查询hbase并返回结果
 社区干货
社区干货
数据库顶会 VLDB 2023 论文解读 - Krypton: 字节跳动实时服务分析 SQL 引擎设
结果通过 ETL 导入到 HBase/ES/ClickHouse 等系统提供在线的查询服务。对于实时链路, 数据会直接进入到 HBase/ES 提供高并发低时延的在线查询服务,另一方面数据会流入到 ClickHouse/Druid 提供在线的查询聚合服务。这带来的问题就像引言中所说,数据被冗余存储了多份,导致了很多一致性问题,也造成了大量的资源浪费。为了解决这个问题,我们设计了 Krypton(HSAP),系统的设计目标主要有几个点:1. 可伸缩。我们希望设计一款能够应对...
数据库顶会 VLDB 2023 论文解读:Krypton: 字节跳动实时服务分析 SQL 引擎设计
结果通过 ETL 导入到 HBase/ES/ClickHouse 等系统提供在线的查询服务。对于实时链路, 数据会直接进入到 HBase/ES 提供高并发低时延的在线查询服务,另一方面数据会流入到 ClickHouse/Druid 提供在线的查询聚合服务。这带来的问题就像引言中所说,数据被冗余存储了多份,导致了很多一致性问题,也造成了大量的资源浪费。为了解决这个问题,我们设计了 Krypton(HSAP),系统的设计目标主要有几个点:1. 可伸缩。我们希望设计一款能够应...
9年演进史:字节跳动 10EB 级大数据存储实战
HBase,日志服务,Kafka 数据存储 - Yarn,Flink 的计算框架平台数据 - Spark,MapReduce 的计算相关数据存储![]()# **字节跳动特色的** **HDFS** **架构**在深入相关的技术细节之前,我们先看看字节跳动的 H... 并且周期性将自己所存储的副本信息汇报给 Name Node。这个过程对 Federation 中的每个集群都是独立完成的。在心跳汇报的返回结果中,会携带 Name Node 对 Data Node 下发的指令。例如,需要将某个副本拷贝到另外一台...
ELT in ByteHouse 实践与展望
实际SQL查询时,可以直接用里面的cube或视图做替换,之后直接返回。- **流批一体** **派**:如Flink、Risingwave。在数据流进时,针对一些需要出报表或者需要做大屏的数据直接内存中做聚合。聚合完成后,将结果写入HBase或MySQL中再去取数据,将数据取出后作展示。Flink还会去直接暴露中间状态的接口,即queryable state,让用户更好的使用状态数据。但是最后还会与批计算的结果完成对数,如果不一致,需要进行回查操作,整个过程考验运维...
 特惠活动
特惠活动
 查询hbase并返回结果-优选内容
查询hbase并返回结果-优选内容
 查询hbase并返回结果-相关内容
查询hbase并返回结果-相关内容
数据库顶会 VLDB 2023 论文解读 - Krypton: 字节跳动实时服务分析 SQL 引擎设
结果通过 ETL 导入到 HBase/ES/ClickHouse 等系统提供在线的查询服务。对于实时链路, 数据会直接进入到 HBase/ES 提供高并发低时延的在线查询服务,另一方面数据会流入到 ClickHouse/Druid 提供在线的查询聚合服务。这带来的问题就像引言中所说,数据被冗余存储了多份,导致了很多一致性问题,也造成了大量的资源浪费。为了解决这个问题,我们设计了 Krypton(HSAP),系统的设计目标主要有几个点:1. 可伸缩。我们希望设计一款能够应对...
数据库顶会 VLDB 2023 论文解读:Krypton: 字节跳动实时服务分析 SQL 引擎设计
结果通过 ETL 导入到 HBase/ES/ClickHouse 等系统提供在线的查询服务。对于实时链路, 数据会直接进入到 HBase/ES 提供高并发低时延的在线查询服务,另一方面数据会流入到 ClickHouse/Druid 提供在线的查询聚合服务。这带来的问题就像引言中所说,数据被冗余存储了多份,导致了很多一致性问题,也造成了大量的资源浪费。为了解决这个问题,我们设计了 Krypton(HSAP),系统的设计目标主要有几个点:1. 可伸缩。我们希望设计一款能够应...
9年演进史:字节跳动 10EB 级大数据存储实战
HBase,日志服务,Kafka 数据存储 - Yarn,Flink 的计算框架平台数据 - Spark,MapReduce 的计算相关数据存储![]()# **字节跳动特色的** **HDFS** **架构**在深入相关的技术细节之前,我们先看看字节跳动的 H... 并且周期性将自己所存储的副本信息汇报给 Name Node。这个过程对 Federation 中的每个集群都是独立完成的。在心跳汇报的返回结果中,会携带 Name Node 对 Data Node 下发的指令。例如,需要将某个副本拷贝到另外一台...
ELT in ByteHouse 实践与展望
实际SQL查询时,可以直接用里面的cube或视图做替换,之后直接返回。- **流批一体** **派**:如Flink、Risingwave。在数据流进时,针对一些需要出报表或者需要做大屏的数据直接内存中做聚合。聚合完成后,将结果写入HBase或MySQL中再去取数据,将数据取出后作展示。Flink还会去直接暴露中间状态的接口,即queryable state,让用户更好的使用状态数据。但是最后还会与批计算的结果完成对数,如果不一致,需要进行回查操作,整个过程考验运维...
