学生选课系统流程图数据库
 社区干货
社区干货
一文读懂火山引擎云数据库产品及选型
团队致力于帮助企业与组织更好的使用火山引擎云存储与云数据库产品,针对实际业务场景设计最优的解决方案,用专业技术助力组织和企业实现业务成功。## 为什么要做数据库选型### 数据库选型的重要性与难点发展数字经济是当下各行各业的重要方向。支撑数字经济的底座是软件,特别是基础软件,可以说基础软件是整个数字经济的坚实底座。在基础软件领域,有三大基础软件,分别是操作系统、数据库系统和中间件。我们每天日常生活中的方...
一文读懂火山引擎云数据库产品及选型
为什么要做数据库选型 **数据库选型的重要性与难点**发展数字经济是当下各行各业的重要方向。支撑数字经济的底座是软件,特别是基础软件,可以说基础软件是整个数字经济的坚实底座。在基础软件领域,有三大基础软件,分别是操作系统、数据库系统和中间件。我们每天日常生活中的方方面面,背后都离不开这些基础软件的支撑,其中数据库系统是业务数据的载体,比如银行卡上的余额,是非常重要的数据,不能有任何差...
火山引擎ByteHouse:分析型数据库如何设计并发控制?
确保数据库能够快速响应用户的查询和更新操作。因此,设计合理的并发控制机制是分析型数据库中非常重要的一个环节,它能够确保数据库系统高效、稳定地运行,为数据分析、查询等应用提供强有力的支持。作为火山引擎推... 描述了2阶段原子提交的一个详细流程。- 阶段1 - 1. a: 在kv里写入事务记录(txn record),唯一标识当前事务; - 1. b: 解析insert sql并执行; - 1. c: 在远端文件系统或者对象存储写入数据之前...
一文读懂火山引擎云数据库产品及选型
# 1、为什么要做数据库选型## 1.1、数据库选型的重要性与难点发展数字经济是当下各行各业的重要方向。支撑数字经济的底座是软件,特别是基础软件,可以说基础软件是整个数字经济的坚实底座。在基础软件领域,有三大基础软件,分别是操作系统、数据库系统和中间件。我们每天日常生活中的方方面面,背后都离不开这些基础软件的支撑,其中数据库系统是业务数据的载体,比如银行卡上的余额,是非常重要的数据,不能有任何差错,数据库在所有...
 特惠活动
特惠活动
 学生选课系统流程图数据库-优选内容
学生选课系统流程图数据库-优选内容
 学生选课系统流程图数据库-相关内容
学生选课系统流程图数据库-相关内容
掘地三尺,搞定 Redis 与 MySQL 数据一致性问题 | 社区征文
Redis 拥有高性能的数据读写功能,被我们广泛用在缓存场景,一是能提高业务系统的性能,二是为数据库抵挡了高并发的流量请求,[点我 -> 解密 Redis 为什么这么快的秘密](https://mp.weixin.qq.com/s/z4VjDaDDbspFz1rIB... 因为需要额外的缓存填充和数据库查询耗时。#### 2.1.2 更新数据使用 `cache-aside` 模式写数据时,如下流程。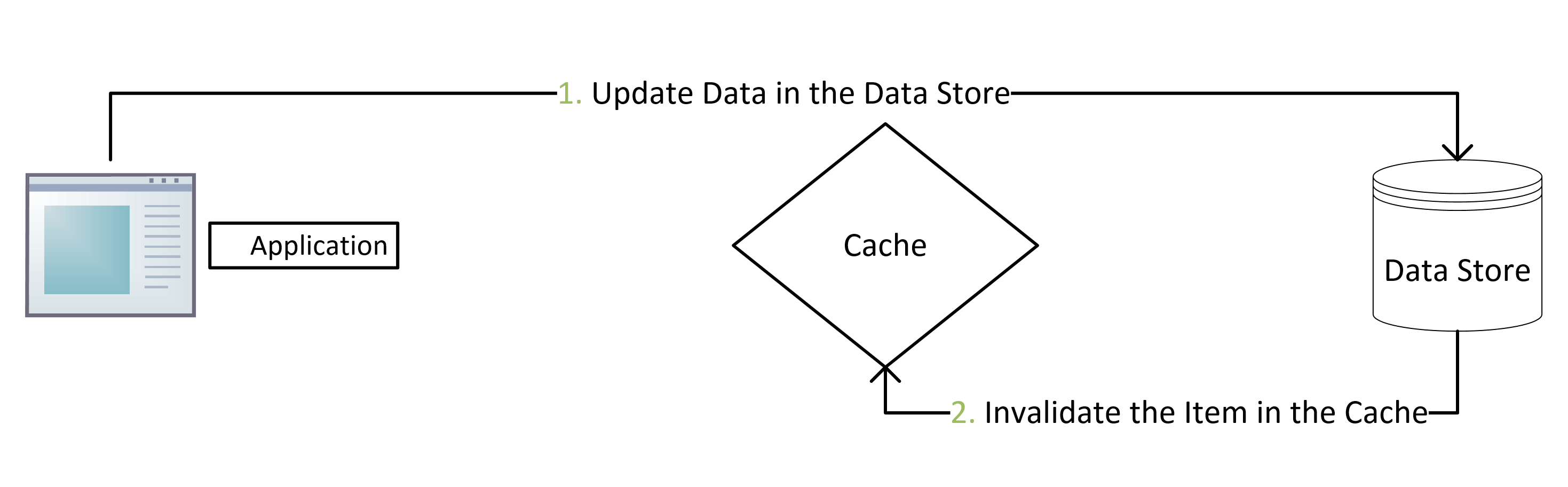...
