hbase根据字段查主键
 社区干货
社区干货
字节跳动实时数据湖构建的探索和实践
用于支持通过数据库变更日志Binlog,将数据变更同步到外部组件的数据库。这种模式目前支持5种数据源,虽然数据源不多,但是任务数量非常庞大,其中包含了很多核心链路,例如各个业务线的计费、结算等,对数据准确性要求非... State索引和Hbase索引来做到高效率的全局索引**。这两个例子说明了不同场景下,索引的选择也会决定了整个表读写性能。Hudi提供多种开箱即用的索引,已经覆盖了绝大部分场景,用户使用成本非常低。### 02 - Merge ...
三范式
1、1NF:保证每列的原子性2、2NF:保证一张表只描述一件事情3、3NF:保证每列都和主键直接相关:**表中的字段和主键直接对应不依靠其他中间字段,说白了就是,决定某字段值的必须是主键**。**什么是三范式**设... 将学生信息与课程信息通过一张中间表关联,很好地解决了上面的几个问题,这就是第二范式的中心----保证一张表只讲一件事情。**第三范式----保证每列都和主键直接相关**第三范式又和第二范式相关,用第三范式的定义...
20000字详解大厂实时数仓建设 | 社区征文
根据顺风车业务过程作为建模驱动,基于每个具体的业务过程特点,构建最细粒度的明细层事实表;结合顺风车分析师在离线侧的数据使用特点,将明细事实表的某些重要维度属性字段做适当冗余,完成宽表化处理,之后基于当前顺... 另外一部分是通过离线任务出仓得到;- DIM 层维度数据主要使用 MySQL、Hbase、fusion(滴滴自研 KV 存储) 三种存储引擎,对于维表数据比较少的情况可以使用 MySQL,对于单条数据大小比较小,查询 QPS 比较高的情况,可以...
字节跳动基于数据湖技术的近实时场景实践
字节数据湖支持 read optimize 和 real time两种 query 模式。同时提供 upsert(主键更新)、append(非主键更新)两种数据更新能力,应用扩展性强,对用户使用友好。# ▌**近实时技术架构**3. ## **近实时场景... 导入到实时的 Redis 或 HBase 存储,然后复用到实时计算中。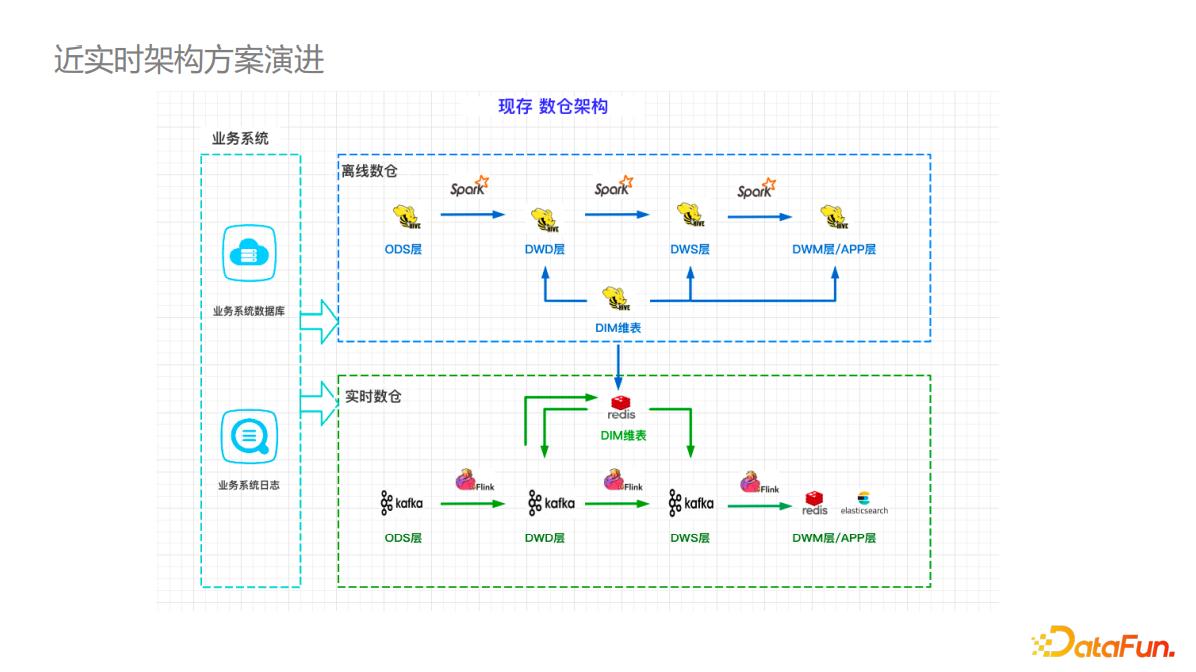 下图是基于Hudi...
 特惠活动
特惠活动
 hbase根据字段查主键-优选内容
hbase根据字段查主键-优选内容
 hbase根据字段查主键-相关内容
hbase根据字段查主键-相关内容
Shell 调用 DataX 最佳实践
HBase、FTP 等各种异构数据源之间稳定高效的数据同步功能。DataX 作为数据同步框架,它将不同数据源的同步抽象为从源头数据源读取数据的 Reader 插件,以及向目标端写入数据的 Writer 插件,使用 DataX 框架可以支持多种数据源类型的数据互通同步工作。详见:https://github.com/alibaba/DataX本文将为您介绍在火山引擎大数据研发治理套件 DataLeap 上,通过 Shell 任务调用 DataX 的方式,将火山引擎云数据库 MySQL 与 文档数据库 Mon...
三范式
1、1NF:保证每列的原子性2、2NF:保证一张表只描述一件事情3、3NF:保证每列都和主键直接相关:**表中的字段和主键直接对应不依靠其他中间字段,说白了就是,决定某字段值的必须是主键**。**什么是三范式**设... 将学生信息与课程信息通过一张中间表关联,很好地解决了上面的几个问题,这就是第二范式的中心----保证一张表只讲一件事情。**第三范式----保证每列都和主键直接相关**第三范式又和第二范式相关,用第三范式的定义...
20000字详解大厂实时数仓建设 | 社区征文
根据顺风车业务过程作为建模驱动,基于每个具体的业务过程特点,构建最细粒度的明细层事实表;结合顺风车分析师在离线侧的数据使用特点,将明细事实表的某些重要维度属性字段做适当冗余,完成宽表化处理,之后基于当前顺... 另外一部分是通过离线任务出仓得到;- DIM 层维度数据主要使用 MySQL、Hbase、fusion(滴滴自研 KV 存储) 三种存储引擎,对于维表数据比较少的情况可以使用 MySQL,对于单条数据大小比较小,查询 QPS 比较高的情况,可以...
字节跳动基于数据湖技术的近实时场景实践
字节数据湖支持 read optimize 和 real time两种 query 模式。同时提供 upsert(主键更新)、append(非主键更新)两种数据更新能力,应用扩展性强,对用户使用友好。# ▌**近实时技术架构**3. ## **近实时场景... 导入到实时的 Redis 或 HBase 存储,然后复用到实时计算中。 下图是基于Hudi...
字节跳动基于数据湖技术的近实时场景实践
同时提供 upsert(主键更新)、append(非主键更新)两种数据更新能力,应用扩展性强,对用户使用友好。# **2. 近实时技术架构**## **2.1 近实时场景特点**近实时场景在一般分为两种类型,第一类是面向分析型的需求... 导入到实时的 Redis 或 HBase 存储,然后复用到实时计算中。