在集群的全部资源上运行多个Spark文件,是否可能?
 社区干货
社区干货
万字长文,Spark 架构原理和 RDD 算子详解一网打进! | 社区征文
就可以开始正式执行 spark 应用程序了。第一步是创建 RDD,读取数据源;> - HDFS 文件被读取到多个 Worker节点,形成内存中的分布式数据集,也就是初始RDD;> - Driver会根据程序对RDD的定义的操作,提交 Task 到 Exec... 它包含了**数据应该在哪算,具体该怎么算,算完了放在哪个地方**。它是能被序列化,也能被反序列化。在开发的时候,RDD给人的感觉就是一个只读的数据。但是不是,RDD存储的不是数据,而是数据的位置,数据的类型,获取数据...
字节跳动 Spark Shuffle 大规模云原生化演进实践
两个阶段— Shuffle Write 和 Shuffle Read。Shuffle Write 的时候,Mapper 会把当前的 Partition 按照 Reduce 的 Partition 分成 R 个新的 Partition 并排序后写到本地磁盘上。生成的 Map Output 包含两个文件:索引... **云原生化后的 Spark 作业目前有两个主要的运行环境:**- **稳定资源集群环境**。这些稳定资源的集群主要以服务高优和 SLA 的任务为主。部署的磁盘是性能比较好的 SSD 磁盘。对于这些稳定资源集群,主要使用基于...
计算引擎在K8S上的实践|社区征文
将Spark计算任务从Yarn迁移至K8S上运行。# 最初的尝试spark-thrift-server考虑到我们服务的客户数据量都不是很大,并且在数据相关的场景中都是基于SQL来实现。上半年我们在离线业务中首先选择了spark-thrift-server。spark-thrift-server的本质其实就是一个Spark Application,和我们单独提交Spark Jar包任务到集群是一样的,也会启动一个Driver和多个Executor。因此这一步要做的其实就是将其提交到K8S集群上,并启动Driver对应...
2022技术盘点之平台云原生架构演进之道|社区征文
自建Kubernetes集群进行业务容器编排管理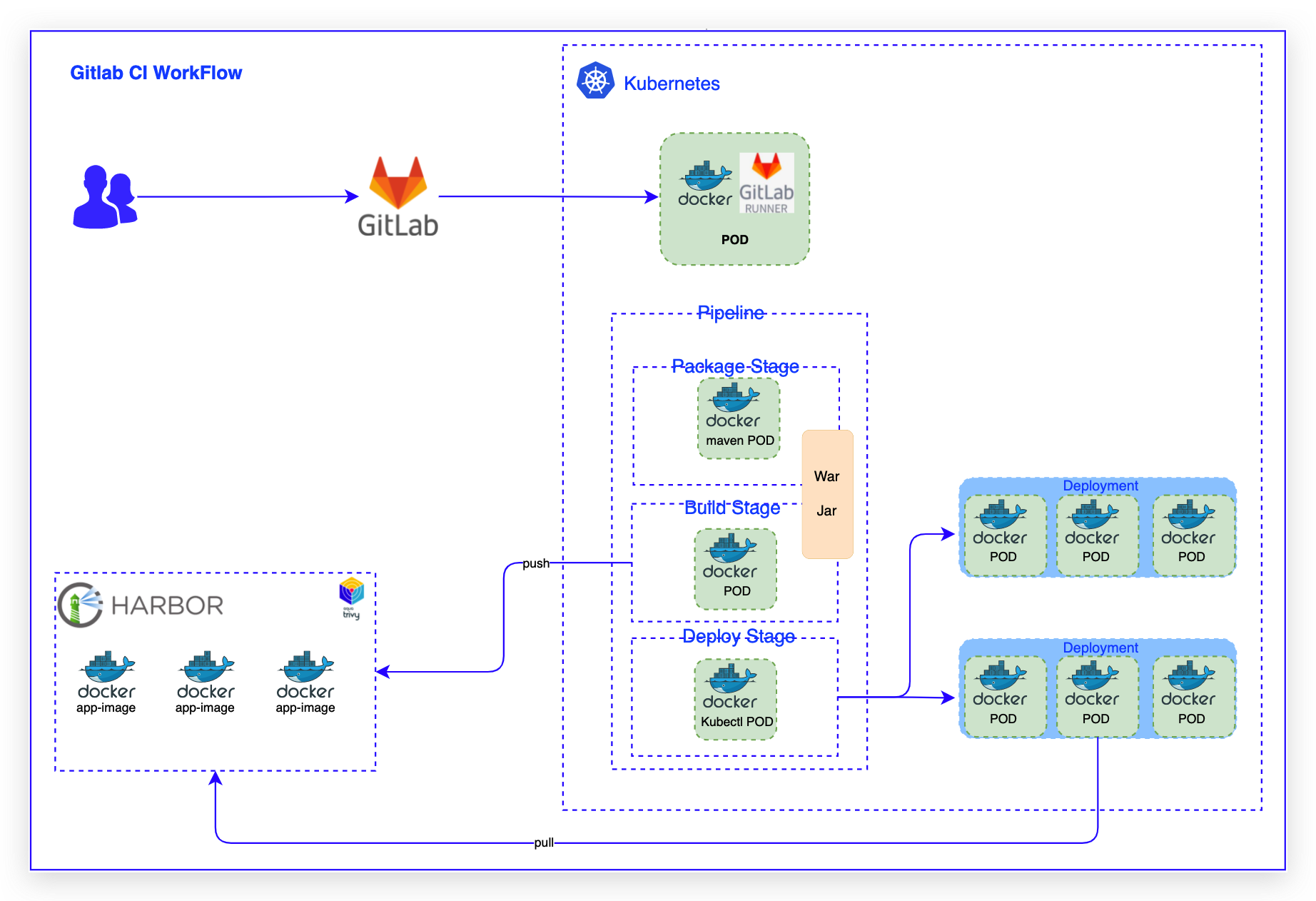- 高可用:当某个节点出现故障时,Kubernetes 会自动创建一个新的 GitLab-Runner 容器,并挂载同样的 Runner 配置,使服务达到高可用。- 弹性伸缩:触发式任务,合理使用资源,每次运行脚本任务时,Gitlab-Runner 会自动创建一个或多个新的临时 Runner来运行Job。- 资源最大化利用:动态创...
 特惠活动
特惠活动
 在集群的全部资源上运行多个Spark文件,是否可能?-优选内容
在集群的全部资源上运行多个Spark文件,是否可能?-优选内容
 在集群的全部资源上运行多个Spark文件,是否可能?-相关内容
在集群的全部资源上运行多个Spark文件,是否可能?-相关内容
基于火山引擎 EMR 构建企业级数据湖仓
