txt数据导入hbase
 社区干货
社区干货
万字长文,Spark 架构原理和 RDD 算子详解一网打进! | 社区征文
其中hello.txt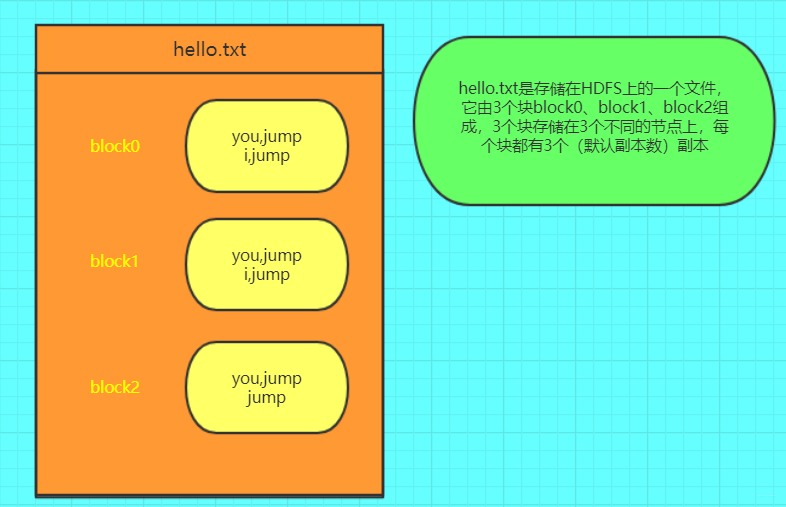## 三、RDD的创建方式### 3.1 通过读取文件生成的由外部存储系统的数据集创建,包括本地的文件系统,还有所有Hadoop支持的数据集,比如HDFS、Cassandra、HBase等```cppscala> val file =...
数据库顶会 VLDB 2023 论文解读 - Krypton: 字节跳动实时服务分析 SQL 引擎设
数据通过 Kafka 流入不同的系统。对于离线链路,数据通常流入到 Spark/Hive 中进行计算,结果通过 ETL 导入到 HBase/ES/ClickHouse 等系统提供在线的查询服务。对于实时链路, 数据会直接进入到 HBase/ES 提供高并发低时延的在线查询服务,另一方面数据会流入到 ClickHouse/Druid 提供在线的查询聚合服务。这带来的问题就像引言中所说,数据被冗余存储了多份,导致了很多一致性问题,也造成了大量的资源浪费。为了解决这个问题,我们设计...
干货 | 这样做,能快速构建企业级数据湖仓
主要介绍了数据湖仓开源趋势、火山引擎 EMR 的架构及特点,以及如何基于火山引擎 EMR 构建企业级数据湖仓。> > > >  特惠活动
特惠活动
 txt数据导入hbase-优选内容
txt数据导入hbase-优选内容
 txt数据导入hbase-相关内容
txt数据导入hbase-相关内容
干货 | 这样做,能快速构建企业级数据湖仓
主要介绍了数据湖仓开源趋势、火山引擎 EMR 的架构及特点,以及如何基于火山引擎 EMR 构建企业级数据湖仓。> > > >  Python2 2.7.16 Python3 3.10.13 Java ByteOpenJDK 1.8.0_352 应用程序版本 Hadoop集群 Flink集群 Kafka集群 HBase集群 StarRocks集群 ClickHouse集群 Op... 在用户管理模块通过IAM用户导入方式导入用户时,修复Ranger中同步的用户名异常问题。 【组件】在管控页面上,对Hive组件服务参数中的元数据库密码进行加密展示。 组件版本 下面列出了 EMR 和此版本一起安装的组件。...
