机器学习的训练和测试数据
 社区干货
社区干货
浅谈AI机器学习及实践总结 | 社区征文
在机器学习中,把自变量叫做特征(feature)多个自变量分别可以定义为X1,X2..Xn,因变量叫做标签(label),可定义为Y,而一批特征和标签的集合,就是机器学习的数据集。机器学习的学习过程就是在已知的数据集的基础上,通过反复的计算,选择最准确的函数去描述数据集中自变量X1,X2....Xn 和因变量Y之间的因果关系。这个过程就称之为机器学习的训练也叫拟合。这里还需要明确几个概念,训练集、验证集、测试集训练集,最开始用来训练的数...
字节跳动 EB 级 Iceberg 数据湖的机器学习应用与优化
目前字节跳动以及整个业界在机器学习和训练样本领域的一些趋势如下: 首先,**模型** **/样本** **越来越大**。随着模型参数的增多,为了训练这些庞大的模型需要更多、更丰富的训练数据来确保模型的准确性和泛化能力。其次,**训练算力越来越强**。在过去,训练一个机器学习模型可能需要数周甚至数月的时间。然而,如今基于更好的模型架构和高速显卡,我们可以在相对较短的时间内完成训练过程并进行 A/B 测试验证。另外,**特征...
如何构建过拟合和防过拟合模型
机器学习提供了一种可以自动构建和修改模型的强大方法,能够从大量的输入数据中学习和优化模型,以产生更准确、更精确的预测。但是,当机器学习模型过分关注训练数据中的噪声和其他异常因素,而忽略了其他重要特征时,该模型可能会发生“过拟合”。如果模型太简单,而忽略了许多重要特征,则可能会发生“欠拟合”。因此,要构建准确的机器学习模型,用户需要有一种策略来确保模型不会过拟合或欠拟合,以确保预测的准确性。下面,我们将讨论如...
我的技术年终总结——机器学习 |社区征文
## 一、机器学习是什么?- 从广义上来说,机器学习是一种能够赋予机器学习的能力以此让它完成直接编程无法完成的功能的方法。但从实践的意义上来说,机器学习是一种通过利用数据,训练出模型,然后使用模型预测的一种方法。 - 直观上理解,机器学习(Machine Learning,ML)是研究计算机模拟人类的学习活动,获取知识和技能的理论和方法,改善系统性能的学科。因为计算机系统中“经验‘通常以数据的形式存在,所以机器要利用经验,就必...
 特惠活动
特惠活动
 机器学习的训练和测试数据-优选内容
机器学习的训练和测试数据-优选内容
 机器学习的训练和测试数据-相关内容
机器学习的训练和测试数据-相关内容
机器学习
1.功能概述 机器学习,是指可视化建模支持机器学习算子,对数据进行加工处理,以便用户基于数据进行模型训练、深度分析、预测分析等。本文将为您介绍机器学习算子的功能。 2.算子介绍 2.1 预测将机器学习算子训练生成的模型应用于预测数据的数据上,一般链接在机器学习算子后面。 说明 字段设置 特征列映射:设置模型中的特征列和数据中的特征列的映射关系。 标签列: 标签列,分类训练的依据。 参数设置 预测的列名:预测的列的名字。 ...
机器学习
1. 概述 机器学习,是指可视化建模支持机器学习算子,对数据进行加工处理,以便用户基于数据进行模型训练、深度分析、预测分析等。本文将为您介绍机器学习算子的功能。 2. 功能介绍 2.1 预测将机器学习算子训练生成的模型应用于预测数据的数据上,一般链接在机器学习算子后面。字段设置特征列映射:设置模型中的特征列和数据中的特征列的映射关系。标签列:标签列,分类训练的依据。参数设置预测的列名:预测的列的名字。 2.2 one-hot 模...
AI 和机器学习:探索智能科技的未来 | 社区征文
通过分析大量的设计数据和模拟来优化工程设计。例如,可以使用基于机器学习的算法来改进产品设计,减少材料浪费,并提高产品性能:```# 一个简单的基于机器学习的设计优化示例from sklearn.model_selection import train_test_splitfrom sklearn.linear_model import LinearRegression# 加载和准备设计数据# ...# 划分数据集为训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, r...
技术人的 2023 总结:人工智能-基于机器学习的环境污染影响评估学习|社区征文
集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 数据标准化scaler = StandardScaler()X_train_scaled = scaler.fit_transform(X_train)X_test_scaled = scaler.transform(X_test)```## 模型选择和训练:在数据准备好之后,选择适当的机器学习模型对环境污染的影响进行评估。常见的模型包括决策树、随机森林、支持向量机等。这里选择随机森林模型进行演示。`...
