查询路径变量时遇到的“内部服务器错误jdbc”
 社区干货
社区干货
替换 Spring Cloud,使用基于 Cloud Native 的服务治理
Spring Cloud 的 Config Server 具有较多的能力:- Git 作为配置仓库;- JDBC 和 Redis 提供了统一的配置抽象层。但不太好用。一些个性化的需求比如配置中心的权限管理和热加载,Spring Cloud Config Server 本身不支持,需要做二次开发。对于 Kubernetes,可以通过 ConfigMap 或者 Secret 按照更加原生的方式以环境变量、文件或启动参数的方式注入到应用中去,就像敲 Linux 命令一样方便。我们会发现 Spring Cloud Confi...
2022技术盘点之平台云原生架构演进之道|社区征文
服务通过Kubernetes API-Server获取后端一组Service Pod真实IP,业务POD通过Calico网络进行POD与POD直接流量通讯。## 四 安全管控### 4.1 SmartOps安全全景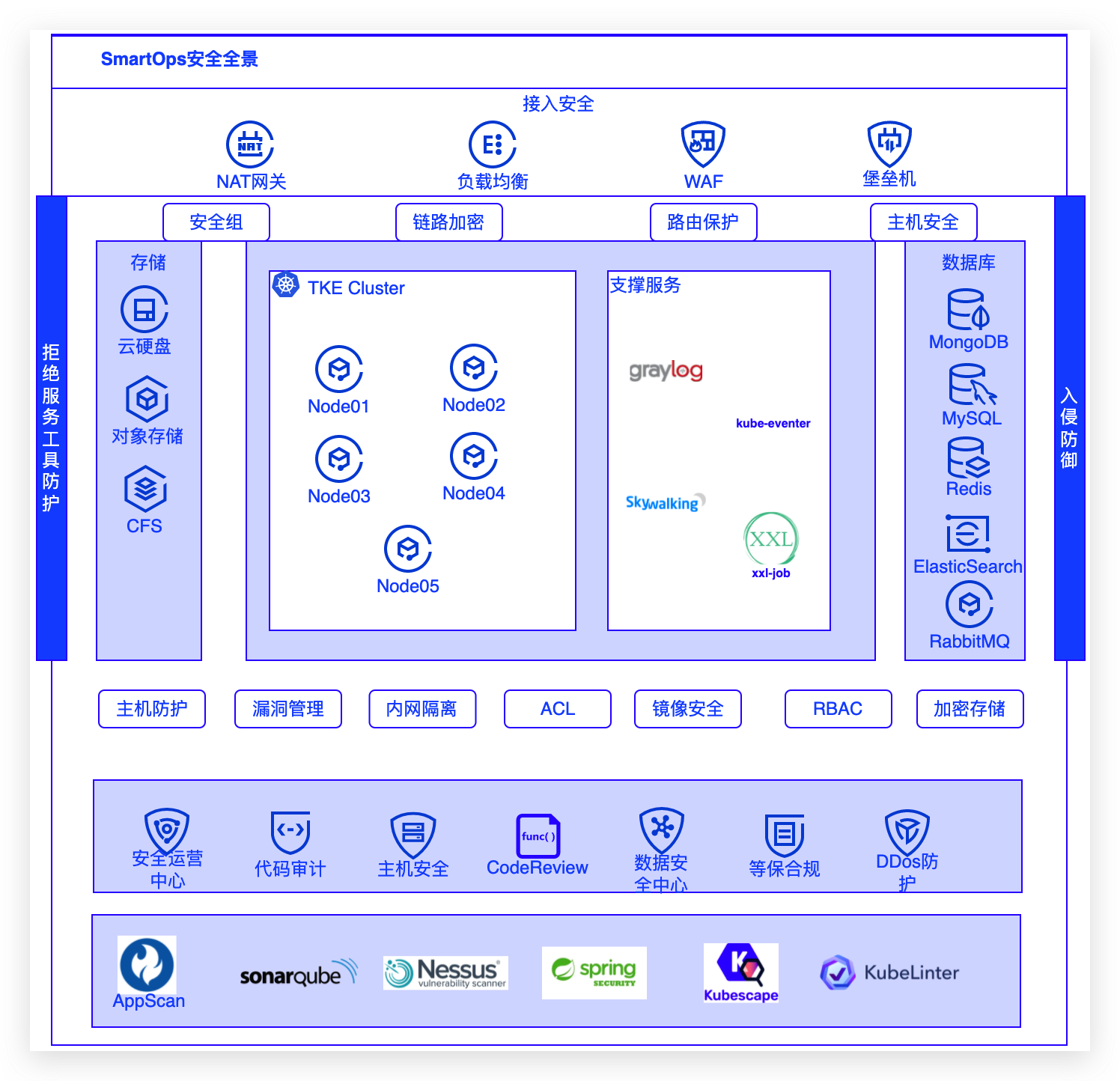- 全场景的安全架构规划:从网络边界、内部网络、各类基础设施、数据、业务应用到后期监控响应,运维管控,在各层面均进行安全管控设计,实现全方位立体式防护;- 云安...
