hbasepid找不到
 社区干货
社区干货
基于国产化环境的金融级业务系统性能优化实践|社区征文
它提供了一个成熟的企业级SQL on HBase解决方案。Trafodion的主要设计思想是处理operational类型的工作负载,或者是传统的OLTP应用。2006年,NonStop SQL的OLAP分支Neoview诞生,而Trafodion直接继承于Neoview和其后续... 当CPU计算所需要的数据并没有读取到缓存或者内存中时,就需要从磁盘读取,会导致进程出现数据等待,影响计算效率。所以IO子系统优化最主要的目的就是减少CPU计算数据从磁盘读取的等待事件,从而提升计算效率。一般情况...
「火山引擎」数据中台产品双月刊 VOL.05
HBase和ByteHouse Connector,支持MySQL Sink,优化多个配置,达到开箱即用;支持avro,csv,debezium-json和avro-confluent等格式;Presto、Trino优化进入客户端方式。- 新增软件栈 2.2.0:HBase集群中集成Knox组件用于... =&rk3s=8031ce6d&x-expires=1715098833&x-signature=qdmAb%2BIPidukJae6%2BPTHMUMCKuQ%3D)### **【干货】揭秘字节跳动基于 Doris 的实时数仓探索**【简介】本文详细介绍了火山引擎 EMR 是一款怎样的产品,火山引...
一文读懂火山引擎云数据库产品及选型
宽列型 NoSQL 数据库(以 HBase 为代表)、时序型 NoSQL 数据库(以 InfluxDB 为代表)以及图 NoSQL 数据库(以 Neo4j 为代表)**。虽然这些类型都属于 NoSQL 数据库范畴,但是不同类型的 NoSQL 数据库所适用的场景各有不... 找不到一个可以包打天下的数据库。如果真有“数据库银弹”,那也就不必做数据库选型了,直接用银弹就行,数据库世界也就不会出现如此多种类的数据库技术和产品类型了。所以需要根据不同的业务场景、业务需求去选择...
字节跳动基于 Hudi 的机器学习应用场景
在没有使用数据湖之前,用户做离线特征调研之前需要复制样本,修改并另存一份。其中消耗了巨大的计算和存储资源,伴随样本量的增大,这样的方案将消耗数个 EB 的存储,使得迭代变得不可能。我们基于 Hudi 实现了 ColumnFamily 的能力。这个方案受到了经典 BigTable 存储 Apache HBase 的启发,将 IO pattern 不同的数据使用不同的文件进行存储,以减少不必要的读写放大。原理是将同一个 FileGroup 的不同列数据存储在不同的文件中,在读...
 特惠活动
特惠活动
 hbasepid找不到-优选内容
hbasepid找不到-优选内容
 hbasepid找不到-相关内容
hbasepid找不到-相关内容
DataLeap 数据资产实战:如何实现存储优化?
排除了 HBase 和 Cassandra;- 从当前数据量与将来的可扩展性考虑,单机方案不可选,排除了 BerkeleyDB;- 同样因为人力成本,需要做极大量开发改造的方案暂时不考虑,排除了 Redis。 最终我们挑选了 MySQL ... 而且在处理过程中有很长一段时间和数据库并没有交互,数据库连接一直空闲。**解决办法**:- 调整 mysql server 端的 wait_timeout 参数,已调整到 3600s。- 调整 client 端数据库配置中连接的最小空闲时间,已...