分布式数据库TiDB的设计和架构
HBase。但此类数据库的局限在于无法处理交易类数据及复杂业务逻辑的特性,限制其在非互联网领域的发展。**2013年以后**2013年以来,有个新的概念为分布式关系型数据库(NewSQL),它是兼具NoSQL扩展性又不丧失传统关... 通过索引查询的时候,需要先扫描索引,得到对应的行 ID,然后通过行 ID 去取数据,所以可能会涉及到两次网络请求,会有一定的性能开销。如果查询涉及到大量的行,那么扫描索引是并发进行,只要第一批结果已经返回,就可以...
干货 | 这样做,能快速构建企业级数据湖仓
宽表查询性能优异+ Doris:近实时全场景 OLAP 引擎+ Druid:牺牲明细查询,将 OLAP 实时化,毫秒级返回* **流引擎**+ Flink:流计算逐步扩大市场份额+ Kafka SQL:基于 Kafka 实现实时化分析+ Streaming Database... 并把提取出来的特征返存到湖仓或者 HBase 等键值存储。基于离线的数据可以进行离线训练,如通过 Spark MLlib 搭建传统的机型学习模型,或者通过 TensorFlow 进行深度模型的训练,把深度训练出来的模型部署到模型...
NL2SQL:智能对话在打通人与数据查询壁垒上的探索 | 社区征文
业务人员想要查询相应的结果需要找到数据工程人员完成相关流程。流程比较繁琐,而通过nl2sql技术,则可直接将问题转换成相对应的SQL语句用于相关表的查询并返回结果,因此nl2sql可被用于问答系统,通过配合相关规则及其他语义模型,能够对一些简单常见的用户问题转换成相应的SQL。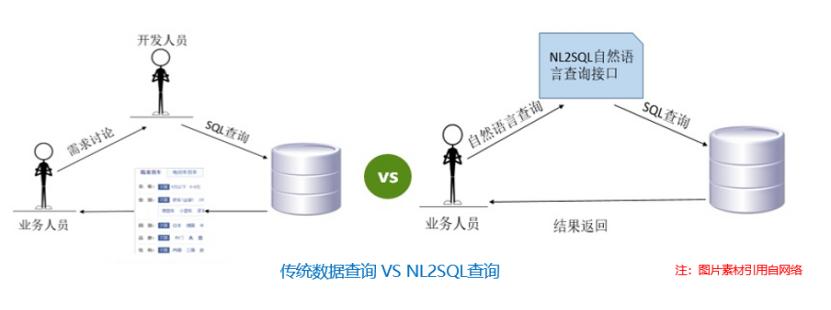### 2、关于NL2SQL的...
20000字详解大厂实时数仓建设 | 社区征文
Hbase、fusion(滴滴自研 KV 存储) 三种存储引擎,对于维表数据比较少的情况可以使用 MySQL,对于单条数据大小比较小,查询 QPS 比较高的情况,可以使用 fusion 存储,降低机器内存资源占用,对于数据量比较大,对维表数据... 针对相同条件查询,后台就直接返回了。**4. 扩容**这里再介绍一下我们的扩容的方案,调研了业内的一些常见方案。比如 HBase,原始数据都存放在 HDFS 上,扩容只是 Region Server 扩容,不涉及原始数据的迁移。但是...
基于ClickHouse的复杂查询实现与优化|社区征文
## 项目背景ClickHouse的执行模式与Druid、ES等大数据引擎类似,其基本的查询模式可分为两个阶段。第一阶段,Coordinator在收到查询后,将请求发送给对应的Worker节点。第二阶段,Worker节点完成计算,Coordinator在收到各Worker节点的数据后进行汇聚和处理,并将处理后的结果返回。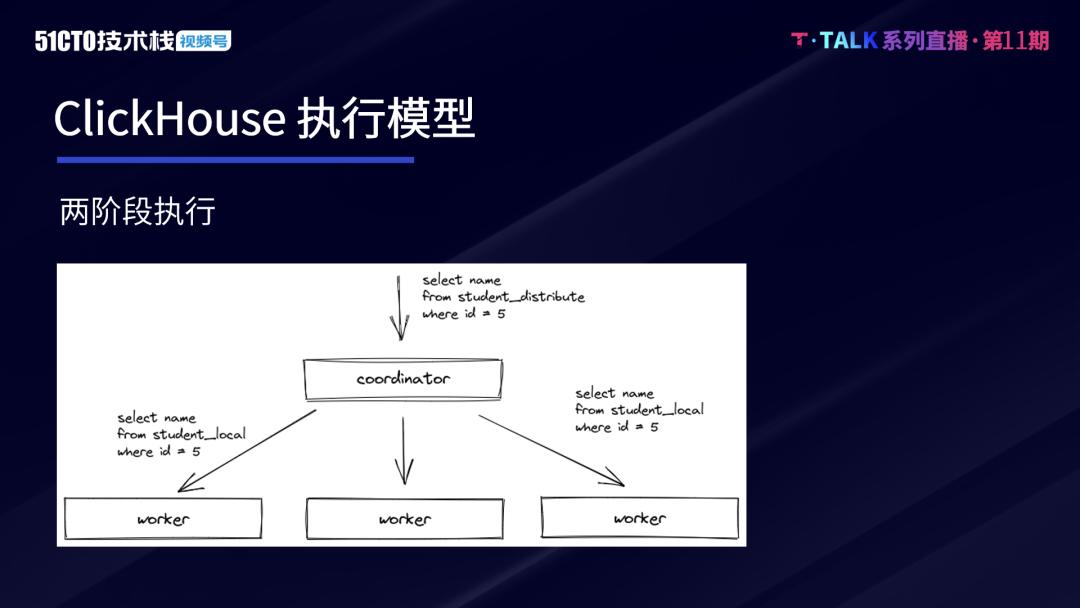两阶段的执行模式能...
