hbase查找最后一行
 社区干货
社区干货
20000字详解大厂实时数仓建设 | 社区征文
最终基于顺风车数仓 ods 层建设规范分主题统一写入 kafka 存储介质中。命名规范:ODS 层实时数据源主要包括两种。- 一种是在离线采集时已经自动生产的 DDMQ 或者是 Kafka topic,这类型的数据命名方式为采集系统... Hbase、fusion(滴滴自研 KV 存储) 三种存储引擎,对于维表数据比较少的情况可以使用 MySQL,对于单条数据大小比较小,查询 QPS 比较高的情况,可以使用 fusion 存储,降低机器内存资源占用,对于数据量比较大,对维表数据...
一文读懂火山引擎云数据库产品及选型
一行数据表示一个实体信息,每一行数据的属性都是相同的,通过 SQL 语言进行操作,容易理解,广泛应用于企业的 ERP、CRM、财务系统和交易系统等核心业务系统。其最大的特点是**支持事务,遵循 ACID,保证数据强一致性**。... 宽列型 NoSQL 数据库(以 HBase 为代表)、时序型 NoSQL 数据库(以 InfluxDB 为代表)以及图 NoSQL 数据库(以 Neo4j 为代表)**。虽然这些类型都属于 NoSQL 数据库范畴,但是不同类型的 NoSQL 数据库所适用的场景各有不...
Hive SQL 底层执行过程 | 社区征文
Hive直接访问存储在 HDFS 中或者 HBase 中的文件,通过 MapReduce、Spark 或 Tez 执行查询。我们今天来聊的就是 Hive 底层是怎样将我们写的 SQL 转化为 MapReduce 等计算引擎可识别的程序。了解 Hive SQL 的底层编... 接收查询的组件。该组件实现了会话句柄的概念。3. COMPILER:编译器。负责将 SQL 转化为平台可执行的执行计划。对不同的查询块和查询表达式进行语义分析,并最终借助表和从 metastore 查找的分区元数据来生成执行计...
数据库顶会 VLDB 2023 论文解读 - Krypton: 字节跳动实时服务分析 SQL 引擎设
结果通过 ETL 导入到 HBase/ES/ClickHouse 等系统提供在线的查询服务。对于实时链路, 数据会直接进入到 HBase/ES 提供高并发低时延的在线查询服务,另一方面数据会流入到 ClickHouse/Druid 提供在线的查询聚合服务。... Ordinal Index:根据行号快速查找目标的 Data Page。1. Sparse Index:Min/Max、Bloom Filter 以及 Ribbon Filter,可以快速过滤掉无效的 Data Page。1. Short-key Index:使用 Sorted Key 的前 36 个字节作为 I...
 特惠活动
特惠活动
 hbase查找最后一行-优选内容
hbase查找最后一行-优选内容
 hbase查找最后一行-相关内容
hbase查找最后一行-相关内容
基础使用
HBase或任何提供Hadoop InputFormat的数据集。 2.1 创建RDD示例:通过集合来创建RDD val data = Array(1, 2, 3, 4, 5)val distData = sc.parallelize(data)通过外部数据集构建RDD val distFile = sc.textFile("data.txt")RDD构建成功后,可以对其进行一系列操作,例如Map和Reduce等操作。例如,运行以下代码,首先从外部存储系统读一个文本文件构造了一个RDD,然后通过RDD的Map算子计算得到了文本文件中每一行的长度,最后通过Reduce算子...
20000字详解大厂实时数仓建设 | 社区征文
最终基于顺风车数仓 ods 层建设规范分主题统一写入 kafka 存储介质中。命名规范:ODS 层实时数据源主要包括两种。- 一种是在离线采集时已经自动生产的 DDMQ 或者是 Kafka topic,这类型的数据命名方式为采集系统... Hbase、fusion(滴滴自研 KV 存储) 三种存储引擎,对于维表数据比较少的情况可以使用 MySQL,对于单条数据大小比较小,查询 QPS 比较高的情况,可以使用 fusion 存储,降低机器内存资源占用,对于数据量比较大,对维表数据...
一文读懂火山引擎云数据库产品及选型
一行数据表示一个实体信息,每一行数据的属性都是相同的,通过 SQL 语言进行操作,容易理解,广泛应用于企业的 ERP、CRM、财务系统和交易系统等核心业务系统。其最大的特点是**支持事务,遵循 ACID,保证数据强一致性**。... 宽列型 NoSQL 数据库(以 HBase 为代表)、时序型 NoSQL 数据库(以 InfluxDB 为代表)以及图 NoSQL 数据库(以 Neo4j 为代表)**。虽然这些类型都属于 NoSQL 数据库范畴,但是不同类型的 NoSQL 数据库所适用的场景各有不...