Linux 系统CPU使用率变高,但找不到占用CPU的应用,如何进行排查
找到占用CPU较高的进程时,如何进行排查# 问题分析当使用top观察到整体CPU使用率很高,但找不到占用CPU较高的进程时,可以考虑进程不断重启或者短时进程导致的问题。# 解决方案1、先用top查看机器的整体状况,如下... 使用top并没有找到占用CPU高的进程。2、继续使用pidstat进行分析,如下: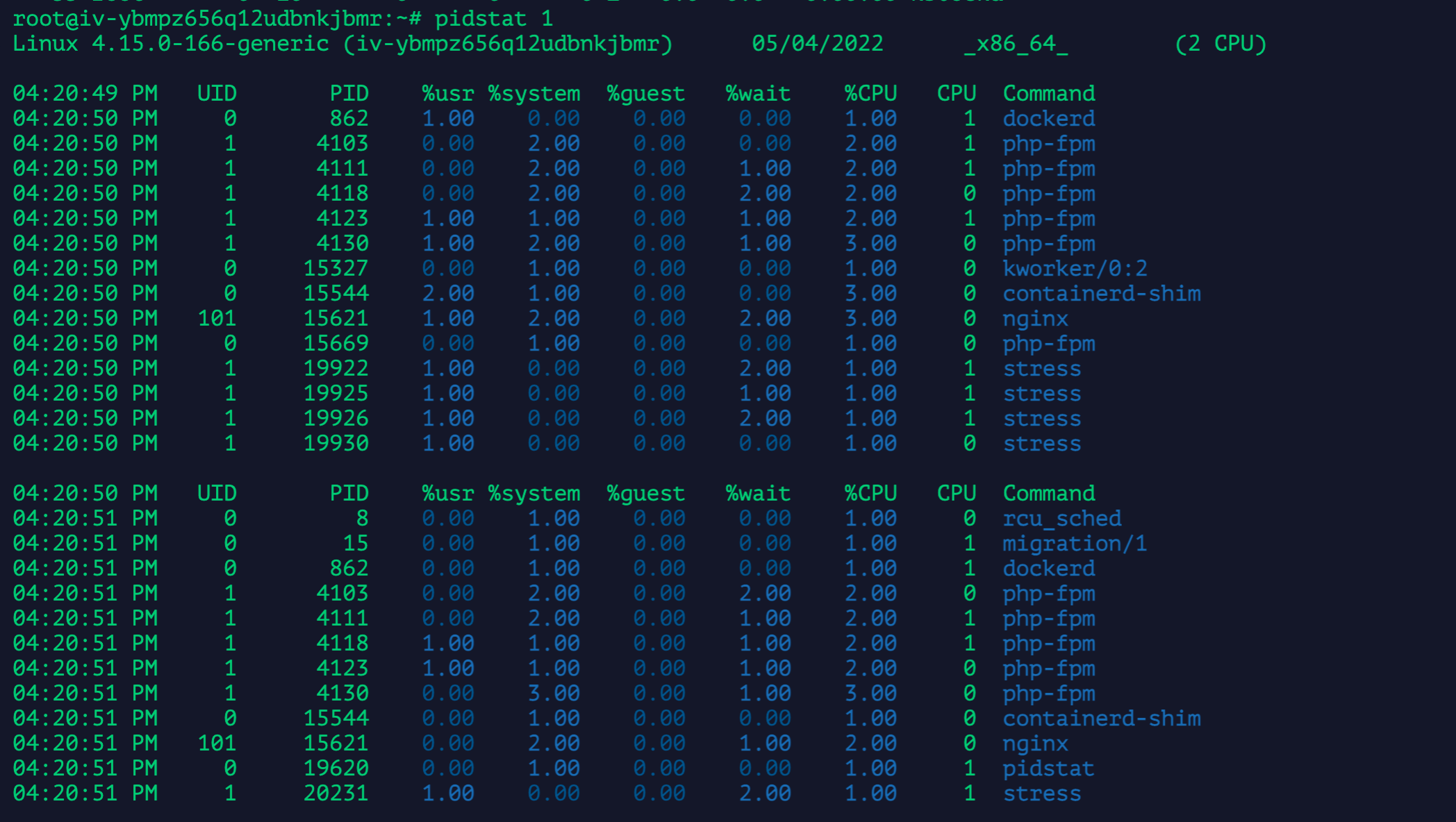我们发现,所有进程的...
