数据库和缓存的一致性
 社区干货
社区干货
掘地三尺,搞定 Redis 与 MySQL 数据一致性问题 | 社区征文
如果真的对数据的一致性要求这么高,那引入缓存是否真的有必要呢?## 2. 缓存的使用策略在使用缓存时,通常有以下几种缓存使用策略用于提升系统性能:- `Cache-Aside Pattern`(旁路缓存,业务系统常用)- `Read-Through Pattern`- `Write-Through Pattern`- `Write-Behind Pattern`### 2.1 Cache-Aside (旁路缓存)所谓「旁路缓存」,就是**读取缓存、读取数据库和更新缓存的操作都在应用系统来完成**,**业务系统最常用的缓...
分布式数据缓存中的一致性哈希算法|社区征文
一致性哈希算法在分布式缓存领域的 MemCache,负载均衡领域的 Nginx 以及各类 RPC 框架中都有广泛的应用,它主要是为了解决传统哈希函数添加哈希表槽位数后要将关键字重新映射的问题。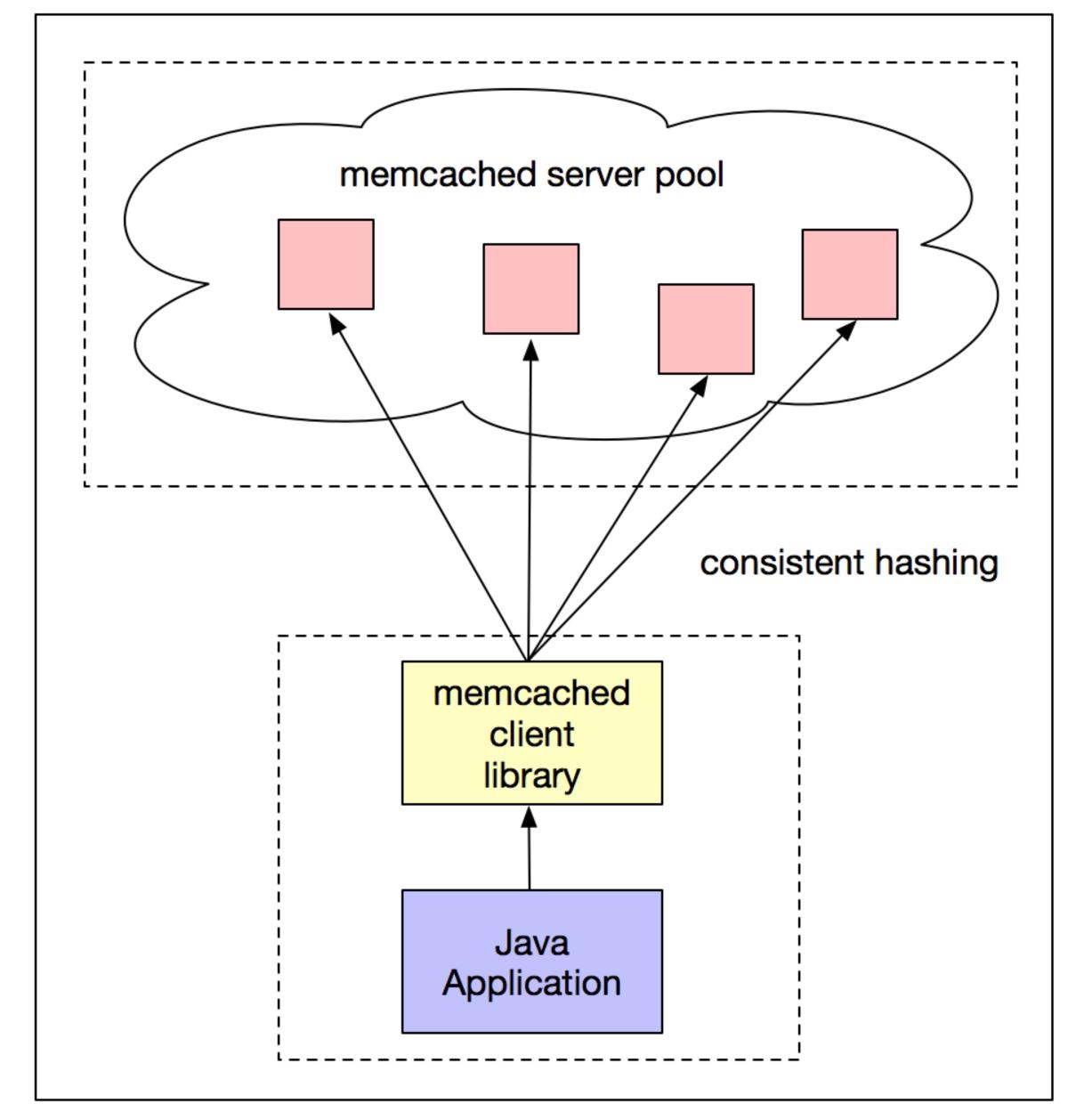本文会介绍一致性哈希算法的原理及其实现,并给出其不同哈希函数实现的性能数据对比,探讨 Redis 集群的数据分片实...
MySQL学习记录(第二天)
为查询缓存优化你的查询大多数的 MySQL 服务器都开启了查询缓存。这是提高性最有效的方法之一,而且这是被 MySQL 的数据库引擎处理的。当有很多相同的查询被执行了多次的时候,这些查询结果会被放到一个缓存中,这样,后续的相同的查询就不用操作表而直接访问缓存结果了。这里最主要的问题是,对于程序员来说,这个事情是很容易被忽略的。因为,我们某些查询语句会让 MySQL 不使用缓存。MySQL 的查询缓存对这个函数不起作用。所以...
字节跳动数据库的过去、现状与未来
