双哈希表 - 包含方法的标准实现
 社区干货
社区干货
万字长文带你漫游数据结构世界|社区征文
管理以及存储数据的方式。虽然理论上所有的数据都可以混杂,或者糅合,或者饥不择食,随便存储,但是计算机是追求高效的,如果我们能了解数据结构,找到较为适合当前问题场景的数据结构,将数据之间的关系表现在存储上,计... 但是我们还必须知道在计算机中如何表示它。**数据结构在计算机中的表示(又称为映像),称之为数据的物理结构,又称存储结构**。数据元素之前的关系在计算机中有两种不同的表示方法:**顺序映像和非顺序映像**,并且...
基于ClickHouse的复杂查询实现与优化|社区征文
若采用哈希表的方式进行去重,第二阶段需在Coordinator单机上去合并各个Worker的哈希表。这个计算量会很重且无法并行。**第二类,由于目前ClickHouse模式并不支持Shuffle,因此对于Join而言,右表必须为全量数据。**... 我们希望能够充分地去利用机器的资源,来应对这种越来越复杂的业务场景和SQL。所以我们的目标是基于ClickHouse能够高效支持复杂查询。 ## 技术方案对于ClickHouse复杂查询的实现,我们采用了分Stage的执行方式...
基于火山引擎 EMR 构建企业级数据湖仓
LakeHouse 定义了一种叫我们称之为 Table Format 的存储标准。Table format 有四个典型的特征:- 支持 ACID 和历史快照,保证数据并发访问安全,同时历史快照功能方便流、AI 等场景需求。 - 满足多引擎访问:能够... Table 格式:本质上是基于存储的、 Table 的数据+元数据定义。具体来说,这种数据格式有三个具体的实现:Delta Lake、Iceberg 和 Hudi。三种格式提出的出发点略有不同,但是它们的场景需求里都不约而同地包含了...
eBPF 完美搭档:连接云原生网络的 Cilium
包含 三个方面,如上图:- **网络** 1. 高度可扩展的 kubernetes CNI 插件,支持大规模,高动态的 k8s 集群环境。支持多种租网模式: - `Overlay` 模式,支持 Vxlan 及 Geneve - `Unerlay` 模式,通过 Direct Routing (直接路由)的方式,通过 Linux 宿主机的路由表进行转发 1. kube-proxy 替代品,实现了 四层负载均衡功能。LB 基于 eBPF 实现,使用高效的、可无限扩容的哈希表来存储信息。对于南北向...
 特惠活动
特惠活动
 双哈希表 - 包含方法的标准实现-优选内容
双哈希表 - 包含方法的标准实现-优选内容
 双哈希表 - 包含方法的标准实现-相关内容
双哈希表 - 包含方法的标准实现-相关内容
超复杂调用网下的服务治理新思路
毕竟不是每一套系统都达到了超复杂的标准,但是提前关注这些问题并做好预案也非常重要。作为企业的软件架构师或是技术负责人,我们应当始终用发展的眼光看问题,软件行业的发展变化非常巨大,如果企业当下的架构无法适... 不同业务会通过不同活动实现业务增长,对核心服务来说,追溯每个业务的增长也是一个非常艰巨的任务。二 **是会大幅提高服务治理难度** 。这里的服务治理包含限流、ACL 白名单、超时配置等,因为调用关系变得复杂,...
Uniq
实现细节 功能: 计算聚合中所有参数的哈希值,然后在计算中使用它。 使用自适应采样算法。 对于计算状态,该函数使用最多65536个元素哈希值的样本。 这个算法是非常精确的,并且对于CPU来说非常高效。如果查询包含一... 实现细节 功能: 为聚合中的所有参数计算哈希(String类型用64位哈希,其他32位),然后在计算中使用它。 使用三种算法的组合:数组、哈希表和包含错误修正表的HyperLogLog。 少量的不同的值,使用数组。 值再多一些,使...
一文读懂火山引擎云数据库产品及选型
> **火山引擎存储&数据库产品解决方案团队**,由资深的存储&数据库解决方案架构师组成。团队致力于帮助企业与组织更好的使用火山引擎云存储与云数据库产品,针对实际业务场景设计最优的解决方案,用专业技术助力组织和企业实现业务成功。## 为什么要做数据库选型### 数据库选型的重要性与难点发展数字经济是当下各行各业的重要方向。支撑数字经济的底座是软件,特别是基础软件,可以说基础软件是整个数字经济的坚实底座。在基础软...
基于 Flink 构建实时数据湖的实践
通过流或批的方式写入到 Iceberg 中。Iceberg 本身也提供了几种 Action 进行数据维护,所以针对每张表都会有数据过期、快照过期、孤儿文件清理、小文件的合并等定时调度任务,这些 Action 在实践过程中对性能的提升有... 所以我们需要实现一个反序列化方法,输出一条记录,包含 Row 和它对应的 Schema 信息,也就是图中紫色的部分,由此就解决了第一个问题。针对第二个问题,支持多种 Schema 混写,需要为不同的 Schema 创建不同的 Stream...
