数据库对数据入库流程图
 社区干货
社区干货
PostgreSQL 开发运维最佳实践
# 前言这篇文章旨在提供 RDS for PostgreSQL 的一些开发和运维建议,以助您提升数据库使用的标准化和稳定性。# 性能与稳定性* 慎用子事务,避免事务中使用过多的子事务。* 游标使用后及时关闭。* 对于在线业务... * 大批量的数据入库,建议使用 copy 语法,或者 INSERT INTO table VALUES (),(),...(); 的方式,提高写入速度。* 建议业务上监控 dead replication slot 并及时清理,避免 WAL 无法清理,最终导致磁盘空间耗尽导致实例...
【模板推荐】 MySql自动化流程让你快速提高工作效率!
企业人员通常没有将巨量引擎的数据做好备份,丢失大量可用信息,此模板可以实现当巨量引擎有新线索创建时,MySql新增数据到指定数据表,节省企业人员统计数据的时间,并将数据做好备份以便查看。 **适用人群:... 此流程是访问某供应链数据库获取采购入库单表数据自动传到伙伴云并自动生成虚拟会计凭证单据(某软件没有api接口或者不做单独对接集简云,可直接通过绑定数据库表实现单据传输) **适用人群:**采购、销售...
VikingDB:大规模云原生向量数据库的前沿实践与应用
火山引擎向量数据库高级工程师 VikingDB 简介  特惠活动
特惠活动
 数据库对数据入库流程图-优选内容
数据库对数据入库流程图-优选内容
 数据库对数据入库流程图-相关内容
数据库对数据入库流程图-相关内容
掘地三尺,搞定 Redis 与 MySQL 数据一致性问题 | 社区征文
Redis 拥有高性能的数据读写功能,被我们广泛用在缓存场景,一是能提高业务系统的性能,二是为数据库抵挡了高并发的流量请求,[点我 -> 解密 Redis 为什么这么快的秘密](https://mp.weixin.qq.com/s/z4VjDaDDbspFz1rIB... 由缓存抽象层来完成缓存数据和数据库数据的更新**,时序流程图如下: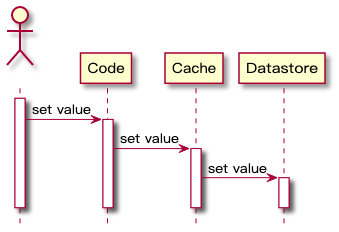`Write-Through` 的主要好处是应用系统的不需要...
一文读懂火山引擎云数据库产品及选型
# 1、为什么要做数据库选型## 1.1、数据库选型的重要性与难点发展数字经济是当下各行各业的重要方向。支撑数字经济的底座是软件,特别是基础软件,可以说基础软件是整个数字经济的坚实底座。在基础软件领域,有三... 我们把选型方法论和火山引擎云数据库产品能力结合在一起,就可以得到了如下的一张选型流程图,按照流程可以确定应用需要的云数据库类型,供大家参考。ByteHouse选择的分布式key-value存储系统,ByteKV和Foundation已经提供了一致性的支持,直接复用即可。- Isolation(隔离性)ByteHouse对用户提供Read Committed(...
产品更新公告
支持对知识库进行检索,并组装 Prompt,使用多种 LLM 生成问题的答案。 2024.04.12 更新类型 功能描述 产品截图说明 新功能 向量数据库新增向量化模型(多功能版)和 pipeline,支持 8k tokens 窗口长度和多语言... 数据写入、索引管理、检索查询、向量生成等功能,详见 Java SDK。 2023.11.30 API更新类型 功能描述 新功能 纯文本预处理能力 pipeline 支持通过 URL 下载文件、提取文本、文本切片、向量化后入库。 API 支持...
集简云 x 水瑾悦,助力私域运营线上订单转化到ERP实现出入库自动化管理
[picture.image](https://p6-volc-community-sign.byteimg.com/tos-cn-i-tlddhu82om/788539322831403192f99d5ab799e32c~tplv-tlddhu82om-image.image?=&rk3s=8031ce6d&x-expires=1716049207&x-signature=y7v3DiXYgAx%2FwPG0nAxsLBzzH%2F0%3D) **水瑾悦介绍** 安徽水瑾悦健康管理有限公司,专注于一流的互联网全链路运营公司,通过基于大数据的人群分析、科学的转化逻辑和对互联网营销领域发...
揭秘|字节跳动基于Hudi的数据湖集成实践
本文是字节跳动数据平台开发套件团队在Flink Forward Asia 2021: Flink Forward 峰会上的演讲,着重分享了字节跳动数据湖技术上的选型思考和探索实践。本文重点分享字节的探索实践,对话框回复数字9可以阅读关于技术... 这是最终的CDC数据导入流程图首先,不同的数据库会将Binlog发送到消息队列中,Flink任务会将所有数据转换成HoodieRecord格式,然后通过哈希索引找到对应的文件ID,通过一层对文件ID的shuffle后,数据到达了写入层,写...
【客户案例】集简云 x 亚细亚卫浴,助力电商行业打通ERP与物流系统之间的数据屏障
目前金蝶云系统暂时还无法实现存储物流相关数据的功能。随着亚细亚卫浴公司的业务螺旋式倍增,其负责人意识到如果可以将物流系统数据也加入到金蝶云系统中,这样,就形成了真正意义上的业务闭环,距离实现自动化业务流... (金蝶云系统→快递管家流程图) 