hbase实现feeds流
 社区干货
社区干货
社区收藏缓存设计重构实战 | 得物技术
**一、背景**=========社区收藏业务是一个典型的读多写少的场景,社区各种核心Feeds流都需要依赖用户是否收藏的数据判断,早期缓存设计时由于流量不是很大,未体现出明显的问题,近期通过监控平台等相关手段... 接下来我们来看一下伪代码的实现:``` //判断用户是否对指定的动态收藏 func IsLightContent(userId uint64,contentIds []uint64){ index := userId%20 ...
「火山引擎数据中台产品双月刊」 VOL.07
流式计算 Flink 引擎下的离线流式任务 - 数据地图、数据质量、数据安全支持 LAS 服务能力- **【私有化-功能迭代更新】** - 离线数据集成支持 Gbase8S2LAS、OceanBase2LAS、实时集成 Kafka2LAS - 数据开发支持 LAS Flink 任务类型 - 指标平台支持 HBase 数据源创建模型绑定 - 数据地图支持 GaussDB 元数据采集 - 数据安全新增审计日志功能- **【** **公有云** **-功能迭代更新】**...
「火山引擎」数据中台产品双月刊 VOL.04
可以对集群节点规格实现 scale-up。### **湖仓一体分析服务 LAS**- **【新增Presto定时扩缩容功能】** - 队列中交互式分析(Presto)部分支持定时扩缩容。定时 Resize ,超过 Min 部分的费用使用 CU 时收... HBase 的必选组件;Impala、Kudu、ClickHouse、Doris、StarRocks 等服务的核心指标接入监控和告警管理;HBase 中的表支持 Snappy 压缩;Hive,组件行为与开源保持一致,不再支持中文的表字段名;Doris,版本升级至1.1.5;H...
「火山引擎」数据中台产品双月刊 VOL.05
新增软件栈 2.2.0:HBase集群中集成Knox组件用于访问代理,并集成了YARN和MapReduce2;Flink引擎支持avro,csv,debezium-json和avro-confluent等格式。## 重点功能课堂### **大数据研发治理** **套件** **DataLeap****【分布式自治】** 包括工作台、规划、诊断、复盘等全流程治理环节。在治理场景中,提供数据质量安全、资源优化、报警、企业复盘管理等一系列垂直场景。在底层,包含数据全生命周期流程,从数据采集、数据传输...
 特惠活动
特惠活动
 hbase实现feeds流-优选内容
hbase实现feeds流-优选内容
 hbase实现feeds流-相关内容
hbase实现feeds流-相关内容
干货 | 这样做,能快速构建企业级数据湖仓
这种数据格式有三个实现: **Delta Lake** 、 **Iceberg** 和 **Hudi** 。三种格式的出发点略有不同,但是场景需求里都包含了事务支持和流式支持。在具体实现中,三种格式也采用了相似做法,即在数据湖的存储之上定... 并把提取出来的特征返存到湖仓或者 HBase 等键值存储。基于离线的数据可以进行离线训练,如通过 Spark MLlib 搭建传统的机型学习模型,或者通过 TensorFlow 进行深度模型的训练,把深度训练出来的模型部署到模型...
基于火山引擎 EMR 构建企业级数据湖仓
这种数据格式有三个具体的实现:Delta Lake、Iceberg 和 Hudi。三种格式提出的出发点略有不同,但是它们的场景需求里都不约而同地包含了事务支持和流式支持。而它们在具体的实现中也采用了比较相似的做法,即在数据... 然后把提取出来的特征再返存到湖仓或者 HBase 等键值存储。 基于这些离线的数据可以进行离线训练,比如通过 Spark MLlib 搭建传统的机型学习模型,或者通过 TensorFlow 进行深度模型的训练,把深度训练出来的模型部署...
20000字详解大厂实时数仓建设 | 社区征文
实现相应的精确去重和非精确去重。第三:汇总层建设过程中,还会涉及到衍生维度的加工。在顺风车券相关的汇总指标加工中我们使用 Hbase 的版本机制来构建一个衍生维度的拉链表,通过事件流和 Hbase 维表关联的方式得到实时数据当时的准确维度命名规范:DWM 层的表命名使用英文小写字母,单词之间用下划线分开,总长度不能超过 40 个字符,并且应遵循下述规则:`realtime_dwm_{业务/pub}_{数据域缩写}_{数据主粒度缩写}_[{自定义表命名...
EMR-3.2.1 版本说明
环境信息 系统环境版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.7.3 Java ByteOpenJDK 1.8.0_352 应用程序版本 Hadoop集群 Flink集群 Kafka集群 Presto集群 Trino集群 HBase集群 OpenSearch集... 由于DataLeap使用root用户向Hadoop集群提交Flink流任务,因此需在控制台-用户管理处新增root用户(密码自定义),并为root用户赋予hdfs、yarn权限,该步骤预计会在后续版本进行优化; 使用Dolphin Scheduler调度Presto数...