在大数据量中 Spark 数据倾斜问题定位排查及解决|社区征文
经过测试之后发现没有问题,后面数仓整体就迁到了Iceberg中。这次任务的执行语句描述:将ODS层的表按照主键去重后插入到DWD层中,表为分区表,DWD层表格式是iceberg格式。```sqlinsert overwrite table hive_prod.dwd_xml.dwd_xml_order_cnselect pid,app_date_o,app_date_s,app_docnumber_o,app_docnumber_s,app_number,filename...,from_unixtime(unix_timestamp(),'yyyy-MM-dd HH:dd:ss') as update_ti...
干货 | 看 SparkSQL 如何支撑企业级数仓
可以找出完全替代 Hive 的组件寥寥无几,但是并不等于 Hive 在目前阶段是一个完全满足企业业务要求的组件,很多时候选择 Hive 出发点并不是因为 Hive 很好的支持了企业需求,单单是因为暂时找不到一个能支撑企业诉求的... MapReduce 和 HBase,形成了早期 Hadoop 的三大利器。然而这三大利器更聚焦在异构数据的信息提取处理上,没有提供对结构化数据很友好的类似 SQL 语法的分析入口,同时在编程态的支撑也不够友好,只有 Map 和 Reduce ...
一文读懂火山引擎云数据库产品及选型
宽列型NoSQL数据库(以HBase为代表)、时序型NoSQL数据库(以InfluxDB为代表)以及图NoSQL数据库(以Neo4j为代表)。虽然这些类型都属于NoSQL数据库范畴,但是不同类型的NoSQL数据库所适用的场景各有不同,需要根据业务特征... 找不到一个可以包打天下的数据库。如果真有“数据库银弹”,那也就不必做数据库选型了,直接用银弹就行,数据库世界也就不会出现如此多种类的数据库技术和产品类型了。所以需要根据不同的业务场景、业务需求去选择...
Flink on K8s 企业生产化实践|社区征文
Hbase 、关系型数据库等大数据 ODS ( Operational Data store ) 层进行快速的数据 ETL ,将数据抽取到特征平台进行管理,并统一了数据出口,供数据科学家、数据工程师、机器学习工程师做算法模型的数据测试、训练、推... 它也会告诉 K8s Cluster 释放没有使用的资源。相当于 Flink 用很原生的方式了解到 K8s Cluster 的存在,并知晓何时申请资源,何时释放资源。- Native 是相对于 Flink 而言的,借助 Flink 的命令就可以达到自治的一...
Kubernetes 观测:基于 eBPF 的云原生深度可观测性实践
并没有真正解决可观测性面临的问题。因此我们可能需要实现第三层:“**因果可观测性**”。它要求我们能够回答:* 问题在整个堆栈中是如何传播的?* 问题根因究竟在哪?* 问题开始的时候堆栈是什么样子的?* 问题... pid 等信息进行反查即可。其次是远端 IP 的关联。当远端 IP、Netns 在节点上找不到的情况,我们就会 fallback 到基于 Kubernetes APIServer的方案来获取。而为了避免每个节点都直连 Kubernetes APIServer,造...
适用于线上内存监控框架KOOM源码分析 | 社区征文
找不到头绪,就需要APM出马了。对于App的性能,像CPU、流量、电量、内存、crash、ANR,这些都会是监控的点,尤其是当App发生崩溃的时候,需要回捞到当前用户的日志加以分析,找到此问题崩溃的堆栈,完成修复。否则就像是... **没有连续的内存空间分配**;这个主要是因为内存碎片过多(标记清除算法),导致即便内存够用,也会造成OOM;\(3)**打开过多的文件**;如果有碰到这个异常OOM:open to many file的伙伴,应该就知道了;\(4)**虚拟内存空间...
一文读懂火山引擎云数据库产品及选型
由于没有 Schema 的特性,可以随意地存储与读取数据,因此文档型 NoSQL 数据库解决了关系型数据库表结构扩展不方便的问题。宽列型 NoSQL 数据库,主要用在大数据、OLAP 场景。其特点是可以提供海量的存储容量,PB 级... 找不到一个可以包打天下的数据库。如果真有“数据库银弹”,那也就不必做数据库选型了,直接用银弹就行,数据库世界也就不会出现如此多种类的数据库技术和产品类型了。所以需要根据不同的业务场景、业务需求去选...
