hbase怎么存blob内容
 社区干货
社区干货
火山引擎上云迁移指南(一):上云迁移背景与流程
视频与内容分发、大数据、 人工智能、开发与运维等服务,帮助企业在数字化升级中实现持续增长。- 全方位产品矩阵,提供云基础到智能应用的全链路支撑。- 丰富的解决方案,助你即将应对各类业务难题。- 为全行业客户... 缓存数据库Redis版 | 火山引擎DTS || ^^ | PostgreSQL | 云数据库PostgreSQL版 | 火山引擎DTS || ^^ | MongoDB | 文档数据库MongoDB版 | 火山引擎DTS || ^^ | HBase | 表格数据库HBase版 | 火山引擎DTS |###...
20000字详解大厂实时数仓建设 | 社区征文
数仓的数据明细层内容会非常丰富,处理明细数据外一般还会包含轻度汇总层的概念,另外离线数仓中应用层数据在数仓内部,但实时数仓中,app 应用层数据已经落入应用系统的存储介质中,可以把该层与数仓的表分离;- 应用层... 会使用不同的方式进行存储。比如常见的情况下,明细数据或者汇总数据都会存在 Kafka 里面,但是像城市、渠道等维度信息需要借助 Hbase,mysql 或者其他 KV 存储等数据库来进行存储。接下来,根据顺风车实时数仓架构图...
表设计之数据类型优化 | 社区征文
**将需要存储的货币单位根据小数的位数乘以相应的倍数即可**。假设要存储财务数据精确到万分之一分,则可以把所有金额乘以一百万,然后将结果存储在 BIGINT 里,这样可以同时避免浮点存储计算不精确和 DECIMAL 精确计算代价高的问题。## 5. 字符串类型MysQL 支持多种字符串类型,包括 VARCHAR 和 CHAR 类型、BLOB 和 TEXT 类型、ENUM(枚举)和 SET 类型。### 5.1 VARCHARVARCHAR 类型用于存储**可变长**字符串,是最常见的字符...
[数据库系统] 业界列式存储浅析
列存的主要研究领域还是停留在怎么样打破内存墙,在2001年,Ailamaki等人提出了PAX(Partition Attributes Cross)【1】格式,开始研究怎么样结合列存的优势到行存中。2017年 google spanner 发表论文【2】,描述了自己如... 同一个table 表的内容根据不同但有重叠且按不同attribute进行排序的projections进行冗余存储,以便query能选择最优的projections进行查询;1. 使用不同的coding算法重度压缩列;1. 构建基于列存的优化器和执行器...
 特惠活动
特惠活动
 hbase怎么存blob内容-优选内容
hbase怎么存blob内容-优选内容
 hbase怎么存blob内容-相关内容
hbase怎么存blob内容-相关内容
EMR-3.6.2 版本说明
环境信息 系统环境版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.10.13 Java ByteOpenJDK 1.8.0_352 应用程序版本 Hadoop集群 Flink集群 Kafka集群 HBase集群 StarRocks集群 ClickHouse集群 Op... hive_metastore 3.1.3 Hive元数据存储服务。 hive_server 3.1.3 用于将 Hive 查询作为 Web 请求接受的服务。 hive_client 3.1.3 Hive命令行客户端。 hdfs_namenode 3.3.4 用于跟踪HDFS文件名和数据块的服务。 hdf...
EMR-3.6.1 版本说明
环境信息 系统环境版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.10.13 Java ByteOpenJDK 1.8.0_352 应用程序版本 Hadoop集群 Flink集群 Kafka集群 HBase集群 StarRocks集群 ClickHouse集群 Op... Trino组件中修复access-control.properties文件内容。 【组件】修复扩容节点上Tez依赖包重复上传造成Hive作业失败问题。 组件版本 下面列出了 EMR 和此版本一起安装的组件。 组件 版本 描述 zookeeper_server 3....
20000字详解大厂实时数仓建设 | 社区征文
数仓的数据明细层内容会非常丰富,处理明细数据外一般还会包含轻度汇总层的概念,另外离线数仓中应用层数据在数仓内部,但实时数仓中,app 应用层数据已经落入应用系统的存储介质中,可以把该层与数仓的表分离;- 应用层... 会使用不同的方式进行存储。比如常见的情况下,明细数据或者汇总数据都会存在 Kafka 里面,但是像城市、渠道等维度信息需要借助 Hbase,mysql 或者其他 KV 存储等数据库来进行存储。接下来,根据顺风车实时数仓架构图...
EMR-3.6.0 版本说明
环境信息 系统环境版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.10.13 Java ByteOpenJDK 1.8.0_352 应用程序版本 Hadoop集群 Flink集群 Kafka集群 HBase集群 StarRocks集群 ClickHouse集群 Op... hive_metastore 3.1.3 Hive元数据存储服务。 hive_server 3.1.3 用于将 Hive 查询作为 Web 请求接受的服务。 hive_client 3.1.3 Hive命令行客户端。 hdfs_namenode 3.3.4 用于跟踪HDFS文件名和数据块的服务。 hdf...
