高并发缓存和数据库一致性
 社区干货
社区干货
掘地三尺,搞定 Redis 与 MySQL 数据一致性问题 | 社区征文
缓存的数据值 ≠ 数据库中的值;- 缓存或者数据库存在旧的数据,导致线程读取到旧数据。> 为何会出现数据一致性问题呢?把 Redis 作为缓存的时候,当数据发生改变我们需要双写来保证缓存与数据库的数据一致。数据库跟缓存,毕竟是两套系统,如果要保证强一致性,势必要引入 `2PC` 或 `Paxos` 等分布式一致性协议,或者分布式锁等等,这个在实现上是有难度的,而且一定会对性能有影响。如果真的对数据的一致性要求这么高,那引入缓...
火山引擎ByteHouse:分析型数据库如何设计并发控制?
> 更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群 分析型数据库设计并发控制的主要原因是为了确保数据的完整性和一致性,同时提高数据库的吞吐量和响应速度。并发控制可以防止多个事务同时对同一数据进行修改,导致数据不一致的情况发生。通过合理的并发控制策略,分析型数据库可以在保证数据一致性的前提下,最大限度地提高数据库的并发处理能力,从而提高整体性能。此外,并发控制也可以...
大数据量、高并发业务优化教程|社区征文
博主这里的大数据量、高并发业务处理优化基于博主线上项目实践以及全网资料整理而来,在这里分享给大家# 一. 大数据量上传写入优化> 线上业务后台项目有一个消息推送的功能,通过上传包含用户id的文件,给指定用户... 这里给出海量日志高并发下优化点:1. 上报日志进行异步化处理,- 普通版:采用阻塞队列 `ArrayBlockingQueue` 得生产者消费者模式,对日志数据进行异步批量处理,在此场景下,通过生产者将数据缓存再内存中,然后再消...
分布式数据缓存中的一致性哈希算法|社区征文
本文会介绍一致性哈希算法的原理及其实现,并给出其不同哈希函数实现的性能数据对比,探讨 Redis 集群的数据分片实现等,文末会给出实现的具体 github 地址。### Memcached 与客户端分布式缓存Memcached 是一个高性能的分布式缓存系统,然而服务端没有分布式功能,各个服务器不会相互通信。它的分布式实现依赖于客户端的程序库,这也是 Memcached 的一大特点。比如第三方的 spymemcached 客户端就基于一致性哈希算法实现了其分布式...
 特惠活动
特惠活动
 高并发缓存和数据库一致性-优选内容
高并发缓存和数据库一致性-优选内容
 高并发缓存和数据库一致性-相关内容
高并发缓存和数据库一致性-相关内容
分布式数据缓存中的一致性哈希算法|社区征文
本文会介绍一致性哈希算法的原理及其实现,并给出其不同哈希函数实现的性能数据对比,探讨 Redis 集群的数据分片实现等,文末会给出实现的具体 github 地址。### Memcached 与客户端分布式缓存Memcached 是一个高性能的分布式缓存系统,然而服务端没有分布式功能,各个服务器不会相互通信。它的分布式实现依赖于客户端的程序库,这也是 Memcached 的一大特点。比如第三方的 spymemcached 客户端就基于一致性哈希算法实现了其分布式...
一文了解字节跳动消息队列演进之路
开发和维护工作,还要解决诸多技术难题和痛点,例如如何稳定高效地处理海量数据、如何降低运维成本等。目前经过技术优化和迭代改进,字节跳动的消息队列平台支持弹性扩缩容、高吞吐、低延迟等特性,已经可以稳定承载每... 那么存储在 Partition 3 的所有数据也会因此丢失,造成不可挽回的损失。 **Page Cache**Kafka 的数据缓存只有操作系统的 Page Cache 可用,并没有自己的缓存,这也使得其在处理大规模、高并发的数据...
字节跳动数据库的过去、现状与未来
数据库技术一直是信息技术中极其重要的一环,在步入云原生时代后,云基础设施和数据库进一步整合,弥补了传统数据库的痛点,带来了高可扩展性、全面自动化、快速部署、节约成本、管理便捷等优势。从 2018 到 2021 年... 又解决了传统通过 Binlog 跨多数据中心异步复制带来的 RPO 无法等于 0 的问题;- **高性能:** 数据库团队做了大量优化工作,使 veDB 在高并发集群模式下的吞吐量 QPS 远超传统单机数据库;- **成本低:** 按需独...