NL2SQL:智能对话在打通人与数据查询壁垒上的探索 | 社区征文
业务人员想要查询相应的结果需要找到数据工程人员完成相关流程。流程比较繁琐,而通过nl2sql技术,则可直接将问题转换成相对应的SQL语句用于相关表的查询并返回结果,因此nl2sql可被用于问答系统,通过配合相关规则及其... 它可以充当数据库的智能接口,让不熟悉数据库的用户能够快速地找到自己想要的数据,改善用户与数据库的交互方式。#### 2.2 NL2SQL的目标与定位从技术的角度来看,NL2SQL的本质是将用户的自然语言语句转化为计算机可...
A/B测试成为企业“新窗口”:增长盈利告别经验主义,数据科学才是未来
对于产品流程设计也能提供合理选择。如果流程改版涉及到挑战“常识”,决策者就更需要来自数据和实验的信心。 改版主动延长用户支付路径,这不是悟空租车的一步“昏招”,而是让收入增长 7%的“神操作”。A/B 测... 工具和数据信仰已经不再是选修课,而是企业的必修课。 从远古时代先民烧龟甲占卜开始,人类就试图通过工具辅助决策。从迷信到决策艺术再到决策科学,本质上是工具的进化和技术进化。过往静态机械的用户画像、资...
干货|什么是瞬态集群?解读火山引擎EMR Stateless 的创新理念以及应用
**左边这个流程图,是一个传统的 Stateful 模式。**在这个模式下,大家要提交一个任务的数据流程通常是这样的,首先必须要有一个长时间运行的集群,有了集群以后,再将任务提交上去,接下来无论是通过 IO 的直接返回... NoSQL 数据库以及机器学习等相关内容。**这个是带有计算特性的集群中,所有带有状态部分的内容都被剥离了。Stateless把 History Serverhe 和 UI 相关的内容都剥离成为独立服务,包含 Spark History Server, Presto...
干货|什么是瞬态集群?解读火山引擎EMR Stateless 的创新理念以及应用
**左边这个流程图,是一个传统的 Stateful 模式。**在这个模式下,大家要提交一个任务的数据流程通常是这样的,首先必须要有一个长时间运行的集群,有了集群以后,再将任务提交上去,接下来无论是通过 IO 的直接返回,还... NoSQL 数据库以及机器学习等相关内容。** 这个是带有计算特性的集群中,所有带有状态部分的内容都被剥离了。Stateless把 History Serverhe 和 UI 相关的内容都剥离成为独立服务,包含 Spark History Server, Presto...
揭秘|字节跳动基于Hudi的数据湖集成实践
这是最终的CDC数据导入流程图首先,不同的数据库会将Binlog发送到消息队列中,Flink任务会将所有数据转换成HoodieRecord格式,然后通过哈希索引找到对应的文件ID,通过一层对文件ID的shuffle后,数据到达了写入层,写入算子以追加写的形式将数据频繁的写入到HDFS中,Checkpoint触发后,Flink会将所有的元数据收集到一起,并写入到hudi的元数据系统中,这里就标志了一个Commit提交完成,一个新的Commit会随之开始。用户可以通过Flink S...
字节跳动实时数据湖构建的探索和实践
字节跳动数据集成系统目前支持了几十条不同的数据传输管道,涵盖了线上数据库,例如Mysql Oracle和MangoDB;消息队列,例如Kafka RocketMQ;大数据生态系统的各种组件,例如HDFS、HIVE和ClickHouse。在字节跳动内部,数... 整条链路流程太长,涉及到Spark和Flink两个计算引擎,以及3个不同的任务类型,用户使用成本和学习成本都比较高,并且带来了不小的运维成本。为了解决这些问题,我们希望对增量模式做一次彻底的架构升级,**将增量模式合...
六年安卓开发的技术回顾和展望 | 社区征文
系统设计,更没有考虑性能是否有问题**。真正的去开发一个商业项目,让我发现自己不足的太多了。因此在完成工作的同时,我观察并记录了项目迭代的各个流程,同时对自己的技术点做查漏补缺,输出了一些 Java 源码分析、Android 进阶、设计模式文章,也是从那个时候开始,**养成了定期复盘的习惯**,每次...
Flink 流批一体在字节跳动的探索与实践
**在存储方面**,流批一体即存储系统能够同时满足流式数据和批式数据的存储,并能够有效地进行协同以及元数据信息的更新。架构体系使用流批一体后,数据流向如下图左边流程图所示。 无论是流式数据还是批式数据... 再 Upsert 到整个数据库当中,进行统一的管理。 基于 Iceberg 实现特征的统一存储,具备以下能力:- 存储流批一体,支持元数据的更新和管理 - 提供 ACID 保证和快照功能 - 并发读写 - 计算存储引擎解耦 - ...