分布式缓存、KV、图等,也有云数据库方向的 veDB、HTAP 相关的一些技术。**veDB 主体架构**veDB 自身即一个较大的产品矩阵。它除了提供 MySQL、PG、MongoDB,也在字节跳动内部研发扩展了 Elastic Search 服务,包括自研的、用于处理 TP/AP 相关事务的产品 HTAP。数据库团队在设计上采用了分层式架构,由高性能网络连接上层的数据库和底层的分布式存储引擎平台。整个 veDB 的架构遵循的基本哲学是分离。首先是 **计算和...
 特惠活动
特惠活动
 数据库和缓存的一致性-优选内容
数据库和缓存的一致性-优选内容
 数据库和缓存的一致性-相关内容
数据库和缓存的一致性-相关内容
实例选型指导
使用缓存数据库 Redis 版实例前,您需要结合使用场景、业务负载、产品性能、价格等因素,选择符合您业务且性价比最高的 Redis 实例。 选型流程在具体业务中,您可以参考如下步骤完成 Redis 实例选型: 1. 预估所需数据... 因此读写分离功能不适用于数据一致性要求高的业务。更多详情,请参见读写分离。 .custom-md-2nd-table th:nth-of-type(1) { width: 150px; } .custom-md-3rd-table th:nth-...
字节跳动数据库的过去、现状与未来
分布式缓存、KV、图等,也有云数据库方向的 veDB、HTAP 相关的一些技术。**veDB 主体架构**veDB 自身即一个较大的产品矩阵。它除了提供 MySQL、PG、MongoDB,也在字节跳动内部研发扩展了 Elastic Search 服务,包括自研的、用于处理 TP/AP 相关事务的产品 HTAP。数据库团队在设计上采用了分层式架构,由高性能网络连接上层的数据库和底层的分布式存储引擎平台。整个 veDB 的架构遵循的基本哲学是分离。首先是 **计算和...
