创建一个数组/向量,其中每个项具有不同的构造函数参数。
 社区干货
社区干货
【AI人工智能】手把手教你,如何训练专属于自己的私人影院推荐助手
在__init__构造函数中进行组网Layer的声明,#在forward中使用声明的Layer变量进行前向计算。子类组网方式也可以实现sublayer的复用,针对相同的layer可以在构造函数中一次性定义,在forward中多次调用。 def __i... #使用循环的方式创建全连接层,可以在超参数中通过一个数组确定使用几个全连接层以及每个全连接层的神经元数量。 #本例中使用了4个全连接层,并在每个全连接层后增加了relu激活层。 user_si...
万字长文带你漫游数据结构世界|社区征文
数据元素之前的关系在计算机中有两种不同的表示方法:**顺序映像和非顺序映像**,并且由此得到两种不同的存储结构:**顺序存储结构**和**链式存储结构**,比如顺序存储结构,我们要表示复数`z1 =3.0 - 2.3i `,可以直接借... 也可以用数组,但是`JDK`底层的栈,是用数组实现的,封装之后,通过`API`操作的永远都只能是最后一个元素,栈经常用来实现递归的功能。如果想要了解`Java`里面的栈或者其他集合实现分析,可以看看这系列文章:http://aphy...
基于 Ray 的大规模离线推理
是指在具有数十亿或数千亿参数的大规模模型上进行分布式推理的过程。相较于常规模型推理,在模型切分、数据处理和数据流、提升 GPU 利用率方面面临了很大挑战。本次分享将介绍如何利用 Ray 及云原生优势助力大模型离... 就是将模型的不同层切开,切分成不同的分组,然后放到不同的 GPU 上。比如左上的图中有两个GPU,第一个 GPU 存 L0-L3,第二个 GPU 存 L4-L7。因为每个层的大小不一样,所以不一定是平均分配,有的层可能会非常大,独占一个...
基于 Ray 的大规模离线推理
是指在具有数十亿或数千亿参数的大规模模型上进行分布式推理的过程。相较于常规模型推理,在模型切分、数据处理和数据流、提升 GPU 利用率方面面临了很大挑战。本次分享将介绍如何利用 Ray 及云原生优势助力大模型离... 就是将模型的不同层切开,切分成不同的分组,然后放到不同的 GPU 上。比如左上的图中有两个GPU,第一个 GPU 存 L0-L3,第二个 GPU 存 L4-L7。因为每个层的大小不一样,所以不一定是平均分配,有的层可能会非常大,独占一个...
 特惠活动
特惠活动
 创建一个数组/向量,其中每个项具有不同的构造函数参数。-优选内容
创建一个数组/向量,其中每个项具有不同的构造函数参数。-优选内容
 创建一个数组/向量,其中每个项具有不同的构造函数参数。-相关内容
创建一个数组/向量,其中每个项具有不同的构造函数参数。-相关内容
数组函数
emptyArrayDateTimeemptyArrayString不接受任何参数并返回适当类型的空数组。 emptyArrayToSingle接受一个空数组并返回一个仅包含一个默认值元素的数组。 range(N)返回从0到N-1的数字数组。 以防万一,如果在数据块中创建总长度超过100,000,000个元素的数组,则抛出异常。 array(x1, …), operator [x1, …]使用函数的参数作为数组元素创建一个数组。 参数必须是常量,并且具有最小公共类型的类型。必须至少传递一个参数,否则将不清...
万字长文,Spark 架构原理和 RDD 算子详解一网打进! | 社区征文
每个分片都会被一个计算任务处理,并决定并行计算的粒度。用户可以在创建RDD时指定RDD的分片个数,如果没有指定,那么就会采用默认值。默认值就是程序所分配到的CPU Core的数目。(2)一个计算每个分区的函数。Spark中... 返回RDD的第一个元素(类似于take(1))|take(n) | 返回一个由数据集的前n个元素组成的数组 ||takeSample(withReplacement,num, [seed]) | 返回一个数组,该数组由从数据集中随机采样的num个元素组成,可以选择是否...
徒手体验卷积运算的全过程|社区征文
在实际的卷积的运算过程中会涉及到维度和向量这两个概念。在python中我们从list或者数组中可以了解到这两个相关的知识点,特别是我们常用的numpy(**支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库**)### 数组的形状比如我们常说的excel数据中有几行几列,这就是数组的形状,也就是数组的排列方式,shape本身的意思就是形状的意思. numpy中提供了shape()方法来获取数组的形状, 比如下面的代码:创建数组...
观点 | 数据分析引擎百花齐放,为什么要大力投入ClickHouse?
也因此演变出不同的数仓发展路径。> > > > > **在字节跳动十年发展历程中,各类业务数据量膨胀,不断挑战数据能力边界,也让字节跳动在数据链路优化处理、提升分析效率、数据仓库选型、数据引擎架构搭建等层面积... ClickHouse是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS)。于2016年开源,以性能强悍著称。其具备列式存储、向量化执行引擎、高压缩比、多核并行计算等特性。**1. 性能强**号称最快的OLAP引擎,在...