干货 | 看 SparkSQL 如何支撑企业级数仓
最重要的是如何基于企业业务流程来设计架构,而不是基于某个组件来扩展架构。一... 这三个方向被雅虎 Nutch 团队实现后贡献给 Apache,也就是目前大家看到的 HDFS,MapReduce 和 HBase,形成了早期 Hadoop 的三大利器。然而这三大利器更聚焦在异构数据的信息提取处理上,没有提供对结构化数据很友好的...
观点|SparkSQL在企业级数仓建设的优势
太过于局限于寻找完全契合的组件服务必然受限于服务本身的实现,给未来扩展留下巨大的约束。企业数据仓库架构必然不等于一个组件,大部分企业在数仓架构实施的都是都是基于现有的部分方案,进行基于自己业务合适... 这三个方向被雅虎Nutch团队实现后贡献给Apache,也就是目前大家看到的HDFS,MapReduce和HBase,形成了早期Hadoop的三大利器。然而这三大利器更聚焦在异构数据的信息提取处理上,没有提供对结构化数据很友好的类似...
字节跳动 EB 级 Iceberg 数据湖的机器学习应用与优化
实现高性能特征读取和高效特征调研、特征工程加速模型迭代。**相关产品**:https://www.volcengine.com/product/flink # 机器学习样本存储:背景与趋势在字节跳动,机器学习模型的应用范围非常广泛。为了支持... 即直接使用 HBase 底层的数据格式作为索引并托管在 Iceberg 元数据中,优化了性能和并发性等。相比其他索引,使用 HFile 文件索引能够减少运维组件、复用存储资源,并且能够避免脉冲流量读写问题。整个写入流程上看...
字节跳动基于数据湖技术的近实时场景实践
业界目前有多套开源的数据湖的实现方案,字节数据湖是字节跳动基于 Apache Hudi 深度定制,适用于商用生产的数据湖存储方案,其特性如下:- 字节数据湖为打通实时计算与离线计算 ,及实时数据、离线数据共通复用提供... 导入到实时的 Redis 或 HBase 存储,然后复用到实时计算中。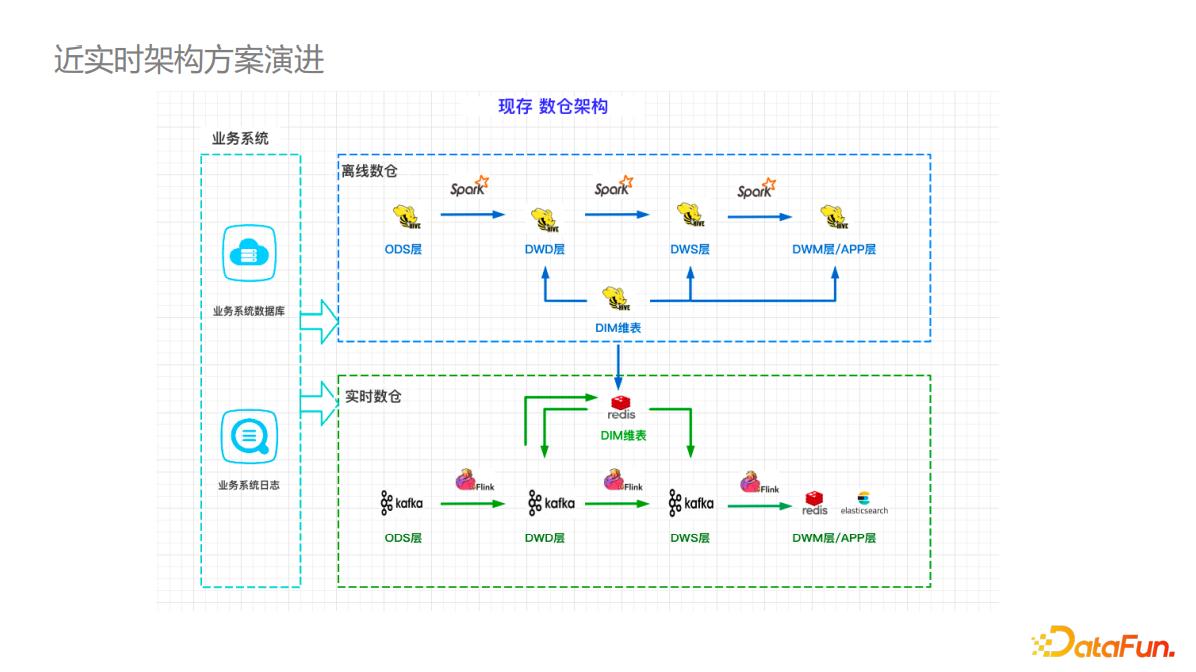 下图是基于Hudi...
字节跳动流式数仓和实时服务分析的思考与实践
Merge Tree 是用于实时计算核心的内部基础,FlinkState,ClickHouse 及 HBase,包括 HSAP,都是基于 Merge Tree 的。Merge Tree 本身支持大量快速更新的能力,包括更新写增量文件,以及基于 Sorted File 按需 Merge。 ... 计算分为流计算链路和批计算链路,两条链路有各自独立的计算集群和调度,数据有不同的入口和不同的处理方式,这种模式下做数据的端到端一致性挑战很大,成本非常高。 **实现流批一体后,通过自动调度资源,自动调度流...