数据服务基础能力之元数据管理 | 社区征文
快速实现业务模型构建,整体示意图如下: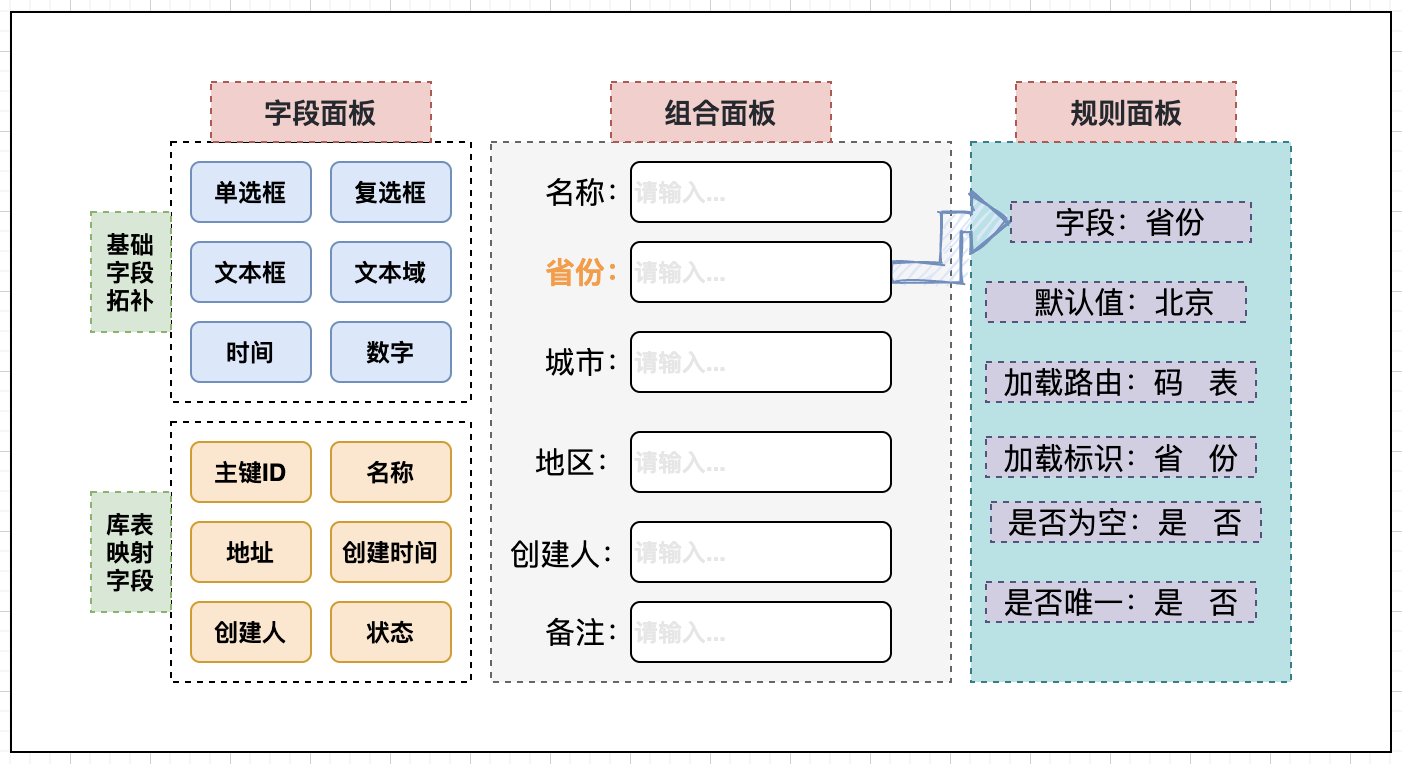像常用的画图工具,左边提供基础图形库,中间是画布,右边是组件的控制细节,对比到这里的逻辑如下:- 字段面板:提供业务数据结构的字段映射,和常规字段类型配置,用来支撑组合面板的表单配置。 - 数据结构:对现有业务结构做映射,可能是文件、数据表、JSON等,生成相对标准的字段选项; - 拓补字...
一文带你读懂:云原生时代业务监控|社区征文
云原生:云原生是一种专门针对云上应用而设计的方法,用于构建和部署应用,以充分发挥云计算的优势,比如我们耳熟能详的“腾讯云”、“阿里云”等。 云原生技术包含了一组应用的模式,用于帮助企业快速,持续,可靠,规模化地交付业务软件。云原生由微服务架构,DevOps 和以容器为代表的敏捷基础架构组成。援引宋净超同学的一张图片来描述云原生所需要的能力与特征: