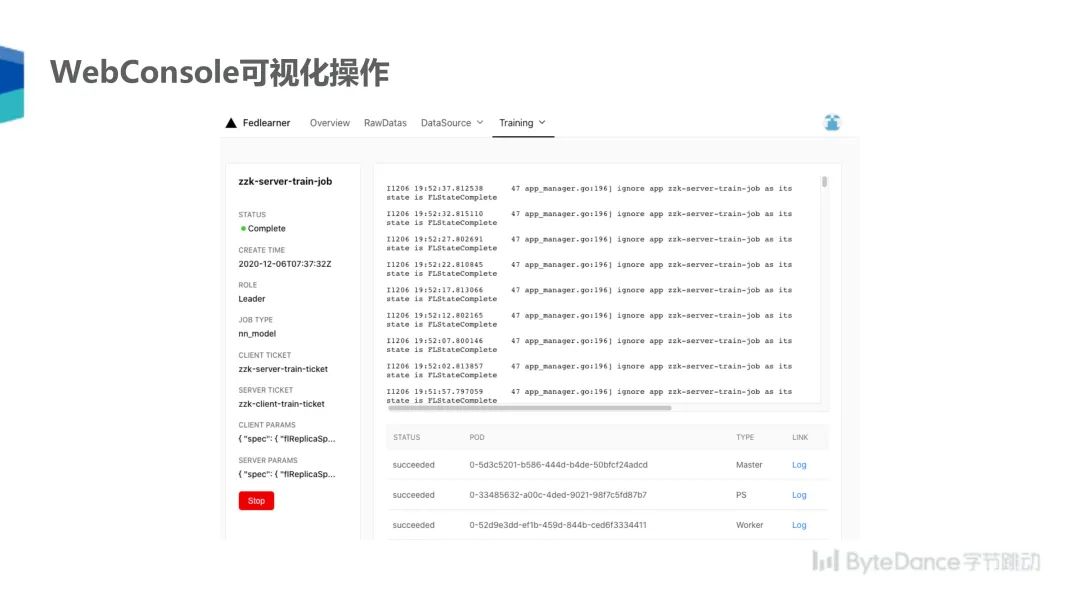
如上这些操作都可以通过 WebConsole 进行可视化,任务信息也可以经过可视化的展示,可以在网页上查看任务的效果、日志、图表等信息。
最后来聊我们下一步的发展方向。在落地过程中,我们总结出了遇到的三个痛点:

一是 Ticket 预授权机制允许自动拉起单个任务,但是联邦的流程通常需要多个任务的联动,比如上传、求交、训练均需要双方人工的参与,所以我们下一个版本会开发基于 Workflow 的授权,Workflow 就是一个包含多任务的工作流,这多个任务会自动轮换完成调度;
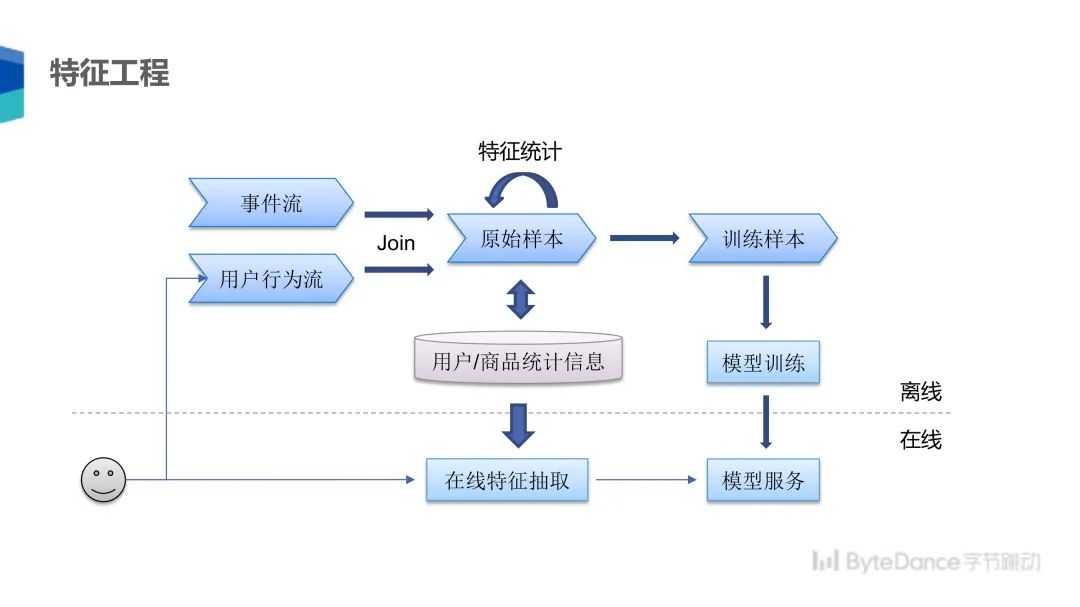
二是合作方需要先自行完成特征工程,并且以特定格式灌入系统。这对于客户的特征工程能力要求是比较高的,客户往往只能使用一些有限的特征。为解决该问题,我们会增加基于 Spark 的流式归因和特征抽取能,Fedlearner 系统可以集成式读取用户原始数据,然后自动化抽取特征,并输入到最终的模型系统里面;
