前几个折叠的F1分数较低
 社区干货
社区干货
社区征文|ChatGPT教我如何面试
乐观锁更适用于数据库并发访问较少的情况,而悲观锁则更适用于数据库并发访问较多的情况。###### Q:Python2和Python3的区别?Python2和Python3是Python计算机编程语言的两个不同版本。它们之间有一些重要的区别。... 算法评测包括以下几个步骤:1. 确定评测标准。评测标准可以是算法的准确度、精度、召回率、F1分数等。1. 准备评测数据集。通常,评测数据集包括一组已知结果的样本数据,算法需要对这些数据进行处理并输出预测结...
如何搭建清晰易懂的数据看板?|社区征文
**不过在此之前,需要先探讨一个问题:何谓“好看” ❓ ❓ ❓**> 好看可以从两个角度去理解,一是易于理解( Easy to read),即清晰准确的呈现指标全貌,让读者无需花费时间和经历去解读,能够第一时间读懂数据。二是美观优雅(Good-looking),即通过规则又协调的页面,吸引读者注意力尽可能多的停留在看板上。 因此,制作看板的致胜秘诀主要体现在以下三个方面: ### 1⃣️ **讲好故事(Tell a good story)**一个好的数据看板...
集简云 x 支点天成,实现抖店到企微售后消息实时提醒,提高行业竞争力
提高同行竞争优势的维度比较多样化,比如处理售后问题的时效,获得入驻平台分数的高低,展现量的多少,当这些项信息分值高,商家竞争优势就会相对大一些,从而推动销售额上升。因此,企业只有从多方位做好服务,才能让企业... 上述几个问题是目前大大小小商家都存在的痛点,支点天成公司也是如此。 ******客户********· 背景介绍******============================== 支点天成是一家从事图书...
AgentLM:能打的 Agent 模型来了!7B,13B,70B 全开源
=&rk3s=8031ce6d&x-expires=1714839668&x-signature=J72YdICUTxPHF1GpEzc%2FkrBwlNU%3D)在同分布任务中,AgentLM 能取得与 GPT-4 媲美的分数: 特惠活动
特惠活动
 前几个折叠的F1分数较低-优选内容
前几个折叠的F1分数较低-优选内容
 前几个折叠的F1分数较低-相关内容
前几个折叠的F1分数较低-相关内容
从应用看火山引擎 AB 测试 (DataTester) 的最佳实践
=&rk3s=8031ce6d&x-expires=1714926090&x-signature=6p9dBMT7mj8mLVTI%2F1BlE3j6JbQ%3D) 大家可以从上图中的数字感受到在字节跳动 A/B 实验应用的广度和深度,并且这些数字还在继续快速上涨。A/B 实验在临床医学和生物制药领域已经有几百年的应用历史,随着互联网的发展和各行业数字化的普及,更多业务搬到了线上,也具备了实验驱动的基础。 A/B 测试是快速迭代和做业务决策的一个基础功能,在功能上线前我们都会先进行一...
集简云5月新增/更新:新增6大功能,21款应用,更新17款应用,新增近160个动作
前置步骤的错误编码、错误信息、内部错误码的错误变量,以及预先添加的自定义变量如:客服手机号、邮箱号、企业id、模板id、指定人员userid等,作为变量数据插入流程字段配置中,满足变量批量替换、错误监控、流程参数... 选填字段自动分类折叠——让字段配置更高效](http://mp.weixin.qq.com/s?__biz=Mzg5MjcxODg4Mw==&mid=2247511585&idx=2&sn=e505b5f11e89f04f051ff28edcbeef78&chksm=c03b346df74cbd7bf1f11dd3f3aa0bf84efa3404065e...
风起云涌的2023年,异彩纷呈的AI世界 | 社区征文
该方法通过分数蒸馏抽样寄到的提升了 2D 提升算法的稳定性,改善了 3D 一致性。OpenAI 发布的 Shap-E、加州大学发布的 One-2-3-45 模型则在效率和准确率方面做了很大的优化,其中 One-2-3-45 从 2D 图像中生成高质... 难度进一步降低。后续的几个月中,又陆续更新了微调训练、Lora、SDXL Turbo 模型等。9 月份,《IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models》 发布,垫图神器,不再需要复...
