机器学习怎么学
 社区干货
社区干货
浅谈AI机器学习及实践总结 | 社区征文
半监督学习:有的数据有标签、有的数据没有标签。往往是因为获取数据标签的难度很高,半监督学习与监督学习是很相似的,主要在与多了伪标签生成环节,也就是给无标签的数据人工 贴标签。半监督分类、半监督回归、半监督聚类、半监督降维- 强化学习:针对于一些既不能用监督学习也不能用半监督和无监督学习来解决,这时候强化学习就上场了,它针对是智能体(可以理解成一种机器学习模型)如何基于环境而做出行动反应,以获得最大化...
我的技术年终总结——机器学习 |社区征文
**预测**:利用训练后的算法完成任务(根据学习的规律为未知数据进行分类和预测) 通过周志华老师西瓜书上面的描述为下图: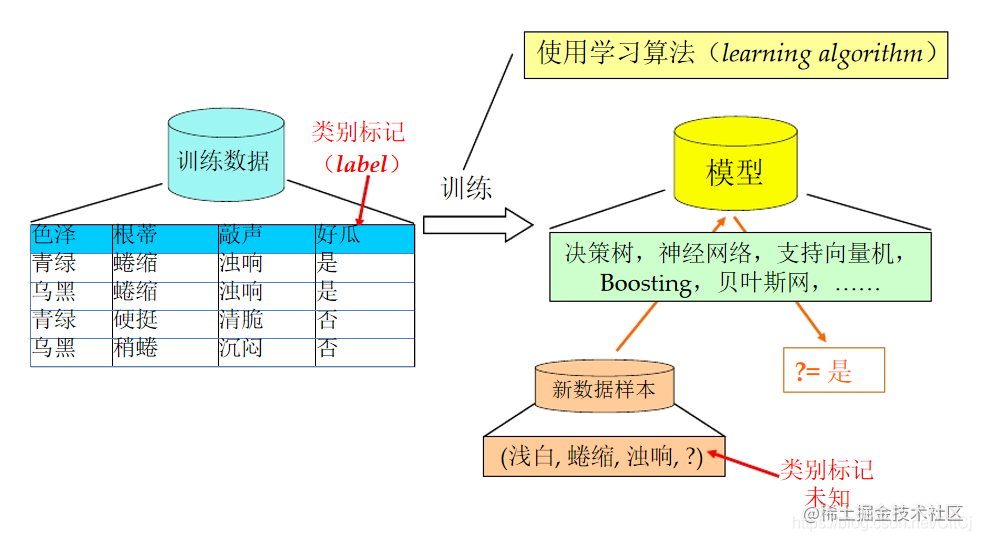## 二、机器学习能做什么? ### 数据集上 一个重要问题: 原书籍已经变成分散且混杂的多个书页,如何拼接相邻的书页? 人工完成书页拼接十分困难书页数...
在线学习FTRL介绍及基于Flink实现在线学习流程|社区征文
# 背景目前互联网已经进入了AI驱动业务发展的阶段,传统的机器学习开发流程基本是以下步骤:数据收集->特征工程->训练模型->评估模型效果->保存模型,并在线上使用训练的有效模型进行预测。这种方式主要存在两个瓶颈:模型更新周期慢,不能有效反映线上的变化,最快小时级别,一般是天级别甚至周级别。另外一个是模型参数少,预测的效果差;模型参数多线上predict的时候需要内存大,QPS无法保证。针对这些问题,一般而言有两种解决方...
如何构建过拟合和防过拟合模型
能够从大量的输入数据中学习和优化模型,以产生更准确、更精确的预测。但是,当机器学习模型过分关注训练数据中的噪声和其他异常因素,而忽略了其他重要特征时,该模型可能会发生“过拟合”。如果模型太简单,而忽略了许多重要特征,则可能会发生“欠拟合”。因此,要构建准确的机器学习模型,用户需要有一种策略来确保模型不会过拟合或欠拟合,以确保预测的准确性。下面,我们将讨论如何构建过拟合和防止过拟合的模型。首先,要构建准确的...
 特惠活动
特惠活动
 机器学习怎么学-优选内容
机器学习怎么学-优选内容
 机器学习怎么学-相关内容
机器学习怎么学-相关内容
在线学习FTRL介绍及基于Flink实现在线学习流程|社区征文
# 背景目前互联网已经进入了AI驱动业务发展的阶段,传统的机器学习开发流程基本是以下步骤:数据收集->特征工程->训练模型->评估模型效果->保存模型,并在线上使用训练的有效模型进行预测。这种方式主要存在两个瓶颈:模型更新周期慢,不能有效反映线上的变化,最快小时级别,一般是天级别甚至周级别。另外一个是模型参数少,预测的效果差;模型参数多线上predict的时候需要内存大,QPS无法保证。针对这些问题,一般而言有两种解决方...
