Kafkajs消费和生产批处理问题
 社区干货
社区干货
Kafka 消息传递详细研究及代码实现|社区征文
Kafka 是其中之一。Apache Kafka 是一个开源的分布式事件流平台,可跨多台计算机读取、写入、存储和处理事件,并有发布和订阅事件流的特性。本文将研究 Kafka 从生产、存储到消费消息的详细过程。 ## Produce... 生产者发送消息失败或出现潜在暂时性错误时,会进行的重试次数。type: intdefault: 2147483647valid values: [0, ..., 2147483647]importance: high [**batch.size**](url)当多条消息发送到一个分区时...
Kafka@记一次修复Kafka分区所在broker宕机故障引发当前分区不可用思考过程 | 社区征文
业务组内研发童鞋碰到了这样一个问题,反复尝试并研究,包括不限于改Kafka,主题创建删除,Zookeeper配置信息重启服务等等,于是我们来一起看看... Ok,Now,我们还是先来一步步分析它并解决它,依然以”化解“的方式进... 但Kafka的高可用性HA我们是耳熟能详的,为啥我们搭建的Kafka集群由多个节点组成,但其中某个节点宕掉,整个分区就不能正常使用-消费者端无法订阅到消息。 首先,我们来看下Kafka的配置信息:```js[root@xx-xx-xx...
字节跳动新一代云原生消息队列实践
Coordinator 和 Controller。我们依次来看一下这些模块的主要工作:* Proxy 负责接收所有用户的请求,对于生产请求,Proxy 会将其转发给对应的 Broker;对于消费者相关的请求,例如 commit offset,join group 等,Proxy 会将其转发给对应的 Coordinator;对于读请求 Proxy 会直接处理,并将结果返回给客户端。* BMQ 的 Broker 与 Kafka 的 Broker 略有不同,它主要负责写入请求的处理,其余请求交给了 Proxy 和 Coordinator 处理。* ...
消息队列选型之 Kafka vs RabbitMQ
消息队列是一种能实现生产者到消费者单向通信的通信模型,而一般大家说 MQ 是指实现了这个模型的中间件,比如 RabbitMQ、RocketMQ、Kafka 等。我们所要讨论的选型主要是针对消息中间件。**消息队列的应用场景... 我们紧接着面临的问题就是,我们应该在系统内部启动多少线程去从消息队列中获取消息。如果只是单线程去获取消息,那自然没有什么好说的。但是多线程情况,可能就会有问题。因为 RabbitMQ 在官方文档中声明了自己是不保...
 特惠活动
特惠活动
 Kafkajs消费和生产批处理问题-优选内容
Kafkajs消费和生产批处理问题-优选内容
 Kafkajs消费和生产批处理问题-相关内容
Kafkajs消费和生产批处理问题-相关内容
字节跳动基于Apache Atlas的近实时消息同步能力优化 | 社区征文
每台服务器支持的Kafka Consumer数量有限,在每日百万级消息体量下,经常有长延时等问题,影响用户体验。在2020年底,我们针对Atlas的消息消费部分做了重构,将消息的消费和处理从后端服务中剥离出来,并编写了Flink任... 分别是Flink和Kafka Streaming。Flink是我们之前生产上使用的方案,在能力上是符合要求的,最主要的问题是长期的可维护性。在公有云场景,那个阶段Flink服务在火山引擎上还没有发布,我们自己的服务又有严格的时间线...
Kafka数据接入
在跳转的页面选择 火山Kafka 。3. 填写所需的基本信息,并进行 测试连接 。 连接成功后点击 保存 即可。 点击 数据融合>元数据管理 。 点击右上角 新建数据源 ,创建实时数据源时,选择对应用户的kafka连接及Topic; 选择所需Topic后,有两种方式设置Topic中msg到数据源类型(ClickHouse类型)的映射: 1)采用当前Topic内的msg 2)自定义msg的json结构 配置支持嵌套json,需使用jsonpath提取。 示例:outter.inner.cnt表示获取{"outter...
通过 Spark Streaming 消费日志
日志服务提供 Kafka 协议消费功能,您可以使用 Spark Streaming 的 spark-streaming-kafka 组件对接日志服务,通过 Spark Streaming 将日志服务中采集的日志数据消费到下游的大数据组件或者数据仓库。 场景概述Spark... []) Arrays.asList(ConsumerRecord.class).toArray());// 每隔5秒钟,sparkStreaming作业就会收集最近5秒内的数据源接收过来的数据JavaStreamingContext jssc = new JavaStreamingContext(conf, Durations.seconds(...