Hive SQL 底层执行过程 | 社区征文
Hive直接访问存储在 HDFS 中或者 HBase 中的文件,通过 MapReduce、Spark 或 Tez 执行查询。我们今天来聊的就是 Hive 底层是怎样将我们写的 SQL 转化为 MapReduce 等计算引擎可识别的程序。了解 Hive SQL 的底层编... 接收查询的组件。该组件实现了会话句柄的概念。3. COMPILER:编译器。负责将 SQL 转化为平台可执行的执行计划。对不同的查询块和查询表达式进行语义分析,并最终借助表和从 metastore 查找的分区元数据来生成执行计...
数据库顶会 VLDB 2023 论文解读 - Krypton: 字节跳动实时服务分析 SQL 引擎设
结果通过 ETL 导入到 HBase/ES/ClickHouse 等系统提供在线的查询服务。对于实时链路, 数据会直接进入到 HBase/ES 提供高并发低时延的在线查询服务,另一方面数据会流入到 ClickHouse/Druid 提供在线的查询聚合服务。... Ordinal Index:根据行号快速查找目标的 Data Page。1. Sparse Index:Min/Max、Bloom Filter 以及 Ribbon Filter,可以快速过滤掉无效的 Data Page。1. Short-key Index:使用 Sorted Key 的前 36 个字节作为 I...
一文读懂火山引擎云数据库产品及选型
一行数据表示一个实体信息,每一行数据的属性都是相同的,通过 SQL 语言进行操作,容易理解,广泛应用于企业的 ERP、CRM、财务系统和交易系统等核心业务系统。其 **最大的特点是支持事务,遵循 ACID,保证数据强一致性*... 宽列型 NoSQL 数据库(以 HBase 为代表)、时序型 NoSQL 数据库(以 InfluxDB 为代表)以及图 NoSQL 数据库(以 Neo4j 为代表)** 。虽然这些类型都属于 NoSQL 数据库范畴,但是不同类型的 NoSQL 数据库所适用的场景各有不...
一文读懂火山引擎云数据库产品及选型
一行数据表示一个实体信息,每一行数据的属性都是相同的,通过SQL语言进行操作,容易理解,广泛应用于企业的 ERP、CRM、财务系统和交易系统等核心业务系统。其最大的特点是支持事务,遵循ACID,保证数据强一致性。业界常... 宽列型NoSQL数据库(以HBase为代表)、时序型NoSQL数据库(以InfluxDB为代表)以及图NoSQL数据库(以Neo4j为代表)。虽然这些类型都属于NoSQL数据库范畴,但是不同类型的NoSQL数据库所适用的场景各有不同,需要根据业务特征...
数据库顶会 VLDB 2023 论文解读:Krypton: 字节跳动实时服务分析 SQL 引擎设计
结果通过 ETL 导入到 HBase/ES/ClickHouse 等系统提供在线的查询服务。对于实时链路, 数据会直接进入到 HBase/ES 提供高并发低时延的在线查询服务,另一方面数据会流入到 ClickHouse/Druid 提供在线的查询聚合服务。... Ordinal Index:根据行号快速查找目标的 Data Page。2. Sparse Index:Min/Max、Bloom Filter 以及 Ribbon Filter,可以快速过滤掉无效的 Data Page。3. Short-key Index:使用 Sorted Key 的前 36 个字节作为 Inde...
数仓进阶篇@记一次BigData-OLAP分析引擎演进思考过程 | 社区征文
HBase、Vertica、Impala、Greenplum、 ClickHouse. 其中,**Hive:** 使用一种类似SQL查询语言,作用在分布式存储系统的文件之上,通常用于进行离线数据处理操作-MapReduce,支持多种不同的执行引擎-Hive on MapReduce、Hive on Tez、Hive on Spark.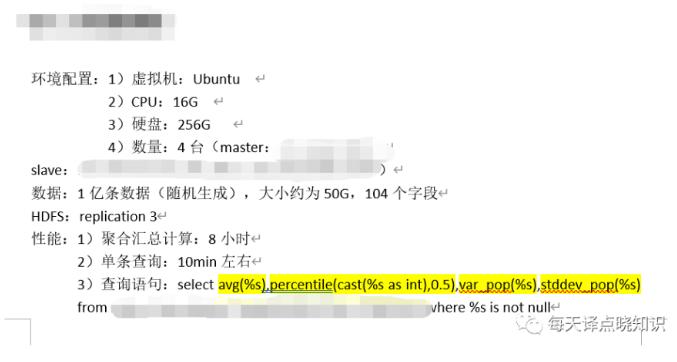**HBase:** 分布式、面向列开源数据库,不同...
