hbase存储txt文件
 社区干货
社区干货
9年演进史:字节跳动 10EB 级大数据存储实战
# 背景## **HDFS** **简介**HDFS 全名 Hadoop Distributed File System,是业界使用最广泛的开源分布式文件系统。原理和架构与 Google 的 GFS 基本一致。它的特点主要有以下几项:- 和本地文件系统一样的目录... HBase,日志服务,Kafka 数据存储 - Yarn,Flink 的计算框架平台数据 - Spark,MapReduce 的计算相关数据存储![]()# **字节跳动特色的** **HDFS** **架构**在深入相关的技术细节之前,我们先看看字节跳动的 H...
干货 | 这样做,能快速构建企业级数据湖仓
LakeHouse 定义了一种叫我们称之为 **Table Format** 的存储标准。Table format 有四个典型的特征:* **支持 ACID 和历史快照** ,保证数据并发访问安全,同时历史快照功能方便流、AI 等场景需求。* **满足多引擎... 即在数据湖的存储之上定义一个元数据,并跟数据一样保存在存储介质上面。这三者相似的需求以及相似的架构,导致了他们在演化过程中变得越来越相似。可以看到,三种数据格式都基本能覆盖绝大部分特性。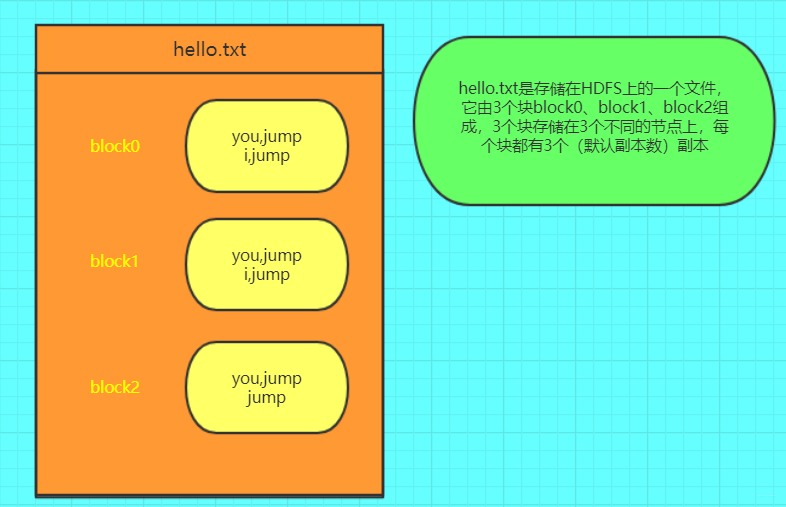## 三、RDD的创建方式### 3.1 通过读取文件生成的由外部存储系统的数据集创建,包括本地的文件系统,还有所有Hadoop支持的数据集,比如HDFS、Cassandra、HBase等```cppscala> val file =...
 特惠活动
特惠活动
 hbase存储txt文件-优选内容
hbase存储txt文件-优选内容
 hbase存储txt文件-相关内容
hbase存储txt文件-相关内容
修改存储空间大小
本文介绍如何修改 HBase 实例的存储空间大小。 注意事项每个实例默认支持的存储空间上限为 20000GiB,步长为 10GiB。您可以提交工单联系技术支持提高上限。 缩容时,目标存储空间不能小于当前已用存储空间的 140%,请根据实际业务情况合理选择。您可以在实例信息页的配置信息区域查看实例当前已用存储空间大小。 费用说明按量计费实例为后付费,扩缩容后,系统将根据新存储容量按小时进行计费。 包年包年实例为预付费,扩缩容后,系统...
基础使用
共享文件系统、HDFS、HBase或任何提供Hadoop InputFormat的数据集。 2.1 创建RDD示例:通过集合来创建RDD val data = Array(1, 2, 3, 4, 5)val distData = sc.parallelize(data)通过外部数据集构建RDD val distFile = sc.textFile("data.txt")RDD构建成功后,可以对其进行一系列操作,例如Map和Reduce等操作。例如,运行以下代码,首先从外部存储系统读一个文本文件构造了一个RDD,然后通过RDD的Map算子计算得到了文本文件中每一行的长...
