Kafka监听器无法消费消息并持久化到HBase表。
 社区干货
社区干货
9年演进史:字节跳动 10EB 级大数据存储实战
HBase,日志服务,Kafka 数据存储 - Yarn,Flink 的计算框架平台数据 - Spark,MapReduce 的计算相关数据存储![]()# **字节跳动特色的** **HDFS** **架构**在深入相关的技术细节之前,我们先看看字节跳动的 H... BookKeeper 在大规模多节点数据同步上表现得更稳定可靠)。Name Node 负责存储整个 HDFS 集群的元数据信息,是整个系统的大脑。一旦故障,整个集群都会陷入不可用状态。因此 Name Node 有一套基于 ZKFC 的主从热备的...
基于火山引擎 EMR 构建企业级数据湖仓
流引擎 - Flink:流计算逐步扩大市场份额 - Kafka SQL:基于 Kafka 实现实时化分析 - Streaming Database:Materialize 和 RisingWave 在开发的一种产品形态,效果类似于 Data Bricks 的 Data ... **持久化的 History Server 服务**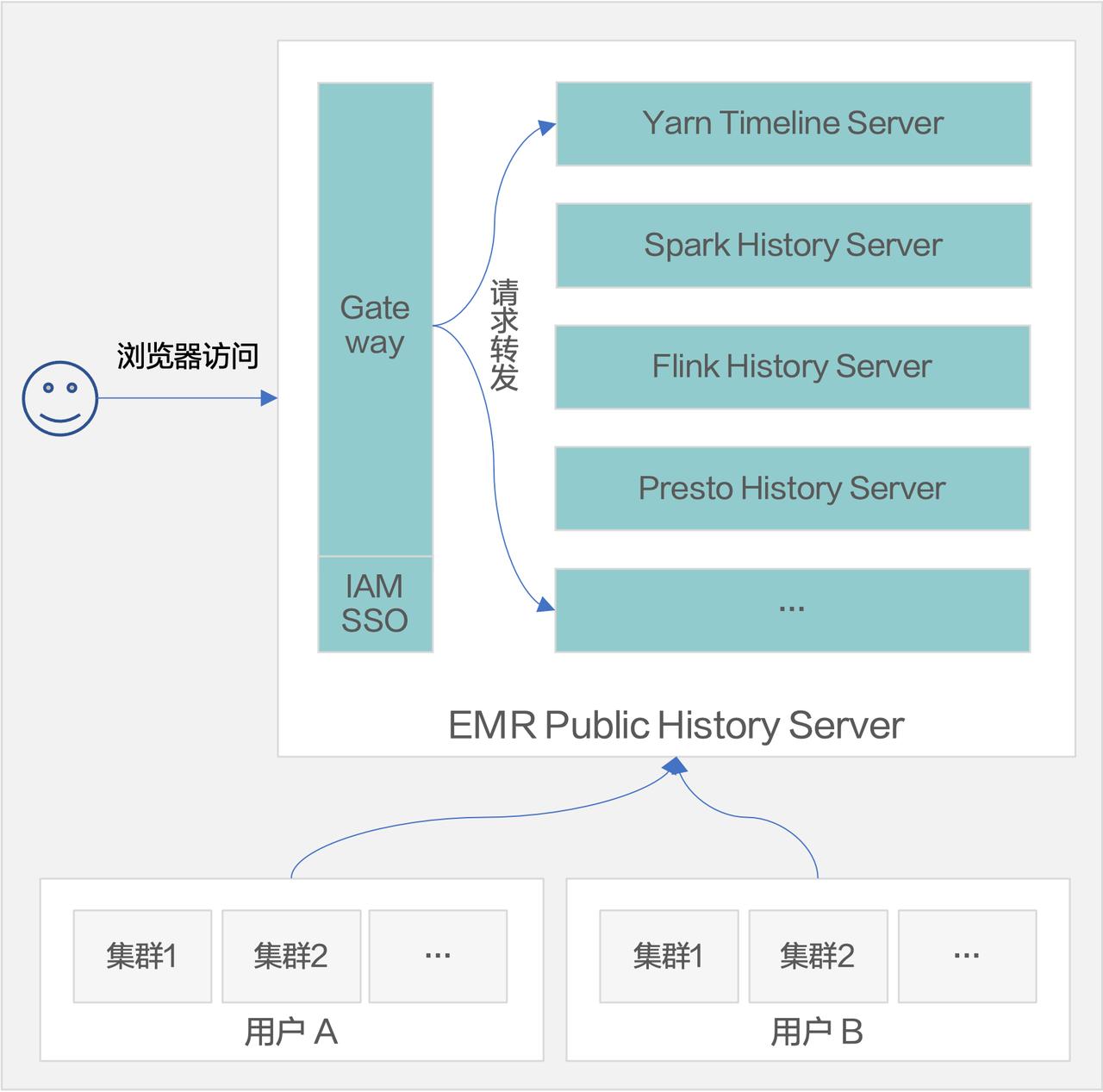我们把 YARN、Spark、Flink、Presto 这几种 ...