基于 Flink 构建实时数据湖的实践
同时也用 Flink Datastream API 开发了一些高阶功能,出入湖的作业使用 Flink Application Mode 运行在 K8s 上。然后通过 Flink SQL Gateway 和 Session Mode 的 Flink Cluster 进行 OLAP 查询,提供了 JDBC 和 REST... 所以会报错:Index out of range;Row 3 写入时,由于数据类型不匹配,会报错:Class cast excetpion;Row 4 写入时虽然类型和长度都匹配,但 Schema 含义不同,最终会在结果文件中写入一条脏数据。 特惠活动
特惠活动
 查询路径变量时遇到的“内部服务器错误jdbc”-优选内容
查询路径变量时遇到的“内部服务器错误jdbc”-优选内容
 查询路径变量时遇到的“内部服务器错误jdbc”-相关内容
查询路径变量时遇到的“内部服务器错误jdbc”-相关内容
基于 Flink 构建实时数据湖的实践
同时也用 Flink Datastream API 开发了一些高阶功能,出入湖的作业使用 Flink Application Mode 运行在 K8s 上。然后通过 Flink SQL Gateway 和 Session Mode 的 Flink Cluster 进行 OLAP 查询,提供了 JDBC 和 RES... 所以会报错:Index out of range;Row 3 写入时,由于数据类型不匹配,会报错:Class cast excetpion;Row 4 写入时虽然类型和长度都匹配,但 Schema 含义不同,最终会在结果文件中写入一条脏数据。
事件相关等openAPI 修复私有化安全编译后对静态方法wrapper报错的问题 修复报告页计算除数为0的问题 修复os_version在目标受众不展示的问题 2022年05月20日 V1.9.38版本 功能上线公告 报价体系升级改造 bug修复&优化:目标受众有关用户属性跳转链接错误的修复 实验创编服务端实验进组不出组文案调整 (改为进组出组) 调整上线公告的icon大小 修复指标事件空白hover + 创建漏斗提示虚拟事件被删除的问题 修复公共属性重复的问题 ...
观点|SparkSQL在企业级数仓建设的优势
Hive有JDBC客户端,支持标准JDBC接口访问的HiveServer2服务器,管理元数据服务的Hive Metastore,以及任务以MapReduce分布式任务运行在YARN上。标准的JDBC接口,标准的SQL服务器,分布式任务执行,以及元数据中心,... 再次重试所消耗的时间几乎等于全新重新提交一个任务,在分布式任务的背景下,任务运行的时间越长,出现错误的概率越高,对于此类组件的使用业界最佳实践的建议也是不超过30分钟左右的查询使用这类引擎是比较合适的。...
产品动态
当这些资源包的余量总额降低到任何一个阈值时,内容分发网络会通过站内信,邮件和短信通知您。 全量发布 资源包余量预警 2024 年 1 月产品特性 功能描述 上线范围 相关文档 新增 "自定义拦截" 对请求路径和查询参数设... 服务提供模板,用来创建定时刷新和预热任务。 全量发布 2023 年 6 月产品特性 功能描述 上线范围 相关文档 升级"智能压缩"配置 支持创建多条规则。CDN 仅对匹配规则的请求进行文件压缩。规则支持对目录、文件后缀、...
SparkSQL 在企业级数仓建设的优势
Hive 有 JDBC 客户端,支持标准 JDBC 接口访问的 HiveServer2 服务器,管理元数据服务的 Hive Metastore,以及任务以 MapReduce 分布式任务运行在 YARN上。标准的 JDBC 接口,标准的 SQL 服务器,分布式任务执行,以及... 再次重试所消耗的时间几乎等于全新重新提交一个任务,在分布式任务的背景下,任务运行的时间越长,出现错误的概率越高,对于此类组件的使用业界最佳实践的建议也是不超过30分钟左右的查询使用这类引擎是比较合适的。...
EMR Flink SQL
大数据分析或分布式数据自治服务后,才可创建火山引擎 E-MapReduce(EMR)流式数据开发任务。 EMR 引擎绑定的集群类型、版本及依赖的服务,需满足以下条件之一,方可创建 EMR Flink SQL 任务: 支持集群版本 支持集群类... 获取 bootstrap.servers,具体操作请参考:使用默认接入点连接实例。 4 EMR Flink SQL任务配置说明4.1 新建任务选择流式数据 > EMR Flink SQL 任务类型新建任务。 登录DataLeap租户控制台。 在概览界面,显示加入...
