小元素和大元素的排列
 社区干货
社区干货
golang pprof
执行`top`命令可以可以看到占用量逆序排列的函数,如下。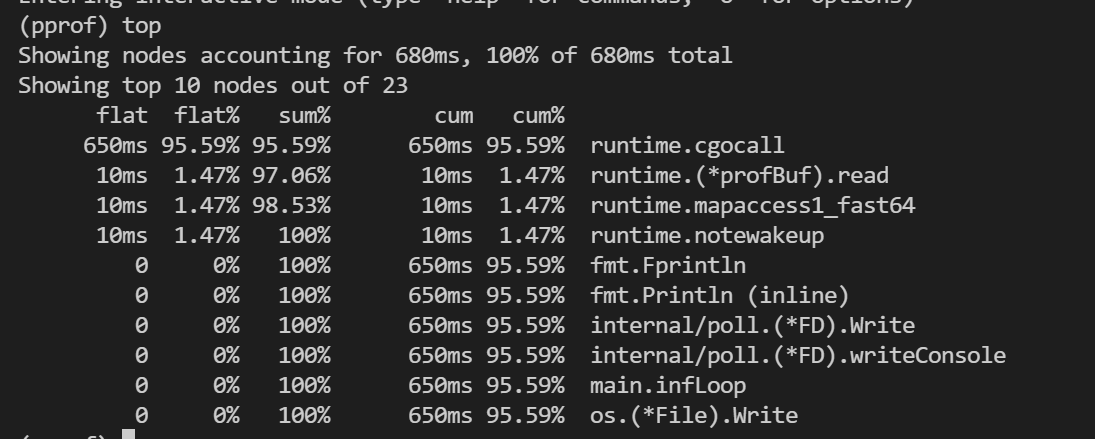可以看到总共有6列信息,这六列分别是| **列名** | **解释** || ------ | ------------------------------------------------------------------------------ || ...
万字长文带你漫游数据结构世界|社区征文
**数据元素是数据的基本单位**,而任何问题中,数据元素都不是独立存在的,它们之间总是存在着某种关系,这种**数据元素之间的关系我们称之为结构**。因此,我们有了以下定义:> 数据结构是[计算机](https://baike.b... 排序后的链表,还是只能知道头尾节点,知道中间的范围,但是要找到中间的节点,还是得走遍历的老路。如果我们把中间节点存储起来呢?存起来,确实我们就知道数据在前一半,还是在后一半。比如找`7`,肯定就从中间节点开始找...
基于 LoserTree 的 Paimon 多路归并优化
堆排序是以堆作为排序的数据结构设计的算法。堆是一棵完全二叉树,根据父节点中存储的值是否都大于或小于子节点的值,又分为大根堆和小根堆。以小根堆为例,排序过程分为建堆和堆调整两个过程。在整个排序过程中,如果父子节点进行比较后发生了数据交换,那么会产生自顶向下的调整,这种调整每次都需要和两个子节点同时进行比较。1. **建堆**假设有 5 个待排序列,第一步需要将这 5 个待排序列的按照头元素的大小调整为小根堆,调...
集简云流程新增循环串行功能,保证数据处理与业务流程的有序执行
对数据排序要求较高的场景来说并不适用。为此,集简云新增**循环串行**功能,可以确保在循环中处理的元素序列按照特定的顺序进行。在需要精确控制数据处理顺序的场景中,循环串行功能显得尤为重要。 **应用场景*** **数据处理和排序**:当数据的处理顺序对最终结果有重要影响时,循环串行功能可以确保数据按照预定的顺序进行处理。* **业务流程管理**:在需要严格按照流程顺序执行任务...
 特惠活动
特惠活动
 小元素和大元素的排列-优选内容
小元素和大元素的排列-优选内容
 小元素和大元素的排列-相关内容
小元素和大元素的排列-相关内容
基于 LoserTree 的 Paimon 多路归并优化
**2.1 堆排序**堆排序是以堆作为排序的数据结构设计的算法。堆是一棵完全二叉树,根据父节点中存储的值是否都大于或小于子节点的值,又分为大根堆和小根堆。以小根堆为例,排序过程分为建堆和堆调整两个过程。在整个排序过程中,如果父子节点进行比较后发生了数据交换,那么会产生自顶向下的调整,这种调整每次都需要和两个子节点同时进行比较。1. **建堆**假设有 5 个待排序列,第一步需要将这 5 个待排序列的按照头元素的大小调...
