惩罚线性回归的预测区间
 社区干货
社区干货
与 AI 相伴的一年|社区征文
线性运算转化为分类所需的离散值,所以通常在全连接层之后、展平层之后或输出层加入激活函数,发挥激活函数的功能。设计深度神经网络时,对激活函数通常有如下要求:一是激活函数要连续并可导(允许少数点上不可导),因为通常通过梯度法优化网络参数,可导的激活函数可以直接利用数值优化的方法来学习网络参数。二是激活函数及其导函数要尽可能简单,有利于提高网络计算效率。三是激活函数的导函数值域要在一个合适的区间内,不能太大也...
分布式数据库TiDB的设计和架构
无法线性扩容,海量数据下处理能力大幅下降。 **2008年至2013年**2008年至2013年,随着搜索/社交的发展,数据量爆发增长,传统数据库高成本,无法线性扩容问题日益突显;分布式及分布式非关系型(NoSQL)开始快速发展,如 MongoDB,HBase。但此类数据库的局限在于无法处理交易类数据及复杂业务逻辑的特性,限制其在非互联网领域的发展。**2013年以后**2013年以来,有个新的概念为分布式关系型数据库(NewSQL),它是兼具NoSQL扩展性又不...
图片美学评价
大多数现有方法仅预测由AVA[1]和TID2013[2]等数据集提供的评分得分。本文介绍一种我们在动态图片打标中用到的基于深度学习模型的方法[3],该方法与其他方法的区别在于我们使用卷积神经网络预测人类意见得分的分布... 使用线性整流(Rectified Linear Units, ReLU)。* **池化层(Pooling layer)** ,通常在卷积层之后会得到维度很大的特征,将特征切成几个区域,取其最大值或平均值,得到新的、维度较小的特征。* **全连接层( Fully-Co...
分布式数据库TiDB的设计和架构
无法线性扩容,海量数据下处理能力大幅下降。**2008年至2013年**2008年至2013年,随着搜索/社交的发展,数据量爆发增长,传统数据库高成本,无法线性扩容问题日益突显;分布式及分布式非关系型(NoSQL)开始快速发展,如... 每个 Region 负责存储一个 Key Range(从 StartKey 到 EndKey 的左闭右开区间)的数据,每个 TiKV 节点会负责多个 Region。TiKV 的 API 在 KV 键值对层面提供对分布式事务的原生支持,默认提供了 SI (Snapshot Isolati...
 特惠活动
特惠活动
 惩罚线性回归的预测区间-优选内容
惩罚线性回归的预测区间-优选内容
 惩罚线性回归的预测区间-相关内容
惩罚线性回归的预测区间-相关内容
分布式数据库TiDB的设计和架构
无法线性扩容,海量数据下处理能力大幅下降。**2008年至2013年**2008年至2013年,随着搜索/社交的发展,数据量爆发增长,传统数据库高成本,无法线性扩容问题日益突显;分布式及分布式非关系型(NoSQL)开始快速发展,如... 每个 Region 负责存储一个 Key Range(从 StartKey 到 EndKey 的左闭右开区间)的数据,每个 TiKV 节点会负责多个 Region。TiKV 的 API 在 KV 键值对层面提供对分布式事务的原生支持,默认提供了 SI (Snapshot Isolati...
字节跳动副总裁杨震原:A/B测试不是万能的,但不会一定不行
它波动的范围如果按照95%的区间,从-0.1一直到0.147,是非常大的范围。把置信度画出来,发现这个实验完全不能说明A比B好。结论就是:这个实验不可信,没有显著性,完全不能从这个实验中得出A比B好的结论。 还有长短期的影响,这也是一个常见的问题。我举一个例子,比如说,我们对每个商品会有评价,现在兴趣电商比较热,电商的推荐主要会考虑它的评价,对于评价低的商品,我们会做一些控制和惩罚,让它的推荐少一些。如果加大惩罚力度,或者由不...
粗排优化探讨|得物技术
而不是在喜欢的商品集合中精准预测更喜欢哪个。 **全域Hitrate评价体系**深度统一粗排在淘宝主搜索的优化实践[1]淘宝主搜将 “全域成交 Hitrate” 作为粗排最重... 在 10^3 至 10^4 区间粗排可能比精排打分 Hitrate 更高,验证了粗排相对精排,对腰部商品排序更准确。### **衡量粗排->精排的损失*** 以场景内成交为准,计算场景内 Hitrate@TopK 。衡量 Top 集合命中程度,越...