VikingDB:大规模云原生向量数据库的前沿实践与应用
索引参数以及硬件等维度表示了精度和延迟之间的取舍。最左侧第一张图相对比较了 FLAT、IVF、HNSW 这三种索引算法的计算精度和延迟。向量检索的计算和访存 IO 都非常重,为了提高查询效率,ANN 索引都会对数据做剪枝,不同的索引算法即代表了不同的剪枝策略和不同的剪枝程度。* **FLAT**:暴力索引,不做剪枝,遍历所有数据进行对比。不考虑量化损失的话,精度为 100%,但检索耗时会随着数据量线性增长,因此在数据规模比较大的场景,...
基于 SAP BTP 平台的 AI 项目经验分享 | 社区征文
能区分 29 种不同的产品类别,这些类别具体可以在官方文档上查询到,比如电脑显示器,数码相机,外部存储设备,键盘,液晶电视,手机充电器,笔记本和其他外设等等等。可以打开图像识别 API 的技术规范页面,包含 API Mod... 蓝色区域是笔者手动创建的代码,用于调用 API 并打印结果。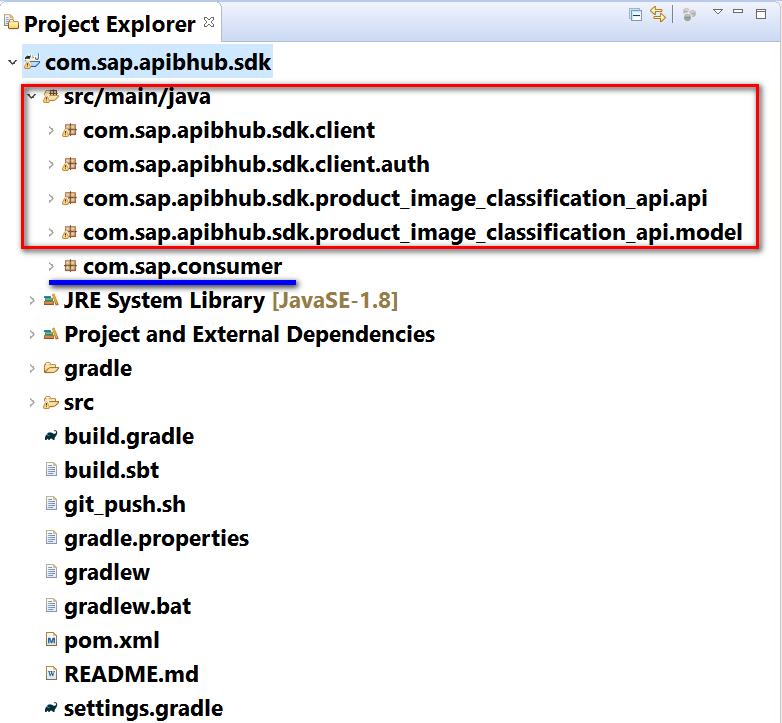编辑根目录下的...
NL2SQL:智能对话在打通人与数据查询壁垒上的探索 | 社区征文
Spider:Spider数据集是耶鲁大学于2018年新提出的一个较大规模的nl2sql数据集。该数据集包含了10,181条自然语言问句,分布在200个独立数据库中的5,693条SQL,内容覆盖了138个不同的领域。虽然在数据数量上不如WikiSQL... #聚合函数符号conn_sql_dict = {0:"", 1:"and", 2:"or"} #条件逻辑关系基于符号字典的描述格式为{ "table_id": "a1b2c3d4", # 相应表格的id "question": "", # 自然语言问句 "sql":{ ...
内容函数
本文档介绍日志服务提供的内置函数语法、使用方式及示例。 控制函数函数 语法 示例 until until 函数用于生成从 0 到 n 的 Integer 类型数组,步长默认为 1,类似 python 中的 range 函数。例如 until(3) 返回数... pluck pluck 函数用于将多个字典中相同的 key 构造成一个数组。语法格式如下: Python pluck(key,map1,map2) 函数示例 Python {%with mp1=dict("a",1,"b",2)%}{%with mp2=dict("a",2,"b",2)%} {%- for v in p...
集简云7月新增/更新:新增1大产品,13大功能,集成8款应用,更新19款应用,新增100多个动作
MINIMAX等数种不同语言模型,Stable Diffusion,Midjourney, 百度文心绘图等300余款AI图像生成模型。**嵌入集成:**提供页面嵌入,API调用,集简云(流程对接)等方式,将语聚AI的能力服务于您的内部与外部用户。... 并输入函数公式,定义其与其他单元格的运算和逻辑关系,可以使该字段的值根据公式字段计算展示,无需再手动计算填写。例如:您可以在薪酬管理中,通过公式字段自动计算员工应发工资,总工资=基础工资+奖金-扣款,避免...