最后有一个问题:Table Format 是不是一个终极武器?我们认为答案是否定的。主要有几方面的原因:- 使用体验离预期有差距:由于 Table Format 设计上的原因,流式写入的效率不高,写入越频繁小文件问题就越严重; - ... 不可避免地要朝精细化的内存管理以及高效的执行这个方向发展。现在我们看到在计算方面,社区出现了两个趋势:Native 化和向量化(Vectorized)。 Native 化有两个典型的代表:- Spark:去年官宣了 Photon 项目,宣称...
揭秘字节跳动云原生 Spark History 服务 UIService
**开源 Spark History Server 流程图**Spark History 建立在 Spark 事件(Spark Event)体系之上。在 Spark 任务运行期间会产生大量包含运行信息的 SparkListenerEvent,例如 ApplicationStart / StageCompleted / ... Event log 文件中的每一行是一个序列化的 event,将它们逐行反序列化,并使用 ReplayListener 将其中信息反馈到 KVStore 中,还原任务的状态。无论运行时还是 History Server,任务状态都存储在有限几个类的实例中,...
字节跳动 Spark 支持万卡模型推理实践
字节跳动拥有业界领先的 Spark 业务规模,每天运行数百万的离线作业,占有资源量数百万核,GPU 数万张卡,总集群规模节点也达到了上万台。如此大规模的 Spark 负载意味着要实现 Spark 彻底原生化不是一件容易的事情。以... 如果多个共享的进程有一个在执行 Kernel 时被 Kill,容易引发硬件层面的 Fatal Exception,会导致此 GPU 上的其他进程一起退出,因此对于每个进程的优雅退出处理十分必要。在 K8s 上运行可能会因为某些调度原因导...
字节跳动 MapReduce - Spark 平滑迁移实践
集群的物理机上直接提交的。 **为什么要推动****MapReduce 迁移 Spark**推动 MapReduce 下线有以下三个原因:第一个原因是 **MapReduce 的运行模式对计算调度引擎吞吐的要求过高** 。MapR... 第四步是运行用户提供的 Reduce 代码;第五步是把 Reduce 代码处理的结果写到 HDFS 文件系统中。实际上 MapReduce 还有一个十分广泛的用法,就是 Map Only,即没有下图中间两个步骤的用法。体系之上。在 Spark 任务运行期间会产生大量包含运行信息的`SparkListenerEvent`,例如 ApplicationStart / StageCompleted / MetricsUpdate 等等,都有对应的 `Spa... Event log 文件中的每一行是一个序列化的 event,将它们逐行反序列化,并使用 `ReplayListener`将其中信息反馈到 `KVStore` 中,还原任务的状态。无论运行时还是 History Server,任务状态都存储在有限几个类的实例中...