20000字详解大厂实时数仓建设 | 社区征文
同一份表,会使用不同的方式进行存储。比如常见的情况下,明细数据或者汇总数据都会存在 Kafka 里面,但是像城市、渠道等维度信息需要借助 Hbase,mysql 或者其他 KV 存储等数据库来进行存储。接下来,根据顺风车实时... 该层的数据除了存储在消息队列 Kafka 中,通常也会把数据实时写入 Druid 数据库中,供查询明细数据和作为简单汇总数据的加工数据源。命名规范:DWD 层的表命名使用英文小写字母,单词之间用下划线分开,总长度不能超过...
「火山引擎」数智平台 VeDI 数据中台产品双月刊 VOL.07
**【私有化-功能迭代更新】** - 离线数据集成支持 Gbase8S2LAS、OceanBase2LAS、实时集成 Kafka2LAS - 数据开发支持 LAS Flink 任务类型 - 指标平台支持 HBase 数据源创建模型绑定 - ... 集群管理:提供图形化的集群部署能力;创建支持预置自定义参数。支持集群重启;查看重启日志:查看服务重启的进度、当前环节状态、日志信息重启下线。对集群软件资源进行监控,保证平台运行效率软硬件资源日...
 特惠活动
特惠活动
 Kafka监听器无法消费消息并持久化到HBase表。-优选内容
Kafka监听器无法消费消息并持久化到HBase表。-优选内容
 Kafka监听器无法消费消息并持久化到HBase表。-相关内容
Kafka监听器无法消费消息并持久化到HBase表。-相关内容
EMR-3.10.0发布说明
环境信息版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.10.13 Java ByteOpenJDK 1.8.0_352 系统环境应用程序版本 Hadoop集群 Flink集群 Kafka集群 Pulsar集群 Presto集群 Trino集群 HBase集群 ... kafka_broker 3.2.4 Kafka中的消息处理节点。 hbase_master 2.5.2 适用于负责协调区域和执行管理命令的 HBase 集群的服务。 hbase_regionserver 2.5.2 用于服务于一个或多个 HBase 区域的服务。 hbase_client 2.5...
EMR-3.6.0 版本说明
环境信息 系统环境版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.10.13 Java ByteOpenJDK 1.8.0_352 应用程序版本 Hadoop集群 Flink集群 Kafka集群 HBase集群 StarRocks集群 ClickHouse集群 Op... kafka_broker 3.2.4 Kafka中的消息处理节点。 hbase_master 2.3.7 适用于负责协调区域和执行管理命令的 HBase 集群的服务。 hbase_regionserver 2.3.7 用于服务于一个或多个 HBase 区域的服务。 hbase_client 2.3...