数据库顶会 VLDB 2023 论文解读:Krypton: 字节跳动实时服务分析 SQL 引擎设计
数据通过 Kafka 流入不同的系统。对于离线链路,数据通常流入到 Spark/Hive 中进行计算,结果通过 ETL 导入到 HBase/ES/ClickHouse 等系统提供在线的查询服务。对于实时链路, 数据会直接进入到 HBase/ES 提供高并发低... 元数据也放在了外部的存储系统中,例如:ZK 及分布式 KV 等系统。3. **读写分离**1. Ingestion Server 负责数据的导入,Compaction Server 负责将数据定期 Merge。数据导入后,Ingestion Server 会写 WAL,同时数据进...
EMR-3.6.1 版本说明
环境信息 系统环境版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.10.13 Java ByteOpenJDK 1.8.0_352 应用程序版本 Hadoop集群 Flink集群 Kafka集群 HBase集群 StarRocks集群 ClickHouse集群 Op... hive_metastore 3.1.3 Hive元数据存储服务。 hive_server 3.1.3 用于将 Hive 查询作为 Web 请求接受的服务。 hive_client 3.1.3 Hive命令行客户端。 hdfs_namenode 3.3.4 用于跟踪HDFS文件名和数据块的服务。 hdf...
EMR-3.6.0 版本说明
环境信息 系统环境版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.10.13 Java ByteOpenJDK 1.8.0_352 应用程序版本 Hadoop集群 Flink集群 Kafka集群 HBase集群 StarRocks集群 ClickHouse集群 Op... GPU不支持数据湖格式 组件版本 下面列出了 EMR 和此版本一起安装的组件。 组件 版本 描述 zookeeper_server 3.7.0 用于维护配置信息、命名、提供分布式同步的集中式服务。 zookeeper_client 3.7.0 ZooKeeper命令行...
EMR-2.2.0 版本说明
HBase集群中集成Knox组件用于访问代理;并集成了YARN和MapReduce2; 【组件】Flink引擎支持avro,csv,debezium-json和avro-confluent等格式; 【组件】修复Presto写入TOS的潜在问题; 【组件】Hive适配CFS, 支持外部... 优化Spark引擎和MapReudce的写入性能。 已知问题通过Sqoop从SQL Server导入数据时,存在编码异常问题,如果需要使用此功能可联系售后处理,预计会在后续版本进行优化; 使用Dolphin Scheduler调度Presto数据源项目时...
EMR-2.1.0版本说明
环境信息 系统环境版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.7.3 Java ByteOpenJDK 1.8.0_302 应用程序版本 Hadoop集群 HBase集群 Flume 1.9.0 - OpenLDAP 2.4.58 2.4.58 Ranger 1.2.0 - Z... hive_metastore 2.3.9 Hive元数据存储服务。 hive_server 2.3.9 用于将 Hive 查询作为 Web 请求接受的服务。 hive_client 2.3.9 Hive命令行客户端。 hdfs_namenode 2.10.2 用于跟踪HDFS文件名和数据块的服务。 hd...
一文读懂火山引擎云数据库产品及选型
保证数据强一致性**。业界常见的关系型数据库又分商业数据库与开源数据库,其中主流的商业关系型数据库代表有 Oracle、SQL Server、DB2 等;主流的开源关系型数据库代表有 MySQL、PostgreSQL、MariaDB 等。**NoSQL**,Not Only SQL,"不仅仅是 SQL",广泛应用于以互联网业务为代表的场景。NoSQL 数据库又可以**细分为 KV 型 NoSQL 数据库(以 Redis 为代表)、文档型 NoSQL 数据库(以 MongoDB 为代表)、宽列型 NoSQL 数据库(以 HBase ...
add
概述 /api/knowledge/doc/add 接口用于向已创建的知识库导入文档。 说明 单个知识库的文档数不超过10K个。 对于doc,docx,pdf,pptx类型的文档,大小限制为20M;对于txt类型的文档,大小限制为5M;对于faq.xlsx文件,最多... 请求接口 URI http://api-knowledgebase.ml_platform.cn-beijing.volces.com/api/knowledge/doc/add 统一资源标识符 请求方法 POST 客户端对向量数据库服务器请求的操作类型 请求头 Content-Type: applica...