业务中台数据一致性方案|社区征文
本文所要探讨的服务之间的数据一致性便是其中最具代表性的问题。本文将结合常见的电商下单场景来说明业务中台数据一致性方案。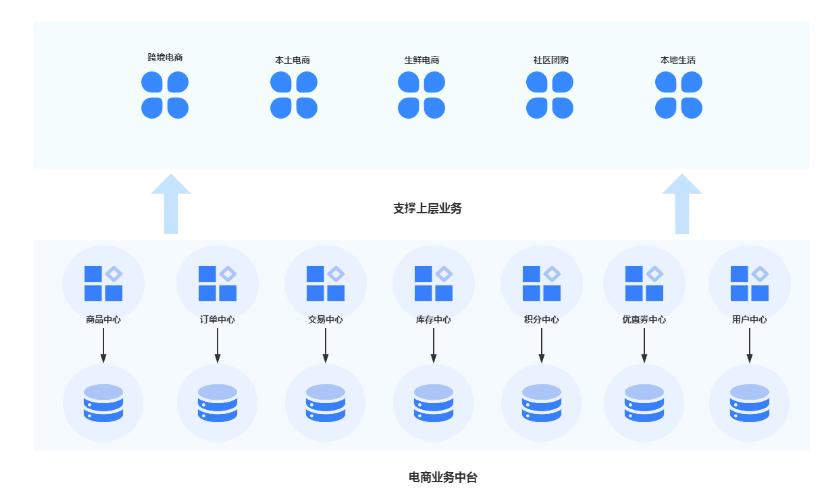# 数据一致性原理预备知识在探讨业务中台数据一致性方案之前,我们先来一起回顾下数据库事务的相关内容,通过对数据库事务的分析,我们可以看出来在微服务架构中想要保...
字节跳动数据库的过去、现状与未来
数据库技术一直是信息技术中极其重要的一环,在步入云原生时代后,云基础设施和数据库进一步整合,弥补了传统数据库的痛点,带来了高可扩展性、全面自动化、快速部署、节约成本、管理便捷等优势。从 2018 到 2021 年... 又解决了传统通过 Binlog 跨多数据中心异步复制带来的 RPO 无法等于 0 的问题;* **高性能**:数据库团队做了大量优化工作,使 veDB 在高并发集群模式下的吞吐量 QPS 远超传统单机数据库;* **成本低**:按需独立扩...
一文读懂火山引擎云数据库产品及选型
纵观整个数据库发展史,关系型数据库系统是历史最悠久并且使用最广泛的一类数据库系统,其理论基础是基于 IBM 研究员 E.F.Codd 博士在 1970 年提出的“关系模型(Relational model)”。关系型数据库也是过去几十年里各行各业使用最多最广泛的数据库类型。随着 2000 年之后移动互联网的大规模爆发,催生出了丰富多彩的面向互联网的应用,这些应用共同的特点是并发量非常高,数据量特别大。基于这些互联网的新场景与新需求,又出现了 No...
业务代码开发建议
本文介绍在使用缓存数据库 Redis 版进行业务代码开发时,需要注意的使用建议。 建议级别 说明 强烈建议 将 Redis 仅作为缓存使用。原因在于 Redis 的持久化和主从复制都是异步进行的,不太适用于对数据可靠性和一致性要求较高的场景。 设置缓存过期时间。 对服务端超时等错误信息进行监控,并设置客户端重试机制来应对限流或主备切换等场景。 设置 Redis 实例的监控告警,监控对象包括内存使用率、CPU 使用率等。更多详情,请参见监控...
干货|揭秘字节跳动对Apache Doris 数据湖联邦分析的升级和优化
数据缺乏一致性、缺乏隔离性、无法保证数据质量等,导致数据湖管理复杂,如果管理不善,数据湖将会退化成数据沼泽。 于是,2020年湖仓一体的概念被提出,主要指在数据湖中建设存储、湖上建仓。 湖仓一体的优势特性包括: **● 支持事务。** 在企业中,数据往往由业务系统提供、并发读取和写入,对事务性要求高。由于一部分业务在读取数据,同时另一部分业务在写入数据,需要保证在并发过程中数据的一致性和正确性。 **● 支持数据模...
观点 | 数仓领域的未来趋势解读
字节跳动数据平台> > > 数据仓库发展历程很久,随着云计算等技术发展以及海量数据应用场景等出现,对数据仓库提出全新要求,高性能、实时性、云原生等成为数据仓库发展关键词,也因此演变出不同的数仓发展路径。> > > > > **在字节跳动十年发展历程中,各类业务数据量膨胀,不断挑战数据能力边界,也让字节跳动在数据链路优化处理、提升分析效率、数据仓库选型、数据引擎架构搭建等层面积累丰富经验。**> > > > ...
