hbase按照顺序返回
 社区干货
社区干货
9年演进史:字节跳动 10EB 级大数据存储实战
顺序和随机读 - 超大数据规模 - 易扩展,容错率高## HDFS 在字节跳动的发展字节跳动已经应用 HDFS 非常长的时间了。经历了 9 年的发展,目前已直接支持了十多种数据平台,间接支持了上百种业务发展。从集群规模和数据量来说,HDFS 平台在公司内部已经成长为总数十万台级别服务器的大平台,支持了 10 EB 级别的数据量。**当前在字节跳动,** **HDFS** **承载的主要业务如下:**- Hive,HBase,日志服务,Kafka 数据存储 -...
数据库顶会 VLDB 2023 论文解读:Krypton: 字节跳动实时服务分析 SQL 引擎设计
结果通过 ETL 导入到 HBase/ES/ClickHouse 等系统提供在线的查询服务。对于实时链路, 数据会直接进入到 HBase/ES 提供高并发低时延的在线查询服务,另一方面数据会流入到 ClickHouse/Druid 提供在线的查询聚合服务。... 读的时候多个版本的数据会按照不同的 Merge 算法合并为一份。Tablet 的 Commit Version 为该 Tablet 下 Rowset 的最大版本号,比如上图中 Tablet 2 的 Commit Version 为 Rowset 5 的版本号 21。每个 Query 都会带...
[数据库系统] 业界列式存储浅析
将数据返回,这个特点非常符合OLTP的workload场景,所以在OLTP场景主要使用行存;但是行存不是完美的,例如需要遍历全表获取符合要求的行,但只取部分列进行分组/排序/聚合等操作,行存就不太适合了,在读取时,由于会读取大量的无效的列的数据,且数据量很大,在存储是系统瓶颈的时代无疑是一大灾难,而且会影响内存中cache的使用效率;在计算时,由于行数据在内存中是顺序存储在一起的,所以对 cpu cache 也很不友好。 列存就是解决上述问题的...
数据库顶会 VLDB 2023 论文解读 - Krypton: 字节跳动实时服务分析 SQL 引擎设
结果通过 ETL 导入到 HBase/ES/ClickHouse 等系统提供在线的查询服务。对于实时链路, 数据会直接进入到 HBase/ES 提供高并发低时延的在线查询服务,另一方面数据会流入到 ClickHouse/Druid 提供在线的查询聚合服务。... 读的时候多个版本的数据会按照不同的 Merge 算法合并为一份。Tablet 的 Commit Version 为该 Tablet 下 Rowset 的最大版本号,比如上图中 Tablet 2 的 Commit Version 为 Rowset 5 的版本号 21。每个 Query 都会带上...
 特惠活动
特惠活动
 hbase按照顺序返回-优选内容
hbase按照顺序返回-优选内容
 hbase按照顺序返回-相关内容
hbase按照顺序返回-相关内容
DescribeDirectConnectVirtualInterfaces
调用DescribeDirectConnectVirtualInterfaces查询符合要求的虚拟接口的详细信息。 调用说明若请求参数不传入VirtualInterfaceIds,则会按照传入的其他参数查询,返回符合条件的虚拟接口。 若请求参数中的非必选参数都... 且N应按照连续的从小到大的顺序。 多个标签键之间用&分隔。 如果传入多个TagFilters.N.Key,多个TagFilters.N.Key之间的关系为逻辑“与(AND)”。 TagFilters.N.Values.N String 否 TagFilters.1.Values.1=value...
数据库顶会 VLDB 2023 论文解读:Krypton: 字节跳动实时服务分析 SQL 引擎设计
结果通过 ETL 导入到 HBase/ES/ClickHouse 等系统提供在线的查询服务。对于实时链路, 数据会直接进入到 HBase/ES 提供高并发低时延的在线查询服务,另一方面数据会流入到 ClickHouse/Druid 提供在线的查询聚合服务。... 读的时候多个版本的数据会按照不同的 Merge 算法合并为一份。Tablet 的 Commit Version 为该 Tablet 下 Rowset 的最大版本号,比如上图中 Tablet 2 的 Commit Version 为 Rowset 5 的版本号 21。每个 Query 都会带...
DescribeDirectConnectConnections
调用DescribeDirectConnectConnections查询符合要求的物理专线的详细信息。 调用说明若请求参数不传入DirectConnectConnectionIds,则会按照传入的其他参数查询,返回符合条件的物理专线。 若请求参数中的非必选参数... 且N应按照连续的从小到大的顺序。 多个标签键之间用&分隔。 如果传入多个TagFilters.N.Key,多个TagFilters.N.Key之间的关系为逻辑“与(AND)”。 TagFilters.N.Values.N String 否 TagFilters.1.Values.1=value...