三是随着合作方的增加,一对一的联邦维护成本不断提高。为了降低成本,我们会探索多方联邦,同一个行业的多个合作方可以同时训练一个模型,这样可以减少模型的数量,降低人工维护成本。
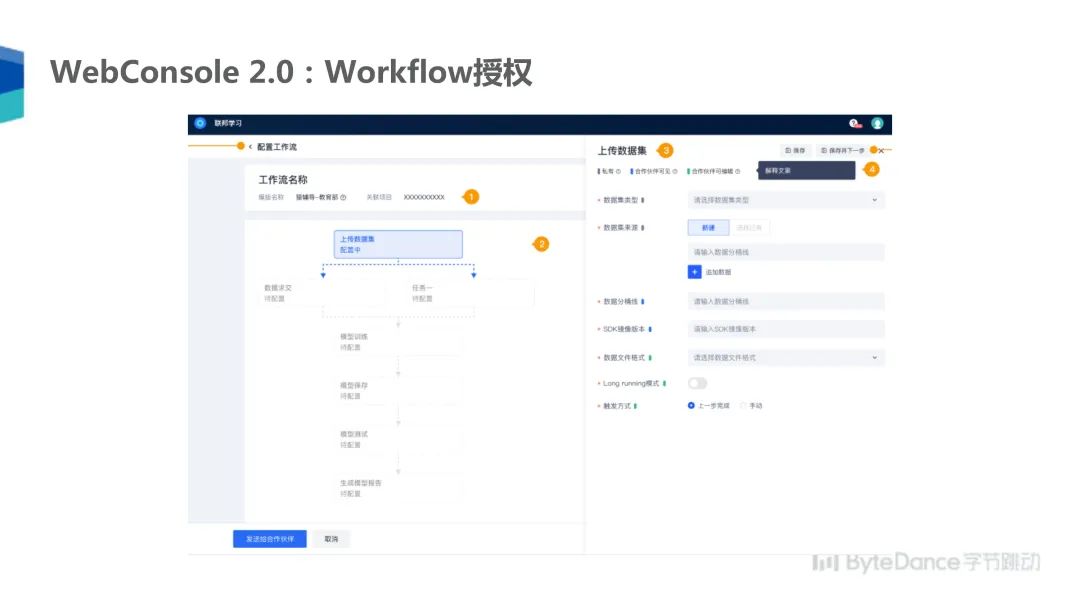
首先具体介绍 Workflow 授权,我们在下一个版本会重新设计 WebConsole 的 2.0 版本,WebConsole2.0 版本支持图形化配置工作流,可以看到工作流中包含多个任务,任务之间可以有各种依赖关系,每个任务可以有一些参数配置,用户只要配置好工作流,就可以一键运行多个任务。另一个解决方案是集成化的特征工程会基于 Spark 开发一个特征抽取系统,该系统包含归因模块、特征抽取、统计模块和模型训练模块。同时还包含在线服务的功能,用户在抽取完特征后,可以在线服务中抽取同样的特征,输入到在线服务的模型中。
最后是多方联邦,多方联邦有两种方式:横向 + 纵向;纵向 + 纵向。
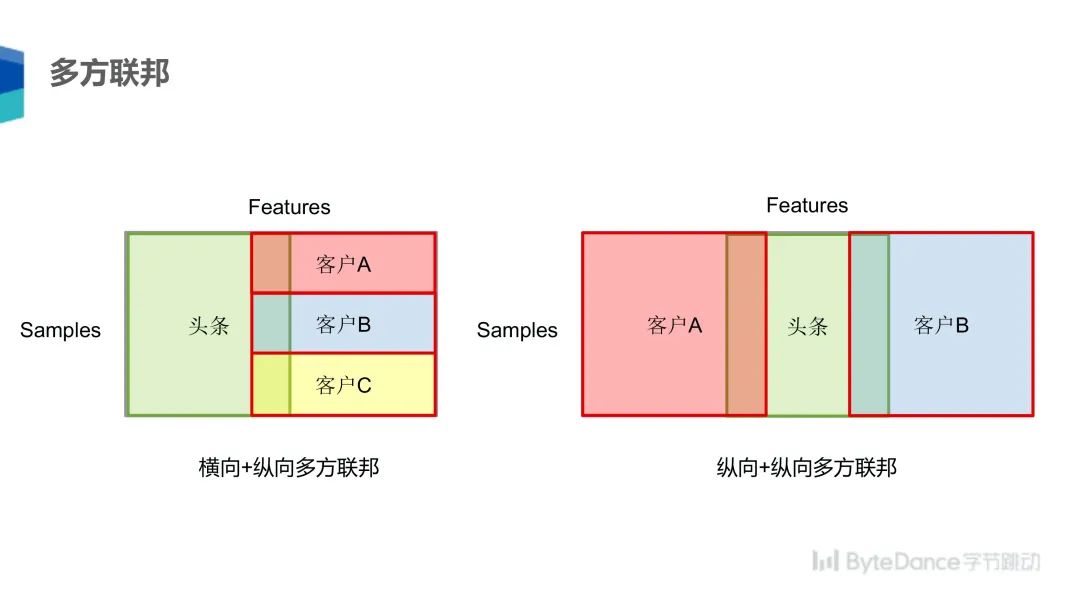
横向 + 纵向指不同参与方拥有部分重合数据的不同特征,可以共同训练一个模型;纵向 + 纵向指不同客户拥有不同的特征维度,可以采用三方纵向联邦的方式综合同一个用户的更多维度信息进行训练。