postgresql常
 社区干货
社区干货
一位老IT的2023年的技术总结 |社区征文
PostgreSQL就是典型的服务端成功例子,通过它们实现架构耦合,三个产品已经在世界上非常成熟。因为信创,我国的基础软件也有起跑线,openGauss基于PostgreSQL9.2.4基础上研发的,但是完全 消化了PostgreSQL9.2.4的内核代码,OceanBase是阿里主导的100%的自我研发产品,而TiDB也有自己的独立自主研发能力,**三个产品都能做到自主研发可控,对没有强依赖**。反观某些国产数据库产品存在强依赖,依附MySQL、PostgreSQL上面套层皮,或者改造...
2022 年每个开发者必知的云原生趋势 | 社区征文
PostgreSQL)- 消息队列(Kafka, RabbitMQ)- 文件存储(NFS,FTP)- 日志服务- 缓存系统- SMTP服务你可以管理自己的后端服务,也可以让云厂商代管。云厂商提供丰富的后端服务,你无需拥有该服务,而是可以直接消费。云厂商操作大规模的资源,并承担性能、安全和维护的责任。云原生系统倾向于云厂商提供的后端服务。在这方面,我们可以在时间和劳动力上节约很多。如果是自己托管,那么遇到的运行风险会比较麻烦。最佳实践是将后端...
浅谈大数据建模的主要技术:维度建模 | 社区征文
通常来说,事实常以数值形式出现,而且一般都被大量文本形式的上下文包围着。这些文本形式的上下文描述了事实的“ 5个W ”( When 、 Where 、 What 、 Who 、 Why )信息,通常可被直观地分割为独立的逻辑块,每一个独立的逻辑块即为一个维度,比如一个订单可以非常直观地分为商品 、买家、卖家等多个维度。在维度建模和设计过程中,可以根据需求描述或者基于现有报表,很容易地将信息和分析需求分类到事实和度量中。比如业务人员需...
数据服务基础能力之元数据管理 | 社区征文
# 一、业务背景## 1、应用场景在多变的数据服务场景中,应用中常见如下的业务需求,通过对多种数据结构的灵活组合,快速实现业务模型构建,整体示意图如下: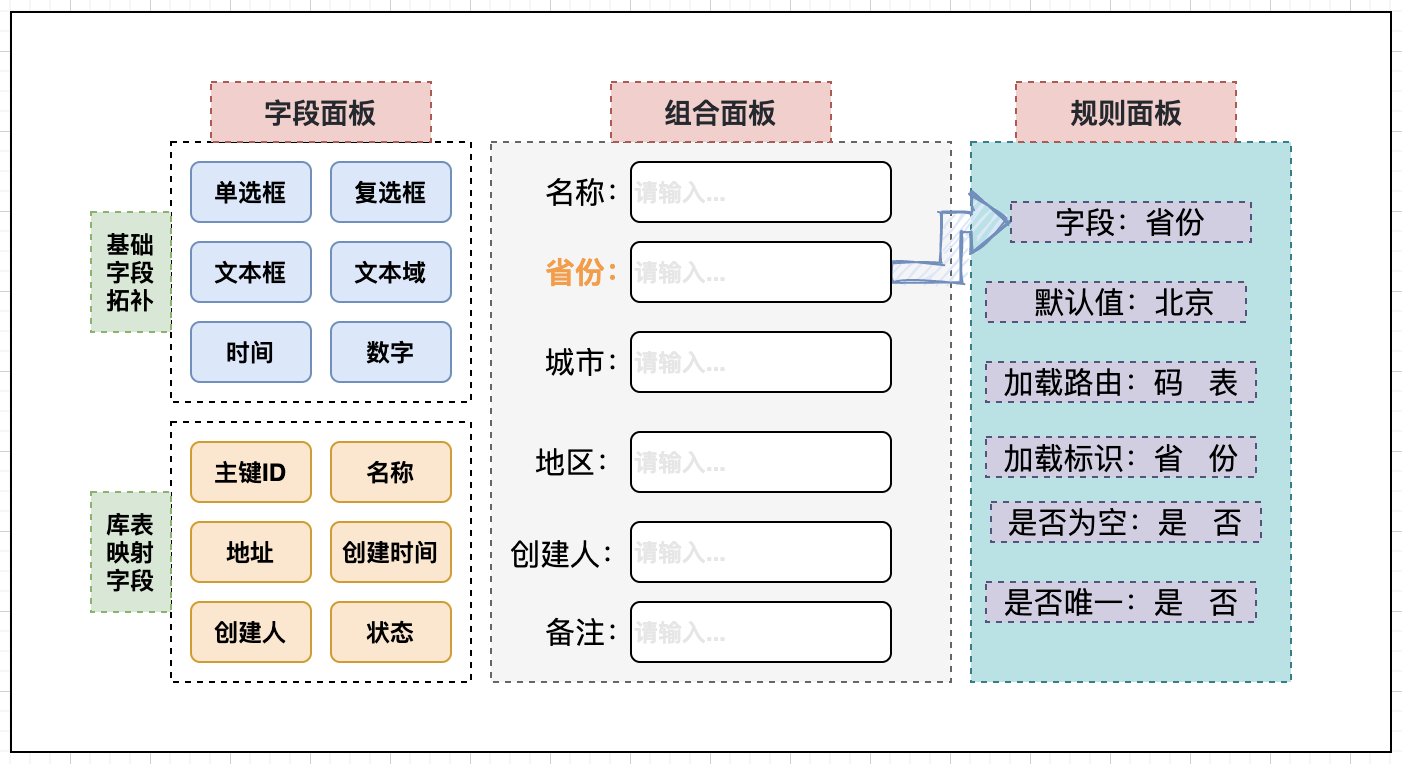像常用的画图工具,左边提供基础图形库,中间是画布,右边是组件的控制细节,对比到这里的逻辑如下:- 字段面板:提供业务数据结构的字段映射,和常规字段类型配置,用来支撑组合面板的表...