EMR-3.9.0发布说明
环境信息版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.10.13 Java ByteOpenJDK 1.8.0_352 系统环境应用程序版本 Hadoop集群 Flink集群 Kafka集群 Pulsar集群 Presto集群 Trino集群 HBase集群 ... kafka_broker 3.2.4 Kafka中的消息处理节点。 hbase_master 2.3.7 适用于负责协调区域和执行管理命令的 HBase 集群的服务。 hbase_regionserver 2.3.7 用于服务于一个或多个 HBase 区域的服务。 hbase_client 2.3...
EMR-3.6.2 版本说明
环境信息 系统环境版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.10.13 Java ByteOpenJDK 1.8.0_352 应用程序版本 Hadoop集群 Flink集群 Kafka集群 HBase集群 StarRocks集群 ClickHouse集群 Op... kafka_broker 3.2.4 Kafka中的消息处理节点。 hbase_master 2.3.7 适用于负责协调区域和执行管理命令的 HBase 集群的服务。 hbase_regionserver 2.3.7 用于服务于一个或多个 HBase 区域的服务。 hbase_client 2.3...
EMR-3.0.0版本说明
环境信息 系统环境版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.7.3 Java ByteOpenJDK 1.8.0_302 应用程序版本 Hadoop集群 Flink集群 Kafka集群 Presto集群 Trino集群 HBase集群 OpenSearch集... Doris升级到 1.1.1: 向量化执行引擎支持 ODBC Sink; 增加简易版 MemTracker; 支持在 Page Cache 中缓存解压后的数据; 修复某些查询不能回退到非向量化引擎并导致 BE Core的问题; 修复 Compaction 不能正常工作...
20000字详解大厂实时数仓建设 | 社区征文
同一份表,会使用不同的方式进行存储。比如常见的情况下,明细数据或者汇总数据都会存在 Kafka 里面,但是像城市、渠道等维度信息需要借助 Hbase,mysql 或者其他 KV 存储等数据库来进行存储。接下来,根据顺风车实时... 该层的数据除了存储在消息队列 Kafka 中,通常也会把数据实时写入 Druid 数据库中,供查询明细数据和作为简单汇总数据的加工数据源。命名规范:DWD 层的表命名使用英文小写字母,单词之间用下划线分开,总长度不能超过...
EMR-3.0.1版本说明
环境信息 系统环境版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.7.3 Java ByteOpenJDK 1.8.0_302 应用程序版本 Hadoop 集群 Flink 集群 Kafka 集群 Presto 集群 Trino 集群 HBase 集群 OpenSe... kafka_broker 2.3 Kafka 中的消息处理节点。 hbase_master 2.3.7 适用于负责协调区域和执行管理命令的 HBase 集群的服务。 hbase_regionserver 2.3.7 用于服务于一个或多个 HBase 区域的服务。 hbase_client 2.3....
「火山引擎」数智平台 VeDI 数据中台产品双月刊 VOL.07
**【私有化-功能迭代更新】** - 离线数据集成支持 Gbase8S2LAS、OceanBase2LAS、实时集成 Kafka2LAS - 数据开发支持 LAS Flink 任务类型 - 指标平台支持 HBase 数据源创建模型绑定 - ... 集群管理:提供图形化的集群部署能力;创建支持预置自定义参数。支持集群重启;查看重启日志:查看服务重启的进度、当前环节状态、日志信息重启下线。对集群软件资源进行监控,保证平台运行效率软硬件资源日...
EMR-3.1.0版本说明
环境信息 系统环境版本 环境 OS veLinux (Debian 10兼容版) Python2 2.7.16 Python3 3.7.3 Java ByteOpenJDK 1.8.0_302 应用程序版本 Hadoop集群 Flink集群 Kafka集群 Presto集群 Trino集群 HBase集群 OpenSearch集... kafka_broker 2.3 Kafka中的消息处理节点。 hbase_master 2.3.7 适用于负责协调区域和执行管理命令的 HBase 集群的服务。 hbase_regionserver 2.3.7 用于服务于一个或多个 HBase 区域的服务。 hbase_client 2.3.7...
