存储过程第二次运行更快。
 社区干货
社区干货
RocketMQ 存储机制浅析
若在没有启动 Broker 的情况下,发现这个文件是存在的,则说明之前 Broker 的关闭是非正常关闭 ├── checkpoint // 其中存储着 commitlog、consumequeue、index 文件的最后刷盘时间戳 ├──... ├── config // 存放着 Broker 运行期间的一些配置数据 │ ├── consumerFilter.json // 消费者的过滤器 │ ├── consumerFilter.json.bak │ ├── consumerOffse...
云原生环境下的日志采集、存储、分析实践
服务端日志又包括业务的运行/运维日志以及业务使用的云产品产生的日志。要管理诸多类型的日志,就需要一套统一的日志系统,对日志进行采集、加工、存储、查询、分析、可视化、告警以及消费投递,将日志的生命周期进行... 火山引擎早期为了快速上线业务,各团队基于开源项目搭建了自己的日志系统,以满足基本的日志查询需求,例如使用典型的开源日志平台 Filebeat+Logstash+ES+Kibana 的方案。但是在使用过程中,我们发现了开源日志系统的...
云原生环境下的日志采集、存储、分析实践
服务端日志又包括业务的运行/运维日志以及业务使用的云产品产生的日志。要管理诸多类型的日志,就需要一套统一的日志系统,对日志进行采集、加工、存储、查询、分析、可视化、告警以及消费投递,将日志的生命周期进行... 火山引擎早期为了快速上线业务,各团队基于开源项目搭建了自己的日志系统,以满足基本的日志查询需求,例如使用典型的开源日志平台 **Filebeat+Logstash+ES+Kibana** 的方案。但是在使用过程中,我们发现了开源日志系...
2022技术盘点之平台云原生架构演进之道|社区征文
容器编排:在CD过程中,利用kubectl set image进行容器编排部署,自建Kubernetes集群进行业务容器编排管理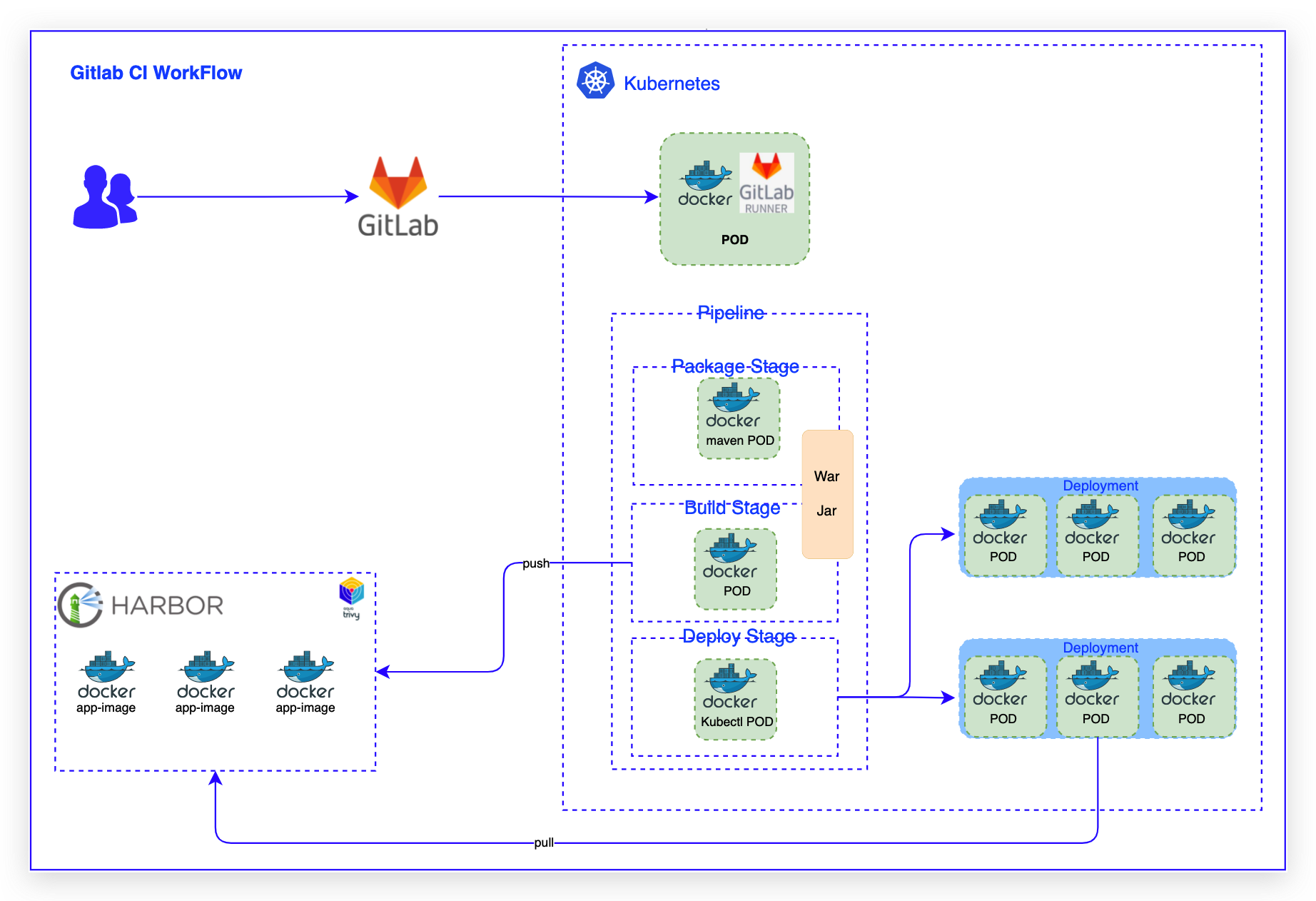- 高可用:当某个节点出现故障时,Kubernetes 会自动创建一个新的 GitLab-Runner 容器,并挂载同样的 Runner 配置,使服务达到高可用。- 弹性伸缩:触发式任务,合理使用资源,每次运行脚本任务时,Gitlab-Runner 会自动创建...