函数概览
本文档罗列了日志服务所支持的 SQL 函数。 注意 日志服务产品架构升级,支持更丰富的检索分析功能。 如果控制台提示新一代架构正式发布信息,表示您使用的是 2.0 架构,可参考本文档使用相关功能。 如果控制台未提示新一代架构正式发布信息,表示您使用的是 1.0 架构,可参考检索分析(1.0 架构)中的检索概述等文档使用相关功能。 关于 1.0 架构与 2.0 架构的具体说明,请参考日志服务架构升级通知。 聚合函数函数名称 函数语法 说明...
数组函数
使用指定的连接符将数组中的元素拼接为一个字符串。如果数组中包含 NULL 元素,则指定其他字符串代替 NULL 元素。 ARRAY_MAX 函数 ARRAY_MAX(KEY) 计算数组元素中的最大值。 ARRAY_MIN 函数 ARRAY_MIN(KEY) 计算数组元素中的最小值。 ARRAY_REMOVE 函数 ARRAY_REMOVE(KEY, element) 删除数组中的某个元素。 ARRAY_SORT 函数 ARRAY_SORT(KEY) 对数组中的元素进行升序排序。如果存在 NULL 元素,则将 NULL 元素排在最后...
ListObjects
max-keys Query Integer 否 100 返回对象的最大数量。最大值为 1000,即一次请求最多返回 1000 个对象。 prefix Query String 否 abc 列举指定前缀的对象。 marker Query String 否 test.txt 列举对象的起始位置。设定从该值之后按字母排序返回对象列表。通常为上次请求返回体的 NextMarker 值。 请求元素该请求中无请求消息元素。 响应消息头该请求返回的公共响应消息头,请参见公共参数。 响应元素名称 参...
最新动态(2024年前)
大于5%,使用序贯检验可以在这种场景下保证p-value小于5%,便于提前做出决策。 开启序贯检验后无法使用流量计算器 2. 多客群实验:即针对某一个方案,通过挑选不同的客群,测试当下方案的最优质客群的实验。实验报告多维分析增加「群体对比」能力,使用蒙特卡洛方法,得出每个方案/人群为最优的概率3. 可视化3.2: 支持元素尺寸相关CSS样式编辑 系统管理:全局操作历史,可从全局角度下查看所有实验和Feature的变更记录 5. 系统管理:白名单...
数据库顶会 VLDB 2023 论文解读:Krypton: 字节跳动实时服务分析 SQL 引擎设计
[picture.image](https://p6-volc-community-sign.byteimg.com/tos-cn-i-tlddhu82om/67969270714349a7ae7fa890f60b451d~tplv-tlddhu82om-image.image?=&rk3s=8031ce6d&x-expires=1715703658&x-signature=7lNl2ZZy%2FrCg%2FUeLol5RG94R2bI%3D)“ **Krypton 源于 DC 宇宙中的氪星,它是超人的故乡,以氪元素命名**” **引言** 近些年, 在复杂的分析需求之外,字节内部的业务...
干货|七个方向,基于开源工具构建一款智能化BI
并且支持在表头上进行排序、固定列、字段配置等功能菜单。 ) 计算精确百分位数,适用于小数据量。先对指定列升序排列,然后取精确的第p位百分数。p必须在0和1之间。 POW plain double 计算x的y次方,即x^y。decimal pow(, ) UNIX_TIMESTAMP plain bigint unix_timestamp(datetimestring ) 将日期date转化为整型的UNIX格式的日期时间值。date ARRAY_JOIN plain array_join(array , [, ]) 将ARRAY数组a中的元素使用delimiter拼接为字符串。当数组中元素为NULL时,用nullreplacement替...
DescribeBigKeys
时间间隔不超过 1 小时。 KeyType String 否 list 指定数据类型来过滤大 Key 查询结果。支持的数据类型为 string、list、set、zset 和 hash。 说明 若该参数留空,默认查询目标实例中所有数据类型的大 Key 详情。 OrderBy String 否 ValueSize 指定查询结果的排序条件。支持的排序条件如下: ValueSize(默认值):按内存占用对大 Key 查询结果进行排序。 ValueLen:按元素数量对大 Key 查询结果进行排序。 返回数据名称 ...