[数据库系统] 业界列式存储浅析
将数据返回,这个特点非常符合OLTP的workload场景,所以在OLTP场景主要使用行存;但是行存不是完美的,例如需要遍历全表获取符合要求的行,但只取部分列进行分组/排序/聚合等操作,行存就不太适合了,在读取时,由于会读取大量的无效的列的数据,且数据量很大,在存储是系统瓶颈的时代无疑是一大灾难,而且会影响内存中cache的使用效率;在计算时,由于行数据在内存中是顺序存储在一起的,所以对 cpu cache 也很不友好。 列存就是解决上述问题的...
数据库顶会 VLDB 2023 论文解读 - Krypton: 字节跳动实时服务分析 SQL 引擎设
结果通过 ETL 导入到 HBase/ES/ClickHouse 等系统提供在线的查询服务。对于实时链路, 数据会直接进入到 HBase/ES 提供高并发低时延的在线查询服务,另一方面数据会流入到 ClickHouse/Druid 提供在线的查询聚合服务。... 读的时候多个版本的数据会按照不同的 Merge 算法合并为一份。Tablet 的 Commit Version 为该 Tablet 下 Rowset 的最大版本号,比如上图中 Tablet 2 的 Commit Version 为 Rowset 5 的版本号 21。每个 Query 都会带上...
数仓进阶篇@记一次BigData-OLAP分析引擎演进思考过程 | 社区征文
回到DB-Engines Ranking,Hive、HBase、Vertica、Impala、Greenplum、 ClickHouse. 其中,**Hive:** 使用一种类似SQL查询语言,作用在分布式存储系统的文件之上,通常用于进行离线数据处理操作-MapReduce,支持多种不同的执行引擎-Hive on MapReduce、Hive on Tez、Hive on Spark.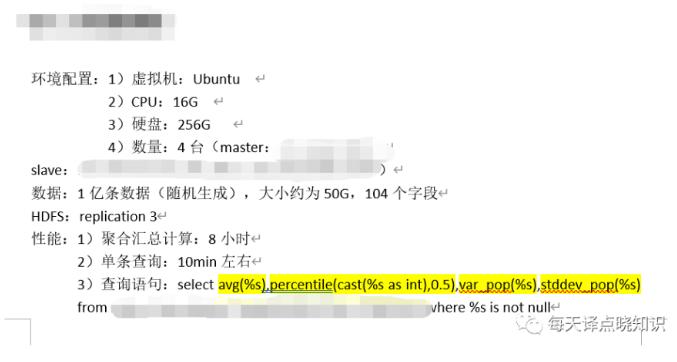**HBase:** ...
我的大数据学习总结 |社区征文
此外还了解其他技术如HBase、Sqoop等。同时学习计算机网络知识和操作系统原理。后面再系统学习关系数据库MySQL和数据仓库理论。学习分布式原理和架构也很重要。这个学习顺序参考了我之前的工作和学习经历情况后订... transactions = transactionData.map(record -> { //解析记录返回Case对象 return new Case(/*fields*/); });```实时计算策略,如交易额是否超过一定阈值等```bashJavaDStream result = transactions.ma...
函数概览
返回一组值中任意一个非空的值。 AVG 函数 AVG(KEY) 计算一组值的算数平均值。 BITWISE_AND_AGG 函数 BITWISE_AND_AGG(KEY) 计算一组值中所有值按位与运算(AND)的结果。 BITWISE_OR_AGG 函数 BITWISE_OR... 按照反向顺序返回字符串。 RPAD 函数 RPAD(KEY, length, lpad_string) 在指定字符串的结尾填充字符,填充到指定长度后返回结果字符串。 RTRIM 函数 RTRIM(KEY) 删除字符串结尾的空格。 SPLIT 函数 SPLIT(...
20000字详解大厂实时数仓建设 | 社区征文
渠道等维度信息需要借助 Hbase,mysql 或者其他 KV 存储等数据库来进行存储。接下来,根据顺风车实时数仓架构图,对每一层建设做具体展开:---#### 1. ODS 贴源层建设根据顺风车具体场景,目前顺风车数据源主要... 按照这个主题关心的维度对数据进行汇总,最后来算业务方需要的汇总指标。在具体操作中,对于 pv 类指标使用 Stream SQL 实现 1 分钟汇总指标作为最小汇总单位指标,在此基础上进行时间维度上的指标累加;对于 uv 类指标...
