Kafka中的动态流拓扑架构
 社区干货
社区干货
消息队列选型之 Kafka vs RabbitMQ
在面对众多的消息队列时,我们往往会陷入选择的困境:“消息队列那么多,该怎么选啊?Kafka 和 RabbitMQ 比较好用,用哪个更好呢?”想必大家也曾有过类似的疑问。对此本文将在接下来的内容中以 Kafka 和 RabbitMQ 为例分... 数据结构,编程语言一般都内置(内存中的)队列实现,可以作为进程间通讯(IPC)的方法。使用队列最常见的场景就是生产者/消费者模式:生产者生产消息放到队列中,消费者从队列里面获取消息消费。典型架构如下图所示:...
字节跳动新一代云原生消息队列实践
相较于 Kafka 省去了 ISR 相关的管理。Controller 可以更加专注地关注集群整体流量均衡及故障检测。在 BMQ 中用户所有请求都会由 Proxy 接入,因此 BMQ 的 Metadata 中的 ‘Broker’ 信息实际上填写的是 BMQ 中 Proxy 的信息,客户端根据 Metadata 请求将生产和消费等请求发送到对应的 Proxy,再由 Proxy 处理或转发。这样的架构有助于 BMQ 做更多的容错工作。例如在 Broker 重启时,Proxy 可以感知到相关错误并进行 **退避重试...
字节跳动基于Apache Atlas的近实时消息同步能力优化 | 社区征文
文 | **洪剑**、**大滨** 来自字节跳动数据平台开发套件团队# 背景## 动机字节数据中台DataLeap的Data Catalog系统基于Apache Atlas搭建,其中Atlas通过Kafka获取外部系统的元数据变更消息。在开源版本中,每台... 对于流式处理的语义有较好的支持,也满足我们对于轻量的诉求。最终没有采用的主要考虑点是两个:- 对于Offset的维护不够灵活:我们的场景不能使用自动提交(会丢消息),而对于同一个Partition中的数据又要求一定程度...
一种在数据量比较大、字段变化频繁场景下的大数据架构设计方案|社区征文
整体流程如图1从源系统同步过来的数据落到ODS层,但是要注意采集数据时需要能捕获到源系统表结构的变更,可以采用Flink CDC等。ODS层的数据落到Kakfa中,设置一个较长的保存周期。kafka直...
 特惠活动
特惠活动
 Kafka中的动态流拓扑架构-优选内容
Kafka中的动态流拓扑架构-优选内容
 Kafka中的动态流拓扑架构-相关内容
Kafka中的动态流拓扑架构-相关内容
字节跳动基于Apache Atlas的近实时消息同步能力优化 | 社区征文
文 | **洪剑**、**大滨** 来自字节跳动数据平台开发套件团队# 背景## 动机字节数据中台DataLeap的Data Catalog系统基于Apache Atlas搭建,其中Atlas通过Kafka获取外部系统的元数据变更消息。在开源版本中,每台... 对于流式处理的语义有较好的支持,也满足我们对于轻量的诉求。最终没有采用的主要考虑点是两个:- 对于Offset的维护不够灵活:我们的场景不能使用自动提交(会丢消息),而对于同一个Partition中的数据又要求一定程度...
读取 Kafka 数据写入 TOS 再映射到 LAS 外表
Flink 是一个兼容 Apache Flink 的全托管流式计算平台,支持对海量实时数据的高效处理。LAS 是湖仓一体架构的 Serverless 数据平台,提供海量数据存储、管理、计算和交互分析功能。本文通过一个示例场景模拟 Flink 与 LAS 的联动,从而体验跨源查询分析、元数据自动发现等能力。 场景介绍本文模拟场景主要实现:读取消息队列 Kafka 数据写入对象存储 TOS,并映射为湖仓一体分析服务 LAS 外表进行数据分析。在 Flink 控制台通过开发 Fl...
一种在数据量比较大、字段变化频繁场景下的大数据架构设计方案|社区征文
整体流程如图1从源系统同步过来的数据落到ODS层,但是要注意采集数据时需要能捕获到源系统表结构的变更,可以采用Flink CDC等。ODS层的数据落到Kakfa中,设置一个较长的保存周期。kafka直...
EMR-3.0.1版本说明
环境信息 系统环境版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.7.3 Java ByteOpenJDK 1.8.0_302 应用程序版本 Hadoop 集群 Flink 集群 Kafka 集群 Presto 集群 Trino 集群 HBase 集群 OpenSe... Kafka 网络拓扑优化,当开启 EIP 后,Kafka 组件的内部通信仍然使用内网,提升集群性能和降低成本。 【组件】ClickHouse 支持 TOS 存储。对二进制包进行优化,减少不必要的 Warn 提示。 【组件】AirFlow 升级至2.4.2...
