hbase的四维定位简述
 社区干货
社区干货
基于国产化环境的金融级业务系统性能优化实践|社区征文
它提供了一个成熟的企业级SQL on HBase解决方案。Trafodion的主要设计思想是处理operational类型的工作负载,或者是传统的OLTP应用。2006年,NonStop SQL的OLAP分支Neoview诞生,而Trafodion直接继承于Neoview和其后续... 定位问题出现在哪个部分,然后集中解决。在服务器硬件、操作系统、应用程序、网络环境等方面,影响性能最大的是应用程序和操作系统两个方面,因为这两个方面出现的问题不易察觉,隐蔽性很强。而硬件、网络方面只要出...
干货 | 这样做,能快速构建企业级数据湖仓
Hive Metastore 定位为公共服务,用户可以选择独占或共享 Metastore 实例。如果用户期望节省成本,或者为公司用户,那么两个部门之间可以使用一个 Hive Metastore service;而对于一些要求比较高的部门,可以单独建一个... 并把提取出来的特征返存到湖仓或者 HBase 等键值存储。基于离线的数据可以进行离线训练,如通过 Spark MLlib 搭建传统的机型学习模型,或者通过 TensorFlow 进行深度模型的训练,把深度训练出来的模型部署到模型...
干货|Hudi Bucket Index 在字节跳动的设计与实践
**HBase Index** | 维护每一个 Record Key 的 Partition Path 和 File Group,在插入 File Group定位阶段所有 task 向 HBase 发送 Batch Get 请求,获取 Record Key 的 Mapping 信息。 | 重量级,Record Key 到 File Group 的 mapping 记录在 HBase。对于小批次的keys,查询效率高,依赖外部系统。Hbase Index 会引入额外的外部系统,从而提升运维代价。 |在本文中,我们将介绍一个新的 Hudi 索引模块 Bucket Index 在字节跳动的设...
干货|Hudi Bucket Index 在字节跳动的设计与实践
**HBase Index** | 维护每一个 Record Key 的 Partition Path 和 File Group,在插入 File Group定位阶段所有 task 向 HBase 发送 Batch Get 请求,获取 Record Key 的 Mapping 信息。 | 重量级,Record Key 到 File Group 的 mapping 记录在 HBase。对于小批次的keys,查询效率高,依赖外部系统。Hbase Index 会引入额外的外部系统,从而提升运维代价。 |在本文中,我们将介绍一个新的 Hudi 索引模块 Bucket Index 在字节跳动...
 特惠活动
特惠活动
 hbase的四维定位简述-优选内容
hbase的四维定位简述-优选内容
 hbase的四维定位简述-相关内容
hbase的四维定位简述-相关内容
基于国产化环境的金融级业务系统性能优化实践|社区征文
它提供了一个成熟的企业级SQL on HBase解决方案。Trafodion的主要设计思想是处理operational类型的工作负载,或者是传统的OLTP应用。2006年,NonStop SQL的OLAP分支Neoview诞生,而Trafodion直接继承于Neoview和其后续... 定位问题出现在哪个部分,然后集中解决。在服务器硬件、操作系统、应用程序、网络环境等方面,影响性能最大的是应用程序和操作系统两个方面,因为这两个方面出现的问题不易察觉,隐蔽性很强。而硬件、网络方面只要出...
干货 | 这样做,能快速构建企业级数据湖仓
Hive Metastore 定位为公共服务,用户可以选择独占或共享 Metastore 实例。如果用户期望节省成本,或者为公司用户,那么两个部门之间可以使用一个 Hive Metastore service;而对于一些要求比较高的部门,可以单独建一个... 并把提取出来的特征返存到湖仓或者 HBase 等键值存储。基于离线的数据可以进行离线训练,如通过 Spark MLlib 搭建传统的机型学习模型,或者通过 TensorFlow 进行深度模型的训练,把深度训练出来的模型部署到模型...
干货|Hudi Bucket Index 在字节跳动的设计与实践
**HBase Index** | 维护每一个 Record Key 的 Partition Path 和 File Group,在插入 File Group定位阶段所有 task 向 HBase 发送 Batch Get 请求,获取 Record Key 的 Mapping 信息。 | 重量级,Record Key 到 File Group 的 mapping 记录在 HBase。对于小批次的keys,查询效率高,依赖外部系统。Hbase Index 会引入额外的外部系统,从而提升运维代价。 |在本文中,我们将介绍一个新的 Hudi 索引模块 Bucket Index 在字节跳动的设...
干货|Hudi Bucket Index 在字节跳动的设计与实践
**HBase Index** | 维护每一个 Record Key 的 Partition Path 和 File Group,在插入 File Group定位阶段所有 task 向 HBase 发送 Batch Get 请求,获取 Record Key 的 Mapping 信息。 | 重量级,Record Key 到 File Group 的 mapping 记录在 HBase。对于小批次的keys,查询效率高,依赖外部系统。Hbase Index 会引入额外的外部系统,从而提升运维代价。 |在本文中,我们将介绍一个新的 Hudi 索引模块 Bucket Index 在字节跳动...