EMR-2.1.0版本说明
环境信息 系统环境版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.7.3 Java ByteOpenJDK 1.8.0_302 应用程序版本 Hadoop集群 HBase集群 Flume 1.9.0 - OpenLDAP 2.4.58 2.4.58 Ranger 1.2.0 - Z... hive_metastore 2.3.9 Hive元数据存储服务。 hive_server 2.3.9 用于将 Hive 查询作为 Web 请求接受的服务。 hive_client 2.3.9 Hive命令行客户端。 hdfs_namenode 2.10.2 用于跟踪HDFS文件名和数据块的服务。 hd...
开通容量型存储
容量型存储可作为冷数据存储介质,用于存储低频使用的数据,价格比普通存储介质更优惠。本文介绍如何开通容量型存储。 前提条件为已有实例开通容量型存储时,实例的状态必须为运行中。 操作步骤您可以选择以下任意一种方式开通容量型存储。 方式一:在创建实例时开通容量型存储 在创建实例时,选择开通容量型存储空间,详情请参见创建实例。 方式二:为已有实例开通容量型存储 登录 HBase 控制台。 在顶部菜单栏的左上角,选择实例所属...
9年演进史:字节跳动 10EB 级大数据存储实战
# 背景## **HDFS** **简介**HDFS 全名 Hadoop Distributed File System,是业界使用最广泛的开源分布式文件系统。原理和架构与 Google 的 GFS 基本一致。它的特点主要有以下几项:- 和本地文件系统一样的目录... HBase,日志服务,Kafka 数据存储 - Yarn,Flink 的计算框架平台数据 - Spark,MapReduce 的计算相关数据存储![]()# **字节跳动特色的** **HDFS** **架构**在深入相关的技术细节之前,我们先看看字节跳动的 H...
EMR-2.4.0 版本说明
环境信息 系统环境版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.7.3 Java ByteOpenJDK 1.8.0_352 应用程序版本 Hadoop集群 HBase集群 HDFS 2.10.2 2.10.2 YARN 2.10.2 2.10.2 MapReduce2 2.10... hive_metastore 2.3.9 Hive元数据存储服务。 hive_server 2.3.9 用于将 Hive 查询作为 Web 请求接受的服务。 hive_client 2.3.9 Hive命令行客户端。 hdfs_namenode 2.10.2 用于跟踪HDFS文件名和数据块的服务。 hd...
EMR-2.2.0 版本说明
环境信息 系统环境版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.7.3 Java ByteOpenJDK 1.8.0_352 应用程序版本 Hadoop集群 HBase集群 Flume 1.9.0 - OpenLDAP 2.4.58 2.4.58 Ranger 1.2.0 - Z... 由于keystore文件只位于master-1节点,因此需要手动将keystore文件复制到集群各节点相应目录下,该步骤预计会在后续版本进行优化; Dolphin Scheduler暂不支持使用tos、cfs进行资源中心资源存储以及执行数据质量任务...
EMR-2.1.1 版本说明
环境信息 系统环境版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.7.3 Java ByteOpenJDK 1.8.0_352 应用程序版本 Hadoop集群 HBase集群 Flume 1.9.0 - OpenLDAP 2.4.58 2.4.58 Ranger 1.2.0 - Z... hive_metastore 2.3.9 Hive元数据存储服务。 hive_server 2.3.9 用于将 Hive 查询作为 Web 请求接受的服务。 hive_client 2.3.9 Hive命令行客户端。 hdfs_namenode 2.10.2 用于跟踪HDFS文件名和数据块的服务。 hd...
EMR-3.6.2 版本说明
环境信息 系统环境版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.10.13 Java ByteOpenJDK 1.8.0_352 应用程序版本 Hadoop集群 Flink集群 Kafka集群 HBase集群 StarRocks集群 ClickHouse集群 Op... hive_metastore 3.1.3 Hive元数据存储服务。 hive_server 3.1.3 用于将 Hive 查询作为 Web 请求接受的服务。 hive_client 3.1.3 Hive命令行客户端。 hdfs_namenode 3.3.4 用于跟踪HDFS文件名和数据块的服务。 hdf...
