hbasehdfs区别
 社区干货
社区干货
9年演进史:字节跳动 10EB 级大数据存储实战
HBase,日志服务,Kafka 数据存储 - Yarn,Flink 的计算框架平台数据 - Spark,MapReduce 的计算相关数据存储![]()# **字节跳动特色的** **HDFS** **架构**在深入相关的技术细节之前,我们先看看字节跳动的 HDFS 架构。## **架构介绍** 字节跳动 HDFS 架构 ### **接入层**接入层是字节版 HDFS 区别于社区版本最大的一层,社区版本中并无这一层定义。在字节跳动的落地实践中,由于集群的节点过于庞大,我们需要非常多的 N...
我的大数据学习总结 |社区征文
然后着重学习Hadoop核心技术如HDFS和MapReduce;接触数据库Hive后,学习数据流技术Kafka和分布式协调服务Zookeeper。深入研究Yarn和求执行引擎Spark。此外还了解其他技术如HBase、Sqoop等。同时学习计算机网络知识和... 学习难点: SQL on RDD与SQL on Dataset/DataFrame的区别。在学习SparkSQL时,我发现它支持两种SQL查询方式:使用SQL对RDD进行查询,以及使用SQL对Dataset/DataFrame进行查询。区分两个概念变得很重要。为了理解区别...
9年演进史:字节跳动 10EB 级大数据存储实战
**HDFS** **承载的主要业务如下:*** Hive,HBase,日志服务,Kafka 数据存储* Yarn,Flink 的计算框架平台数据* Spark,MapReduce 的计算相关数据存储**02****字节跳动特色的 HDFS 架构**... 字节跳动 HDFS 架构### **接入层**接入层是字节版 HDFS 区别于社区版本最大的一层,社区版本中并无这一层定义。在字节跳动的落地实践中,由于集群的节点过于庞大,我们需要非常多的 NameNode 实现联邦机制...
Hive SQL 底层执行过程 | 社区征文
Hive直接访问存储在 HDFS 中或者 HBase 中的文件,通过 MapReduce、Spark 或 Tez 执行查询。我们今天来聊的就是 Hive 底层是怎样将我们写的 SQL 转化为 MapReduce 等计算引擎可识别的程序。了解 Hive SQL 的底层编... 在reduce阶段保存LastKey区分不同的key。MapReduce的过程如下: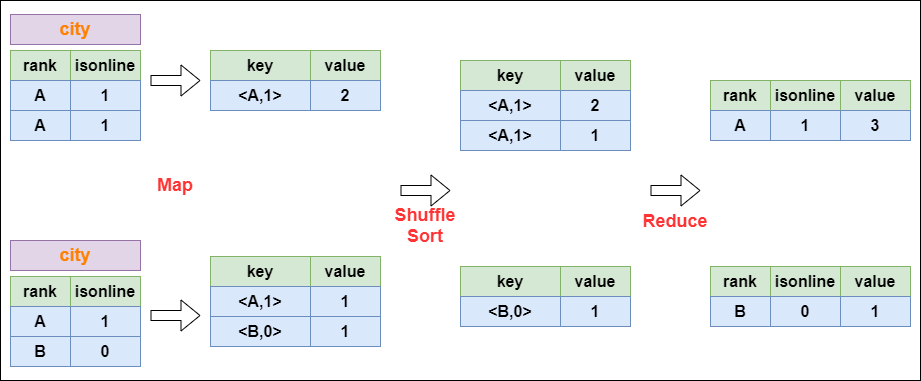#### 3. Distinct的实现原理以下面这个SQL为例,讲解 dist...
 特惠活动
特惠活动
 hbasehdfs区别-优选内容
hbasehdfs区别-优选内容
 hbasehdfs区别-相关内容
hbasehdfs区别-相关内容
CreateDBInstance
MasterSpec String 是 hbase.x1.medium Master 节点的规格码。 说明 关于 Master 节点所支持的规格信息,请参见实例规格。 Master 节点数量固定为 2,不支持增减。 RSCount Integer 是 4 RegionServer 节点数量。 取值范围:2~100。 RSSpec String 是 hbase.x1.large RegionServer 节点的规格码。 说明 关于 RegionServer 节点所支持的规格信息,请参见实例规格。 StorageType String 是 HdfsHdd 实例的存储类型,...
支持的数据源
HBase ✅ ✅ ✅ 大数据存储 HDFS ✅ ✅ 大数据存储 Hive(on HDFS) ✅ ✅ ✅ 大数据存储 Hive(on TOS) ✅ ✅ ✅ ✅ 大数据存储 StarRocks ✅ ✅ ✅ ✅ 大数据存储 Doris ✅ ✅ ✅ 大数据存储 MaxCompute ✅ ✅ 大数据存储 Kudu ✅ ✅ ✔️ 大数据存储 CloudFS ✅ ✅ MPP数据库 ClickHouse ✅ ✅ ✅ MPP数据库 ByteHouse CE ✅ ✅ ✅ ✅ ...