数据库顶会 VLDB 2023 论文解读 - Krypton: 字节跳动实时服务分析 SQL 引擎设
结果通过 ETL 导入到 HBase/ES/ClickHouse 等系统提供在线的查询服务。对于实时链路, 数据会直接进入到 HBase/ES 提供高并发低时延的在线查询服务,另一方面数据会流入到 ClickHouse/Druid 提供在线的查询聚合服务。... 为了快速定位数据的物理位置,用户可以在 DDL 中选择合适的 Index,Krypton 支持的 Index 如下:1. Ordinal Index:根据行号快速查找目标的 Data Page。1. Sparse Index:Min/Max、Bloom Filter 以及 Ribbon Filte...
字节跳动基于数据湖技术的近实时场景实践
导入到实时的 Redis 或 HBase 存储,然后复用到实时计算中。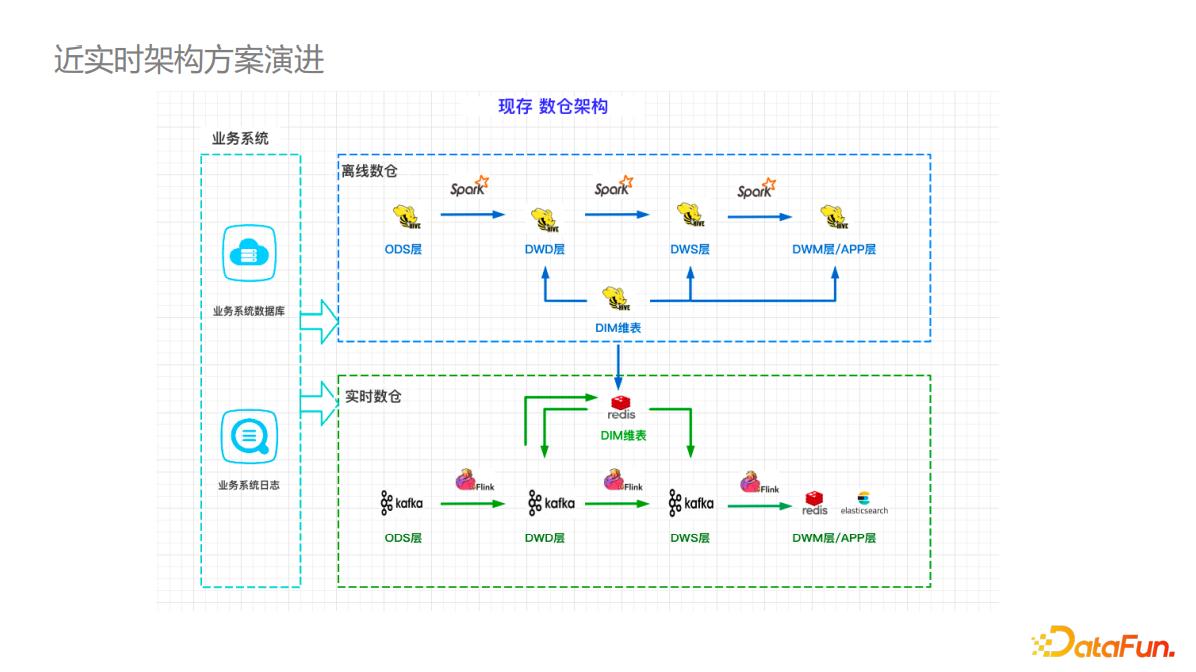 下图是基于Hudi... 有助于问题的快速定位和解决,保障数据产出的SLA。在实践中,如果仅仅监控计算组件:比如监控 Flink、Spark 等组件metrics 、Kafka 的lag、数据库性能,并不能有效的保障数据产品的SLA。对于实时计算链路来说,由于兜底...
数据库顶会 VLDB 2023 论文解读:Krypton: 字节跳动实时服务分析 SQL 引擎设计
结果通过 ETL 导入到 HBase/ES/ClickHouse 等系统提供在线的查询服务。对于实时链路, 数据会直接进入到 HBase/ES 提供高并发低时延的在线查询服务,另一方面数据会流入到 ClickHouse/Druid 提供在线的查询聚合服务。... 为了快速定位数据的物理位置,用户可以在 DDL 中选择合适的 Index,Krypton 支持的 Index 如下:1. Ordinal Index:根据行号快速查找目标的 Data Page。2. Sparse Index:Min/Max、Bloom Filter 以及 Ribbon Filte...
干货|Hudi Bucket Index 在字节跳动的设计与实践
更新的数据可以快速被定位到对应的 File Group,以下面的官方的示意图为例,1. 避免读取不需要的文件2. 避免更新不必要的文件3. 无需将更新数据与历史数据做分布式关联,只需要在 File Group 内做合并