实例合理使用带宽建议
作为缓存数据库,Redis 通常需要执行较多的数据存取操作,这些操作会带来较大的网络带宽消耗。缓存数据库 Redis 实例规格不同,默认带宽也不同,当业务流量超过实例的默认带宽时,应用服务的数据访问性能会受到影响。本... 关于两种类型实例的架构和支持功能特性差异详情,请参见产品架构和功能特性差异。 开启读写分离模式后可能会读取到脏数据,因此对数据一致性要求很高的场景下,不建议开启读写分离模式。 扩容实例匹配业务负载若经过...
字节跳动数据库的过去、现状与未来
分布式缓存、KV、图等,也有云数据库方向的 veDB、HTAP 相关的一些技术。### veDB主体架构veDB 自身即一个较大的产品矩阵。它除了提供 MySQL、PG、MongoDB,也在字节跳动内部研发扩展了 Elastic Search 服务,包括自研的、用于处理 TP/AP 相关事务的产品 HTAP。数据库团队在设计上采用了分层式架构,由高性能网络连接上层的数据库和底层的分布式存储引擎平台。整个 veDB 的架构遵循的基本哲学是分离。首先是计算和存储的分离...
迁移至火山引擎版 Redis
关于账号的创建方法和实名认证,请参见如何进行账号注册和实名认证。 已创建缓存数据库 Redis 版数据库和设置默认账号 default 的密码。详细操作,请参见创建实例和设置默认账号密码。 当源库、目标库部署在火山引... 导致目标数据库中查看的 Key 数量比源库的 Key 数量少。 在迁移期间,当源库发生扩缩容例如增加或减少分片、规格变配例如扩大内存时,您需重新配置任务。为保障数据一致性,在重新配置任务前,建议先清空已迁移至目标...
性能问题和解决方案
由于数据库使用不正确、业务规划不合理等情况都会产生热 Key 和大 Key,如果未能及时发现并处理热 Key 和大 Key,可能会导致数据库性能下降,严重影响业务。缓存数据库 Redis 版支持性能分析功能,能够帮助及时发现并分析数据库中的热 Key 和大 Key 详情,为您优化热 Key 和大 Key 提供数据参考。 判断标准大 Key大 Key 通常含有较大数据量或大量元素(如成员、列表数等)。缓存数据库 Redis 版的大 Key 判断标准如下: 对于 String 类型...
功能特性
本文汇总了缓存数据库 Redis 版功能特性相关的常见问题。 缓存数据库 Redis 版支持读写分离吗?仅主备类型的 Redis 实例支持读写分离功能,单节点实例不支持。设置读写分离的方法,请参见设置读写分离。 是否支持将读... 缓存数据库 Redis 版可以作为数据库来使用吗?虽然缓存数据库 Redis 版支持持久化,但 Redis 的持久化和主从复制都是异步进行的,不太适用于对数据可靠性和一致性要求较高的场景。您可以把部分数据(如对实时性要求较...
迁移至火山引擎 ECS 自建 Redis
请参见如何进行账号注册和实名认证。 已创建缓存数据库 Redis 版数据库和设置账号密码。详细操作,请参见创建实例和设置账号密码。 已创建火山引擎 ECS 自建 Redis 实例和数据库。 当源库、目标库部署在火山引擎... 导致目标数据库中查看的 Key 数量比源库的 Key 数量少。 在迁移期间,当源库发生扩缩容例如增加或减少分片、规格变配例如扩大内存时,您需重新配置任务。为保障数据一致性,在重新配置任务前,建议先清空已迁移至目标...
2022技术盘点之平台云原生架构演进之道|社区征文
数据库有MongoDB分片集群/MySQL/Redis/ElasticSearch/RabbitMQ进行各类业务数据计算和存储## 三 流量管控... API组合和协议转换,通过调用不同服务聚合聚合,同时有的API网关也负责验证,鉴权,负载均衡,协议转换,数据缓存等,框架网关如Netflix Zuul、Spring Cloud Gateway,云原生网关:Ingress-Treafik/Nginx/APISIX,Kong,Istio...