聊聊数据驱动和用A/B测试解决问题
它波动的范围如果按照95%的区间,从-0.1一直到0.147,是非常大的范围。把置信度画出来,发现这个实验完全不能说明A比B好。结论就是:这个实验不可信,没有显著性,完全不能从这个实验中得出A比B好的结论。 **还有长短期的影响,这也是一个常见的问题。** 我举一个例子,比如说,我们对每个商品会有评价,现在兴趣电商比较热,电商的推荐主要会考虑它的评价,对于评价低的商品,我们会做一些控制和惩罚,让它的推荐少一些。如果加大惩罚力度,...
【社区征文】Compose 为什么可以跨平台?
状态树实际是使用一个被称作 Slot Table 的线性数据结构实现的,可以把他理解为一个数组,存储着状态树深度遍历的结果,数组的各个区间存储着对应 UI 节点上的状态。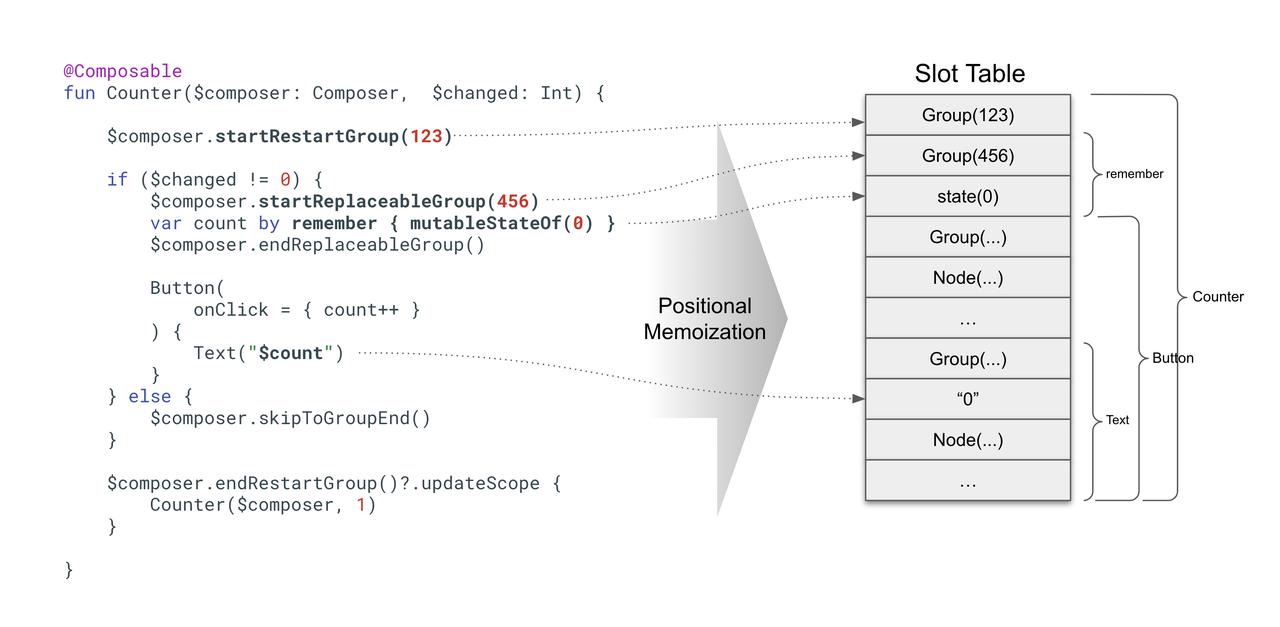Comopsable 首次执行时,产生的 Group 以及所瞎的状态会以此填充到 Slot Table 中,填充时会附带一个编译时给予代码位置生成的不重复...
【案例】商业银行客户流失预测
本案例结合银行客户流失数据预测案例,重点介绍了决策树在实际案例中的应用。本案例通过客户的交易信息数据挖掘出对流失影响的信息,从而加强对客户的跟踪和营销,减少不必要的客户流失。 二、问题建模关于如何进行建... 未知 Income_Category string 收入区间 帐户持有人的年收入类别(< $40K、$40K - 60K、$60K - $80K、$80K-$120K,>$120K) Card_Category string 信用卡的分类 卡类型(蓝、银、金、白金) Months_on_book int 持有时间...
商业银行客户流失预测
本案例结合银行客户流失数据预测案例,重点介绍了决策树在实际案例中的应用。本案例通过客户的交易信息数据挖掘出对流失影响的信息,从而加强对客户的运营和营销,减少不必要的客户流失。 2. 建模方法论 关于如何进行... 未知 Income_Category string 收入区间 帐户持有人的年收入类别(< $$$$40K、$$$$40K - 60K、$$$$60K - $$$$80K、$$$$80K-$$$$120K,>$120K) Card_Category string 信用卡的分类 卡类型(蓝、银、金、白金) Months_on...