表设计之数据类型优化 | 社区征文
**将需要存储的货币单位根据小数的位数乘以相应的倍数即可**。假设要存储财务数据精确到万分之一分,则可以把所有金额乘以一百万,然后将结果存储在 BIGINT 里,这样可以同时避免浮点存储计算不精确和 DECIMAL 精确计算代价高的问题。## 5. 字符串类型MysQL 支持多种字符串类型,包括 VARCHAR 和 CHAR 类型、BLOB 和 TEXT 类型、ENUM(枚举)和 SET 类型。### 5.1 VARCHARVARCHAR 类型用于存储**可变长**字符串,是最常见的字符...
[数据库系统] 业界列式存储浅析
列存的主要研究领域还是停留在怎么样打破内存墙,在2001年,Ailamaki等人提出了PAX(Partition Attributes Cross)【1】格式,开始研究怎么样结合列存的优势到行存中。2017年 google spanner 发表论文【2】,描述了自己如... 同一个table 表的内容根据不同但有重叠且按不同attribute进行排序的projections进行冗余存储,以便query能选择最优的projections进行查询;1. 使用不同的coding算法重度压缩列;1. 构建基于列存的优化器和执行器...
一步搞定项目changelog的生成和实时通知
统一 git commit message 提交方式使项目迭代内容更趋于工程统一化,一目了然。得物前端团队已经产出相应的实时提交约束工具库,约束遵循 Angular 规范,链接指向👉 https://github.com/angular/angular/blob/master/... 两个模块独立存在,命令使用不会互相影响。* 生成 CHANGELOG.md 模块:该模块主要在 conventional-changelog 开源包的基础上,解决多人协同开发导致的 CHANGELOG.md 内容紊乱,并依据 npm version xxx 原理新增自动提...
干货 | 这样做,能快速构建企业级数据湖仓
数据通过离线的方式存到数据湖仓。离线数据可以通过 Spark 进行特征抽取及特征工程,并把提取出来的特征返存到湖仓或者 HBase 等键值存储。基于离线的数据可以进行离线训练,如通过 Spark MLlib 搭建传统的机型学习模型,或者通过 TensorFlow 进行深度模型的训练,把深度训练出来的模型部署到模型服务中。在在线方面,数据通过 Kafka 流入 Flink 进行在线特征抽取,然后把在线特征放在 Redis。同时在线部分的增量数据可用 TensorF...
字节跳动 NoSQL 的探索与实践
列存:以 HBase 为代表; - 图、时序等新兴的数据库也都属于 NoSQL 范畴。如今 NoSQL 在字节跳动有非常广泛的应用:数万 NoSQL 应用实例,10W+ 台物理服务器资源,字节跳动超过 90% 的在线服务都是 NoSQL 系统提供的。### NoSQL 产品矩阵![]()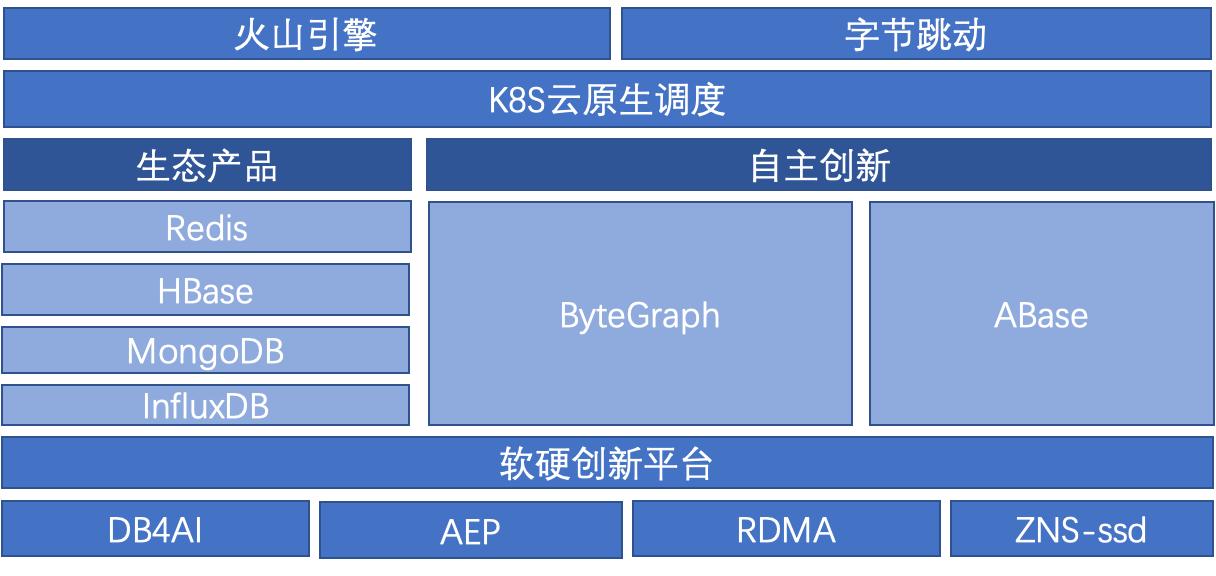上图是字节跳动 NoSQL 的产品矩阵。我们对内对...