字节跳动新一代云原生消息队列实践
相较于 Kafka 省去了 ISR 相关的管理。Controller 可以更加专注地关注集群整体流量均衡及故障检测。在 BMQ 中用户所有请求都会由 Proxy 接入,因此 BMQ 的 Metadata 中的 ‘Broker’ 信息实际上填写的是 BMQ 中 Proxy 的信息,客户端根据 Metadata 请求将生产和消费等请求发送到对应的 Proxy,再由 Proxy 处理或转发。这样的架构有助于 BMQ 做更多的容错工作。例如在 Broker 重启时,Proxy 可以感知到相关错误并进行 **退避重试...
干货|字节跳动流式数据集成基于Flink Checkpoint两阶段提交的实践和优化(2)
> > > 字节跳动开发套件数据集成团队(DTS ,Data Transmission Service)在字节跳动内基于 Flink 实现了流批一体的数据集成服务。其中一个典型场景是 Kafka/ByteMQ/RocketMQ -> HDFS/Hive 。Kafka/ByteMQ/RocketMQ... HDFS 表示 HDFS在现有架构下无法保证删除的幂等性。 参考 DDIA (Designing Data-Intensive Applications) 第 9 章中关于因果关系的定义:因果关系对事件施加了一种顺序——因在果之前。对应于MQ dump 流程...
一文了解字节跳动消息队列演进之路
生产者负责写消息到 Kafka;消费者负责读取消息。从架构上来看 Kafka 的架构非常简单,只有 Broker 组件负责所有的读写操作。在 Kafka 集群中,一个 Broker 节点会被选举为控制器(Controller)监管集群的状态,并负... 例如上图中的 Partition 3 中,Leader 所在的 Broker 挂掉之后,Controller 便会把 Leader 角色切换到 Broker B 接管流量以保障服务的正常运行。需要注意的是,这种情况下是否会丢失数据,取决于用户写入参数和集群的配...
干货|8000字长文,深度介绍Flink在字节跳动数据流的实践
这个场景的**另一个需求就是ETL规则的动态更新**。#### 2、数据分流场景目前,抖音业务的**埋点Topic晚高峰流量超过1亿/秒**,而下游电商、直播、短视频等不同业务的实时数仓关注的埋点范围实际上都只是其中的一... **数据流ETL链路也在2018年全面迁移到了PyFlink,进入了流式计算的新时代。**- **第二个阶段是2018至2020年**随着流量的进一步上涨,PyFlink和Kafka的性能瓶颈、以及JSON数据格式带来的性能和数据质量问题都一...
字节跳动大规模埋点数据治理最佳实践
平台已经跟下游使用流量数据的应用进行打通,用户可以订阅数据。- **链路根基**:即自研的动态实时计算平台,也是整个平台的核心技术,它能够支撑起字节跳动万亿+的实时数据的处理。## 埋点内容解决方案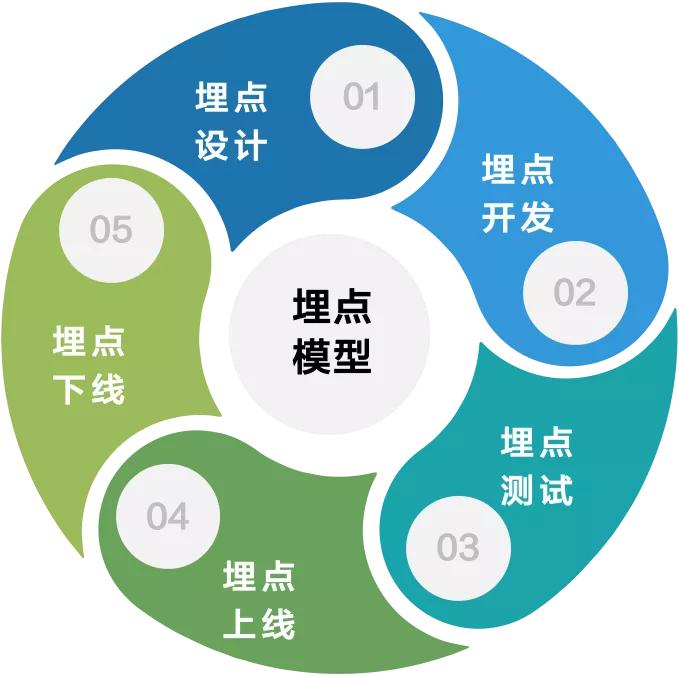埋点内容主要管理埋点生命周期,这里要着重强调一下上图中心位置的**埋点模型**其实非常重要...