如何构建过拟合和防过拟合模型
能够从大量的输入数据中学习和优化模型,以产生更准确、更精确的预测。但是,当机器学习模型过分关注训练数据中的噪声和其他异常因素,而忽略了其他重要特征时,该模型可能会发生“过拟合”。如果模型太简单,而忽略了许多重要特征,则可能会发生“欠拟合”。因此,要构建准确的机器学习模型,用户需要有一种策略来确保模型不会过拟合或欠拟合,以确保预测的准确性。下面,我们将讨论如何构建过拟合和防止过拟合的模型。首先,要构建准确的...
技术大讲堂精彩回顾& PPT 领取|字节跳动基于 HPC 的大规模机器学习技术
字节跳动经过业务实践打磨的机器学习技术首次亮相开发者社区,由技术负责人项亮公开深度分享;同时,承载机器学习平台的超大规模 HPC 基础设施也首度在社区分享。 **《火山引擎大规模机器学习平台架构设计与应用实践》**项亮|火山引擎机器学习系统负责人本次分享围绕数据加速、模型分布式训练框架建设、大规模异构集群调度、模型开发过程标准化等 AI 工程化实践,全面介绍了如何以开发者的极致体验为核心,进行机...
保姆级人工智能学习成长路径|社区征文
对机器学习和深度学习拥有自己独到的见解。今天给大家分享的是保姆级人工智能学习成长路径,希望能对大家有所帮助,特别是处于迷茫期的同学们。# 0. 前言 最近有很多小伙伴想学习人工智能,其中不少同学渴望从事相关职业。虽然网上的资料很多,但是很多内容不够接地气,导致他们看不懂,所以很迷茫,不知何去何从。作为获得AI比赛Top名次的老司机,就给大家讲讲如何系统学习人工智能,最终达到一名合格的算法工程师。希望大家能够跟...
火山引擎大规模机器学习平台架构设计与应用实践
如何先复现实验结果?团队不同的人做了不同的实验,如何对这些实验进行对比?这些都是有挑战的事情。这些管理问题其实也是机器学习模型训练过程中比较大的痛点。本文将针对这些痛点,介绍我们如何进行机器学习平台的架构设计。## 云原生机器学习平台架构设计我们主要在两方面做了投入:一是高性能计算和存储的规模化调度;二是模型分布式训练的加速。### 高性能计算和存储的规模化调度——挑战#### 计算侧在高性能计算方面...
字节跳动 EB 级 Iceberg 数据湖的机器学习应用与优化
> 深度学习的模型规模越来越庞大,其训练数据量级也成倍增长,这对海量训练数据的存储方案也提出了更高的要求:怎样更高性能地读取训练样本、不使数据读取成为模型训练的瓶颈,怎样更高效地支持特征工程、更便捷地增删和回填特征。本文将介绍字节跳动如何通过 Iceberg 数据湖支持 EB 级机器学习样本存储,实现高性能特征读取和高效特征调研、特征工程加速模型迭代。**相关产品**:https://www.volcengine.com/product/flink # 机...
什么是机器学习平台
火山引擎机器学习平台是面向机器学习应用开发者,提供【开发机】和【自定义训练】等丰富建模工具、多框架高性能模型推理服务的企业级开发平台,支持从数据托管、代码开发、模型训练、模型部署的全生命周期工作流。 产... 最佳实践列举了在机器学习平台上开发项目的一些最佳实践,比如参考数据样本的存储可以了解在机器学习平台上如何存储大规模数据,通过查阅代码示例中的 Demo 能够更加熟悉机器学习常见的训练范式以及 Python SDK的使...
使用机器学习及 vePFS Fileset 实现部门数据及权限的精细化管理
本文介绍如何通过机器学习平台及 vePFS 的 Fileset 功能,实现不同团队的数据及权限的精细化管理。 适用场景如果您的企业对数据安全有较高的要求,您可以通过机器学习平台和文件系统 vePFS,授予开发机特定的 vePFS 数据,实现不同团队的数据及权限的精细化管理,避免数据泄露或者误删除的场景。推荐授权场景如下所示: 团队 数据集权限 运维团队 公共数据集 /public :读写权限 vePFS 完整管理权限(即 / 目录读写权限) 说明 运维团队...
字节跳动 EB 级 Iceberg 数据湖的机器学习应用与优化
深度学习的模型规模越来越庞大,其训练数据量级也成倍增长,这对海量训练数据的存储方案也提出了更高的要求:怎样更高性能地读取训练样本、不使数据读取成为模型训练的瓶颈,怎样更高效地支持特征工程、更便捷地增删和回填特征。本文将介绍字节跳动如何通过 Iceberg 数据湖支持 EB 级机器学习样本存储,实现高性能特征读取和高效特征调研、特征工程加速模型迭代。作者|字节跳动基础架构研发工程师-谢凯 **01...