 特惠活动
特惠活动
 postgresql常-优选内容
postgresql常-优选内容
 postgresql常-相关内容
postgresql常-相关内容
表设计之数据类型优化 | 社区征文
## 1. 概述MySQL 支持的数据类型非常多,选择正确的数据类型对于获得高性能至关重要。不管存储哪种类型的数据,下面几个简单的原则都有助于做出更好的选择。## 2. 基本原则### 2.1 越小越好一般情况下,应该尽量使用可以正确存储数据的最小数据类型。更小的数据类型通常更快,因为它们占用更少的磁盘、内存和 CPU 缓存,并且处理时需要的 CPU 周期也更少。但是要确保没有低估需要存储的值的范围,因为在的多个地方增加数据类...
DescribeFileSystems
常用于 Linux 客户端。 SnapshotCount Integer 1 快照数量。 FileSystemName String lytest 文件系统名称。 FileSystemType String Extreme 文件系统类型。取值说明如下: Extreme:NAS 极速型。 InodeLimit Long Tag参数 类型 示例值 描述 Key String tagkey 标签键。 Type String Custom 标签类型,说明如下: Custom: 用户自定义标签。 System: 系统标签。 Value String tagvalue 标签值。 Capacity参数 类型 示例值 描...
GetVulnerabilityConfig-查看漏洞防护配置
normal:采用正常模式的漏洞规则。 loose:采用宽松模式的漏洞防护规则。 custom:采用自定义模式的漏洞防护规则,可以对单条漏洞规则进行开启和关闭。 AdvanceConfig AdvanceConfig object - 漏洞防护的高级配置,目前支持对于目录遍历攻击和高频扫描攻击的自动封禁。 RuleSetInfo RuleSetInfo object - 漏洞规则一级分类的详细信息。 AdvanceConfig参数 类型 示例值 描述 AutoTraversal AutoTraversal object - 目...
海量笔记@在云上,如何搭建属于自己的全文搜索引擎 Web应用-个人站点 | 社区征文
业务数据量非常之大的话,除了系统前后台代码本身质量优化之外,服务器配置(物理机or虚拟机or云主机)还可选择更高配些! Ok,now,有了这些前提条件,接下来开始**安装部署**我们**译点笔记应用**-所需要的**服务组件**: ## 系统环境准备**系统环境**首先,在云后台-防火墙配置好需要外网访问的端口(IP+PORT解析-公网IP或域名外网访问)。、节点端口访问(NodePort)。 端口映射 配置端口映射规则。配置说明如下: 名称:配置服务端口到其他服务或容器端口映射的名称。 服务端口:配置 Service 对外提供服务的端口。取值范围:0~65535。同一种协议的服务端口不允许重复。 节点端口:配置节点对内/对外提...
LAS Spark+云原生:数据分析全新解决方案
Kubernetes(常简称为 k8s)是一个开源的容器编排平台,用于自动化部署、扩展和管理容器化应用程序。它提供了一个强大的容器编排和管理系统,可以简化应用程序的部署、扩展和管理过程。Kubernetes 最初由 Google 开发,并于 2014 年开源。它基于 Google 内部的 Borg 系统的经验和技术,并吸收了社区的贡献和反馈,逐渐成为容器编排领域的事实标准。Kubernetes 的架构是高度可扩展化的,它由一组核心组件和插件组成。开发者可以通过插...
基于共享存储的 leader 选举:在存算分离架构云数仓 ByConity 中的实践
点击上方👆蓝字关注我们! 项目地址|https://github.com/ByConity/ByConity 背景 在传统常见的分布式 share-nothing 微服务架构...
临时查询
为确保能在 DataLeap 上正常进行数据查询,需保证相关端口一直存在于安全组中,不要删除。详见创建项目。 3 功能介绍 3.1 进入临时查询登录 DataLeap租户控制台 。 在概览界面,显示加入的项目中,单击数据开发进入对应项目。 在任务开发界面,左侧导航栏中,单击临时查询按钮,进入临时查询页面。 3.2 新建查询单击新建查询按钮,进入新建查询对话框。 填写以下参数信息,单击确定后,进入临时查询语句编辑界面。 参数 描述 绑定引擎...
为君作磐石——人人都能搭建大规模推荐系统
大规模是指数据量和模型非常大,训练样本达到百亿甚至数万亿,单个模型达到 TB 甚至 10TB 以上;实时化是指特征、模型、候选实时更新;精细化则在特征工程、模型结构、优化方法等多方面有所体现,各种创新思路层出不穷。大规模推荐系统的落地,工程挑战很大。本文选择大家最关心的 Training 和 Serving 系统,介绍搭建过程中会遇到哪些挑战,我们做了哪些工作。对任何一家公司来说,从 0 搭建这样一套系统都绝非易事,投入非常大。在字节...