项目经验分享:机器学习在智能风控中的应用|社区征文
传统方法一般采用系统及静态模型进行实时监控和预测,无法适应灵便的使用场景;此外,处理规模性数据的效率很低,无法提供精确的风险评估和投资决策。基于数据发掘算法,融合了机器学习的特征,基本解决了这些问题。为... SVM是一种常用的监督学习模型,一般用于分类和回归任务。这里用它及逆行训练并评估。```#创建并训练SVM模型svm_model = SVC()svm_model.fit(X_train, y_train)#在测试集上进行预测y_pred = svm_model.predic...
字节跳动 EB 级 Iceberg 数据湖的机器学习应用与优化
目前字节跳动以及整个业界在机器学习和训练样本领域的一些趋势如下:首先, **模型** **/样本** **越来越大**。随着模型参数的增多,为了训练这些庞大的模型需要更多、更丰富的训练数据来确保模型的准确性和泛化能力。其次, **训练算力越来越强**。在过去,训练一个机器学习模型可能需要数周甚至数月的时间。然而,如今基于更好的模型架构和高速显卡,我们可以在相对较短的时间内完成训练过程并进行 A/B 测试验证。...
针对算法工程师的快速入门
本文主要面向有一定编码能力的算法工程师。在首次使用火山引擎机器学习平台的情况下,帮助用户快速上手,在平台上完成模型开发调试、训练的关键流程。主要适用场景: 模型所需的样本和代码已部分或全部开发完成,用户需要在对代码 0 修改的情况下,将相关工作迁移到机器学习平台。利用其提供的 GPU & CPU 算力、数据存储和缓存加速方案、训练任务编排和调度等能力完成模型的高效迭代。 从 0 开始,在机器学习平台上完成从原始数据到模型...
火山引擎大规模机器学习平台架构设计与应用实践
>作者:火山引擎AML团队## 模型训练痛点关于模型训练的痛点,首先是技术上的。现在机器学习应用非常广泛,下表给出了几种典型的应用,包括自动驾驶、蛋白质结构预测、推荐广告系统、NLP 等。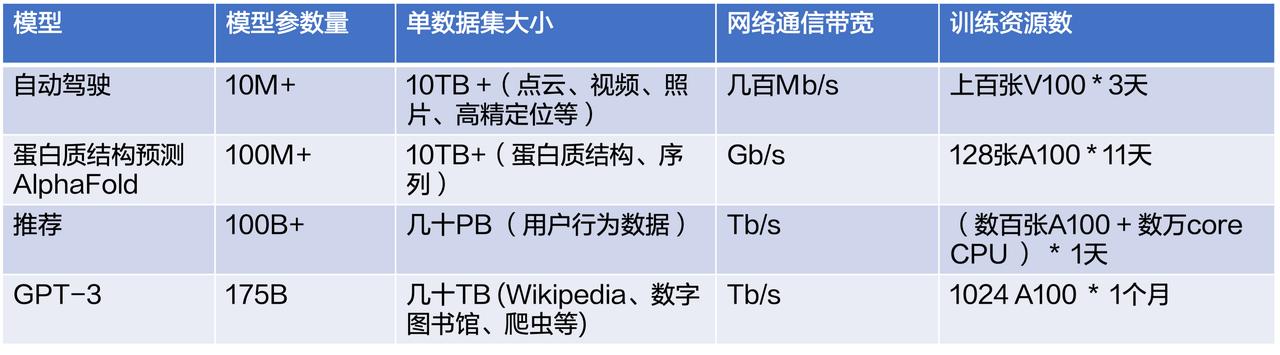可以看到不同应用场景下的参数和数据集、模型训练过程中的网络通信带宽、训练资源数和时长都不尽相同...
在线学习FTRL介绍及基于Flink实现在线学习流程|社区征文
# 背景目前互联网已经进入了AI驱动业务发展的阶段,传统的机器学习开发流程基本是以下步骤:数据收集->特征工程->训练模型->评估模型效果->保存模型,并在线上使用训练的有效模型进行预测。这种方式主要存在两个... 就用该样本产生的loss和梯度对模型迭代一次,一个一个数据地进行训练,能够根据线上反馈数据,实时快速地进行模型调整,使得模型及时反映线上的变化,提高线上预测的准确率。因此可以处理大数据量训练和在线训练。常用的...