20000字详解大厂实时数仓建设 | 社区征文
最终基于顺风车数仓 ods 层建设规范分主题统一写入 kafka 存储介质中。命名规范:ODS 层实时数据源主要包括两种。- 一种是在离线采集时已经自动生产的 DDMQ 或者是 Kafka topic,这类型的数据命名方式为采集系统... 整个链路要避免批处理,如果出现了一些任务性能的单点问题,我们还要保证高性能和可扩容。_2.2 技术方案_针对以上问题,介绍一下我们是怎么做的: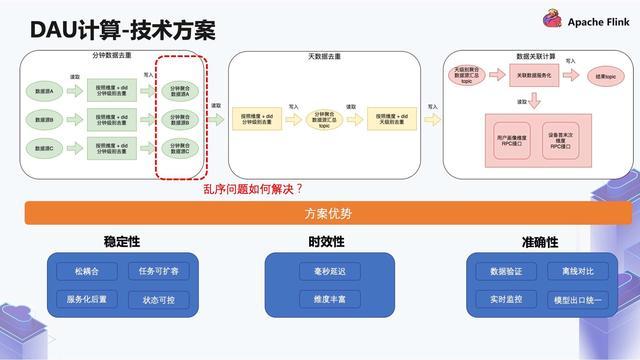...
大象在云端起舞:后 Hadoop 时代的字节跳动云原生计算平台
还是后来涌现出来的 Kafka、Flink 等,都被广泛地使用着。十多年来,这些系统经历了多轮技术洗礼,我们也随之需要根据新的技术潮流不断地进行调整甚至做技术转型。以 Hadoop 三大组件来说,计算引擎 MapReduce 基本... 生产上的最新数据,而批处理每天跑一下历史报表。有时候两支团队的数据和程序没办法对齐,会得出不一致的结果,这时候使用流批一体变成一支团队体验更为友好。然而推荐场景下,流式计算本身存在一个问题,会因为一些...
大象在云端起舞:后 Hadoop 时代的字节跳动云原生计算平台
还是后来涌现出来的 Kafka、Flink 等,都被广泛地使用着。十多年来,这些系统经历了多轮技术洗礼,我们也随之需要根据新的技术潮流不断地进行调整甚至做技术转型。以 Hadoop 三大组件来说,计算引擎 MapReduce 基本被... 生产上的最新数据,而批处理每天跑一下历史报表。有时候两支团队的数据和程序没办法对齐,会得出不一致的结果,这时候使用流批一体变成一支团队体验更为友好。然而推荐场景下,流式计算本身存在一个问题,会因为一些数...
干货|字节跳动基于Flink SQL的流式数据质量监控
> 目前,字节跳动数据质量平台对于批处理数据的质量管理能力已经十分丰富,提供了包括表行数、空值、异常值、重复值、异常指标等多种模板的数据质量监控能力,也提供了基于spark的自定义监控能力。另外,该平台还提供了... 问题提供了便利的手段。本文分上下两次连载,作者系**字节跳动数据平台-开发套件团队-高级研发工程师 于啸雨**。长期以来,数据质量平台的各项能力都只支持batch数据源(主要是Hive),没有流式数据源(如kafka)的质量...
【GMP3.11】Webhook通道接入
生产环境配置完生产通道之后,请务必使用测试人群包创建任务进行至少一次全链路性能测试,确保当前的QPS、batchSize等设置合理,避免生产过程中出现打爆下游接口的情况。 当前通用webhook的能力边界:(2022-08-19)支持... 避免因失败重试等导致用户重复触达等客情问题 支持被动接受json回执,但是是基于流水号/消息ID的单个回执支持主动轮询json回执,但是是基于流水号/消息ID的单个查询支持批量发送与批量响应支持kafka/rmq的发送与接收...
干货丨字节跳动基于 Apache Hudi 的湖仓一体方案及应用实践
通过分开批处理和流处理两套链路,把复杂性隔离到流处理,可以很好的提高整个系统的鲁棒性和可靠性。 具有上述优点的同时,Lambda 架构同样存在一系列尚待优化的问题,**涉及到计算、运维、成本等方面**: **●**... Hudi 作为数据湖框架的一种开源实现,其核心特性能够满足对于实时/离线存储层统一的诉求:**●**支持实时消费增量数据:**提供 Streaming Source/Sink 能力**,数据分钟级可见可查; **●**支持离线批量更新数据:保...
