批量图像处理的索引不匹配
 社区干货
社区干货
集简云本周更新:流程模版中心上线,新增应用:千米网,App评论订阅
一键创建,流程配置中需要的样本与字段设置默认设置好,只需要添加自己的应用帐号保存即可开启您的自动化流程。  特惠活动
特惠活动
 批量图像处理的索引不匹配-优选内容
批量图像处理的索引不匹配-优选内容
 批量图像处理的索引不匹配-相关内容
批量图像处理的索引不匹配-相关内容
API 发布历史
批量删除 DirectUrl 模式文件 查询跨空间文件迁移任务状态 提交跨空间文件迁移任务 GetMediaList 请求参数 title 标题,支持模糊搜索音视频文件 获取音视频列表 2024-03-19 -- 视频剪辑的 Track 视频轨道列表中 Au... 索引文件参数。 确认上传 2023-09-01 StartWorkflow GetWorkflowExecutionResult ListSnapshots StartWorkflow 的请求参数的 Input 中的 Snapshot 数组新增 SampleOffsets 采样截图自定义时间参数。 返回参数 Sn...
干货|Hudi Bucket Index 在字节跳动的设计与实践
离线批量更新数据,并且可以通过 Spark、Flink、Presto 等计算引擎进行写入和查询。Hudi 官方对于文件管理和索引概念的介绍如下,> Hudi提供类似 Hive 的分区组织方式,与 Hive 不同的是,Hudi 分区由多个 File Grou... 索引带来的性能收益是非常巨大的, 尽管 Hudi 已支持 Bloom Filter Index、Hbase index类型,但在字节跳动大规模数据入湖、探索分析等场景中,我们仍然碰到了现有索引类型无法解决的挑战,因此在实践中我们开发了 Buck...
干货|Hudi Bucket Index 在字节跳动的设计与实践
离线批量更新数据,并且可以通过 Spark、Flink、Presto 等计算引擎进行写入和查询。Hudi 官方对于文件管理和索引概念的介绍如下,> Hudi 提供类似 Hive 的分区组织方式,与 Hive 不同的是,Hudi 分区由多个 File Gro... 索引带来的性能收益是非常巨大的, 尽管 Hudi 已支持 Bloom Filter Index、Hbase index 类型,但在字节跳动大规模数据入湖、探索分析等场景中,我们仍然碰到了现有索引类型无法解决的挑战,因此在实践中我们开发了 Buc...
Hudi Bucket Index 在字节跳动的设计与实践
离线批量更新数据,并且可以通过 Spark、Flink、Presto 等计算引擎进行写入和查询。Hudi 官方对于文件管理和索引概念的介绍如下,> > > Hudi 提供类似 Hive 的分区组织方式,与 Hive 不同的是,Hudi 分区由多个 F... 索引带来的性能收益是非常巨大的, 尽管 Hudi 已支持 Bloom Filter Index、Hbase index 类型,但在字节跳动大规模数据入湖、探索分析等场景中,我们仍然碰到了现有索引类型无法解决的挑战,因此在实践中我们开发了 Buc...
干货|Hudi Bucket Index 在字节跳动的设计与实践
离线批量更新数据,并且可以通过 Spark、Flink、Presto 等计算引擎进行写入和查询。Hudi 官方对于文件管理和索引概念的介绍如下,> > > Hudi提供类似 Hive 的分区组织方式,与 Hive 不同的是,Hudi 分区由多个 Fi... 索引带来的性能收益是非常巨大的, 尽管 Hudi 已支持 Bloom Filter Index、Hbase index类型,但在字节跳动大规模数据入湖、探索分析等场景中,我们仍然碰到了现有索引类型无法解决的挑战,因此在实践中我们开发了 Buck...
Hudi Bucket Index 在字节跳动的设计与实践
离线批量更新数据,并且可以通过 Spark、Flink、Presto 等计算引擎进行写入和查询。Hudi 官方对于文件管理和索引概念的介绍如下,> Hudi提供类似 Hive 的分区组织方式,与 Hive 不同的是,Hudi 分区由多个 File Grou... 索引带来的性能收益是非常巨大的, 尽管 Hudi 已支持 Bloom Filter Index、Hbase index类型,但在字节跳动大规模数据入湖、探索分析等场景中,我们仍然碰到了现有索引类型无法解决的挑战,因此在实践中我们开发了 Buck...
VikingDB:大规模云原生向量数据库的前沿实践与应用
磁盘索引(DiskANN)、基于向量的粗排打散等。在内部产品的不断迭代过程中,VikingDB 也逐渐契合云原生的理念,为孵化商业化向量数据库产品打下了坚实的基础。依托于 VikingDB 在字节内部积累的丰富经验,我们在火山... 成为了当前业界最流行的解决方案。RAG 结合检索和生成两个关键组件,通过检索为大模型提供相关数据作为上下文信息。由于向量数据库能够高效存储和检索模型生成的向量,从而提供语义上更具有相关性的检索结果,因此向...
数仓进阶篇@记一次BigData-OLAP分析引擎演进思考过程 | 社区征文
基于es倒排索引+宽表模型,数据检索性能大幅度提升,上一组案例效果。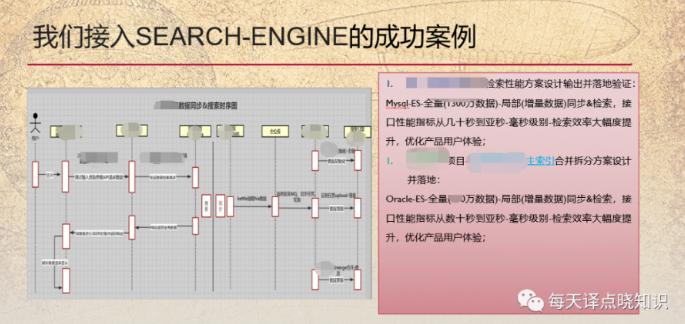随着查询越来越复杂,数据规模持续增长,我们的数据分析目前也越来越复杂,数据规模也需考虑集中存储。 ## 猜想是否能够在数据库中,通过一系列高级分析算法,对数据进行分析与处理? ## 预期成熟的海量数据解决方案 ...
电商场景下 ES 搜索引擎的稳定性治理实践
继上文在完成了从千万级到亿级商品量级搜索系统的搭建后,本文将继续介绍一些扩容无法解决的 ES 性能问题,即对相关 ES 搜索引擎的稳定性治理实践。希望通过本文大家可以对 ES 的使用场景有更多数据和使用上的参考。... **Search 查询有数据缓存而 Scroll 没有** :在Search API 中,ES 会执行查询并返回匹配的结果集。这些结果通常是直接从索引中检索的,并且在查询时可能会使用缓存来提高性能。一旦查询完成,ES 会将结果缓存在内存中...