基础使用
本文将为您介绍Spark支持弹性分布式数据集(RDD)、Spark SQL、PySpark和数据库表的基础操作示例。 1 使用前提已创建E-MapReduce(简称“EMR”)集群,详见:创建集群。 2 RDD基础操作Spark围绕着 RDD 的概念展开,RDD是可以并行操作的元素的容错集合。Spark支持通过集合来创建RDD和通过外部数据集构建RDD两种方式来创建RDD。例如,共享文件系统、HDFS、HBase或任何提供Hadoop InputFormat的数据集。 2.1 创建RDD示例:通过集合来创建RDD ...
配置数据源
配置 BMQ 数据源 配置 ByteHouse 企业版 数据源 配置 ByteHouse 云数仓版 数据源 配置 ClickHouse 数据源 配置 CloudFS 数据源 配置 DataSail 数据源 配置 Doris 数据源 配置 Elasticsearch 数据源 配置 FTP/SFTP 数据源 配置 GaussDB 数据源 配置 GBase8S 数据源 配置 Greenplum 数据源 配置 HBase 数据源 配置 HDFS 数据源 配置 Hive 数据源 配置 Kafka 数据源 配置 Kudu 数据源 配置 LarkSheet 数据源 配置 LAS 数据源 配置...
EMR-2.1.1 版本说明
环境信息 系统环境版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.7.3 Java ByteOpenJDK 1.8.0_352 应用程序版本 Hadoop集群 HBase集群 Flume 1.9.0 - OpenLDAP 2.4.58 2.4.58 Ranger 1.2.0 - ZooKeeper 3.7.0 3.7.0 Flink 1.15.1 - HDFS 2.10.2 2.10.2 MapReduce2 2.10.2 - YARN 2.10.2 - Airflow 2.4.2 - Hive 2.3.9 - Hue 4.9.0 - Knox 1.5.0 - Presto 0.267 - Trino 392 - Spark 2.4.8 - Sqoop 1.4.7 - Te...
我的大数据学习总结 |社区征文
然后着重学习Hadoop核心技术如HDFS和MapReduce;接触数据库Hive后,学习数据流技术Kafka和分布式协调服务Zookeeper。深入研究Yarn和求执行引擎Spark。此外还了解其他技术如HBase、Sqoop等。同时学习计算机网络知识和... 学习难点: SQL on RDD与SQL on Dataset/DataFrame的区别。在学习SparkSQL时,我发现它支持两种SQL查询方式:使用SQL对RDD进行查询,以及使用SQL对Dataset/DataFrame进行查询。区分两个概念变得很重要。为了理解区别...
服务概述
查看服务概述信息在集群详情页,点击 服务列表 查看已开通的服务,并选择需要查看概述信息的服务,单击 服务名称 进入服务详情。 在 服务概述 页面会展示该服务的运行情况的概述信息,概述信息分为文字指标信息和图表指标信息两种。(服务概述功能现支持以下服务:HDFS、Hive、YARN、HBase、Kafka、Presto、Trino、Ranger) 文字指标显示服务组件此刻的状态。 图表指标显示服务组件在过去一段时间内的状态,点击可切换查看信息的时间段...
EMR-2.1.0版本说明
环境信息 系统环境版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.7.3 Java ByteOpenJDK 1.8.0_302 应用程序版本 Hadoop集群 HBase集群 Flume 1.9.0 - OpenLDAP 2.4.58 2.4.58 Ranger 1.2.0 - ZooKeeper 3.7.0 3.7.0 Flink 1.15.1 - HDFS 2.10.2 2.10.2 MapReduce2 2.10.2 - YARN 2.10.2 - Airflow 2.4.2 - Hive 2.3.9 - Hue 4.9.0 - Knox 1.5.0 - Presto 0.267 - Trino 392 - Spark 2.4.8 - Sqoop 1.4.7 - Te...
9年演进史:字节跳动 10EB 级大数据存储实战
**HDFS** **承载的主要业务如下:*** Hive,HBase,日志服务,Kafka 数据存储* Yarn,Flink 的计算框架平台数据* Spark,MapReduce 的计算相关数据存储**02****字节跳动特色的 HDFS 架构**... 字节跳动 HDFS 架构### **接入层**接入层是字节版 HDFS 区别于社区版本最大的一层,社区版本中并无这一层定义。在字节跳动的落地实践中,由于集群的节点过于庞大,我们需要非常多的 NameNode 实现联邦机制...