 特惠活动
特惠活动
 存储过程第二次运行更快。-优选内容
存储过程第二次运行更快。-优选内容
 存储过程第二次运行更快。-相关内容
存储过程第二次运行更快。-相关内容
一文读懂火山引擎云数据库产品及选型
> **火山引擎存储&数据库产品解决方案团队**,由资深的存储&数据库解决方案架构师组成。团队致力于帮助企业与组织更好的使用火山引擎云存储与云数据库产品,针对实际业务场景设计最优的解决方案,用专业技术助力组织和企业实现业务成功。## 为什么要做数据库选型### 数据库选型的重要性与难点发展数字经济是当下各行各业的重要方向。支撑数字经济的底座是软件,特别是基础软件,可以说基础软件是整个数字经济的坚实底座。在基础软...
干货|解析开源OLAP引擎基于共享存储的选主方式
采用了存储计算分离的架构,支持主流的 OLAP 引擎优化技术,实现了租户资源隔离、弹性扩缩容,并具有数据读写的强一致性等特性。 **「基于共享存储的选主方式」** 作为 ByConity 的重要功能,本文将详细介绍它基于存算... 这是因为 Raft 协议需要过半节点正常运行,才能维护主节点的正常工作和选举。 2.节点增删和服务发现流程复杂。需要修改所有 keeper 节点的配置文件才能生效,且所有的调用者也需要修改配置才能发现这个...
火山引擎云原生存储加速实战
存储和中间件。* 顶层是计算业务,大部分都是基于 K8s 底座运行的。在计算底座基础上会进行一些大数据任务以及 AI 训练任务,再往上就是各种各样的计算框架。* 底层是存储服务,目前来看存算分离是业界未来的趋势... 各个云厂商都推出了对象存储与 PFS 结合的能力,愿景是冷数据存放在对象存储,热数据在 PFS。但实际的业务体验并不是很方便,两边的数据流动也需要很多的治理成本。**02****什么是“好”的存储加速...
基于共享存储的 leader 选举:在存算分离架构云数仓 ByConity 中的实践
运维管理都有一定的复杂度。在越来越多的分布式系统中使用一份高可用存储来实现 share-everything 存算分离架构的今天,我们可以利用这块高可用存储来模拟单机系统里的共享内存,将不同的计算节点看成是单机系统里... 这是因为 Raft 协议需要过半节点正常运行,才能维护主节点的正常工作和选举。2. 节点增删和服务发现流程复杂。需要修改所有 keeper 节点的配置文件才能生效,且所有的调用者也需要修改配置才能发现这个结果。ByConi...
ELT in ByteHouse 实践与展望
将来源不同、格式各异的数据提取到数据仓库中,并进行处理加工。 传统的数据转换过程一般采用Extract-Transform-Load (ETL)来将业务数据转换为适合数仓的数据模型,然而,这依赖于独立于数仓外的ETL系统,因而... 点击流等通过MQ/Kafka/Flink将其接入存储系统当中,存储系统又可分为域内的HDFS和云上的OSS&S3这种远程储存系统,然后进行一系列的数仓的ETL操作,提供给OLAP系统完成分析查询。但有些业务需要从上述的存储中做一个...
使用 vePFS 文件存储静态存储卷
文件存储 vePFS 提供超高 IOPS 产品能力,并支持在线弹性扩展,可快速实现容量及吞吐性能的线性增长,提升计算效率的同时,简化产品的运维的难度及成本。 AI 数据处理:图片、视频处理等 I/O 密集型应用,数据流复杂、数... 正在运行的 Pod 仍可继续访问 vePFS 存储至运行结束;但若 csi-vepfs 已经被卸载,删除 Pod 将会阻塞住,重新安装 csi-vepfs 后可继续删除 Pod。因此,不建议在 Pod 运行的时卸载 csi-vepfs 组件。 csi-vepfs 使文件系...
字节跳动高性能 Kubernetes 元信息存储方案探索与实践
KubeBrain 是字节跳动针对 Kubernetes 元信息存储的使用需求,基于分布式 KV 存储引擎设计并实现的、可以取代 etcd 的元信息存储系统,目前支撑着线上超过 20,000 节点的超大规模 Kubernetes 集群的稳定运行。项... etcd 并不是一个专门为 K8s 设计的元信息存储系统,其提供的能力是 K8s 所需的能力的超集。在使用过程中,其暴露出来的**主要问题**有:* etcd 的网络接口层限流能力较弱,雪崩时自愈能力差;* etcd 所采用的是单...
万字长文带你漫游数据结构世界|社区征文
精心选择的数据结构可以带来更高的运行或者存储[效率](https://baike.baidu.com/item/效率/868847)。数据结构往往同高效的检索[算法](https://baike.baidu.com/item/算法/209025)和[索引](https://baike.baidu.com... 我们看看插入新节点的具体过程(这里只展示中间位置的插入,头尾插入比较简单):中;又或者,特定请求的元数据信息,从服务请求中剥离出来,发送给一个异常收集服务,如 NewRelic。**(3)Tracing:** 特点是它在单次请求的范围内,处理信息。任何的数据、元数据信息都被绑定到系统中的单个事务上。例如:一次调用远程服务的 RPC 执行过程;一次实际的 SQL 查询语句;一次 HTTP 请求的业务性 ID。# 4、云原生应用特点云原生:云原生是一种专门针对云上应用而设计的方法,用于构建和部署应用,以...