粗排优化探讨|得物技术
* 曝光商品粗排总分与精排效率分数的NDCG。衡量排序结果的一致性,越高代表结果与精排越一致;* 同批评估样本下的 AUC。衡量模型打分结果的准确率,越高代表准确率越高。### **衡量召回->粗排的损失*** 以场景... 目前就同时存在 DPV 和 UV 价值两个目标,如果在粗排阶段就能区分目标,对最终效果影响无疑更大。那么如何在粗排实现多目标建模呢。----------------------------------------------------------------------------...
火山引擎云原生大数据在金融行业的实践
这两个集群不仅不能彼此共享资源,而且资源利用率都非常低。离线计算和在线业务的资源需求具有周期性变化,资源需求高峰时资源不足,低峰时资源冗余。而在线业务与离线计算的资源高低峰期往往是错开的,所以离线计算... 最后将 Pod 绑定到分数最高的节点上。大数据作业,特别是批式计算,只会占用资源一段时间,运行结束后归还资源。为了保证大数据作业可以充分利用集群资源,通常用户会提交多个作业,部分作业不能立刻获得资源,而是排...
模型的效果评估
该指标描述在所有正例中有多少被预测出来(预测的是否完整)。多分类的场景下分别以 Micro、Macro、Weighted 三种方式计算该指标。 使用场景:图像分类、文本分类、表格分类。 Precision含义:精确率。该指标越接近 ... Score含义:F1 分数。Recall 和 Precision 共同作用下的指标,该指标越接近 1 则模型质量越高。多分类的场景下分别以 Micro、Macro、Weighted 三种方式计算该指标。 使用场景:图像分类、文本分类、表格分类。 Conf...
文本向量化模型新突破——acge_text_embedding勇夺C-MTEB榜首
取得了什么样的成绩?> > • 文本向量化模型的突破与检索增强生成RAG的联系?# 一、文本向量化模型新突破——acge模型## 1.1、文本向量化模型文本向量化模型是自然语言处理(NLP)中的一项核心技术,它可以将单词、句子或图像特征等高维的离散数据转换为低维的连续向量,从而将文本数据转换为计算机能够处理的数值型向量形式。如下图所示,文本向量化模型通过将“家常菜烹饪指南”转换为数值向量,可以将文本信息表示成能够表达文本...
干货|什么才是“好的”A/B测试体系
biz=MzkwMzMwOTQwMg==&mid=2247511396&idx=1&sn=f5f1b652516baec8c1e8672ef7214c52&chksm=c09adc51f7ed55476830ead96bd1f41dcc1d57cd79867a781f0c35ecb7ad0dcdd12721c57d5c&scene=21#wechat_redirect)**... 分为两个阶段,第一个就是激活、提留到营收的阶段,这个阶段主要是从事一些用户体验、使用链路方面的优化、以及用户侧和商业化的产品功能优化,这部分的主要使用群体是产研部门,包括产品、研发、设计、数据分析师,还有...
人工智能在客户关系管理软件销售和服务模块中的应用 | 社区征文
Auto Extraction 则代表直接使用当前 tenant 的数据作为历史数据。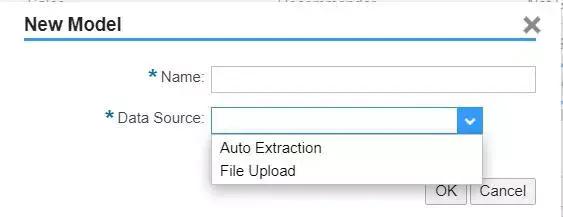等模型... 我们会给出Surge 的分数,范围在 1 到 99 之间,每周更新一次。C4C 会将某个客户总的 Surge 分数显示在屏幕右侧 Insights 面板内,同时显示出 Surge 分数最高的前三个话题。下图 Surge 分数前三的话题依次为:- Ar...
