对象存储的磁盘阵列
 社区干货
社区干货
Linux操作系统挂载多个数据盘如何做软raid
虚拟存储系统,又称为独立冗余磁盘阵列,其思想是将多块独立的磁盘按照不同的方式组成成一个逻辑磁盘,从而提高存储容量,提升存储容量,提升存储性能或提供数据备份功能。RAID又分为硬RAID和软RAID。软RAID可以实现和... RAID5,这是最常见的RAID类型。通过在阵列的所有成员磁盘驱动器上分配奇偶校验。RAID5具有不对称的性能,并且读取性能大大优于写入。5. RAID6,当性能问题代替数据冗余和保存成为最重要的问题时,RAID6是最常使用的R...
火山引擎云存储选型指南 x 自动驾驶场景最佳实践
在大部分业务场景中做云存储大类的选型是相对容易的,比如要为云服务器配置系统盘或数据盘会使用块存储,存放视频、图片、游戏安装包等文件优选对象存储,但在某些业务场景(AI、HPC、大数据等)用户往往面临多样化的选... 用户可以将需要迁移的数据写入硬盘或磁盘阵列等物理设备,然后将物理设备通过邮寄等形式运输到火山引擎机房,实现数据的离线迁移。数据闪送服务支持使用火山硬盘或者用户自有硬盘,用户只需要在数据闪送控制台创...
免费公测|火山引擎大数据文件存储公测现已开启!
计算资源和存储资源扩容速度不匹配 ,不同时期需要不同的存储空间和计算能力配比,导致机器选型不便;2. 计算资源和存储资源按某一比例强绑定,系统扩容必须按节点数目增加,导致内存或磁盘的浪费;3. 在云计算场景下,因计算集群中包含数据,导致不能实现真正的弹性计算。企业可以通过云上存算分离架构,以低成本的对象存储作为存储底座,完美地解决以上问题。而针对在大数据和机器学习场景下,由对象存储带来的诸如存储性能(IO...
免费公测|火山引擎大数据文件存储公测现已开启!
3. 在云计算场景下,因计算集群中包含数据,导致不能实现真正的弹性计算。企业可以通过云上存算分离架构,以低成本的对象存储作为存储底座,完美地解决以上问题。而针对在大数据和机器学习场景下,由对象存储带来的诸如存储性能(IO 瓶颈)、接口兼容性等问题,火山引擎推出自研的**大数据文件存储(CloudFS)** 作为解决方案。火山引擎大数据文件存储以对象存储为底座,针对大数据和机器学习场景进行了完整的兼容和优化,助力更多企业...
 特惠活动
特惠活动
 对象存储的磁盘阵列-优选内容
对象存储的磁盘阵列-优选内容
 对象存储的磁盘阵列-相关内容
对象存储的磁盘阵列-相关内容
火山引擎云存储选型指南 x 自动驾驶场景最佳实践
在大部分业务场景中做云存储大类的选型是相对容易的,比如要为云服务器配置系统盘或数据盘会使用块存储,存放视频、图片、游戏安装包等文件优选对象存储,但在某些业务场景(AI、HPC、大数据等)用户往往面临多样化的选... 用户可以将需要迁移的数据写入硬盘或磁盘阵列等物理设备,然后将物理设备通过邮寄等形式运输到火山引擎机房,实现数据的离线迁移。数据闪送服务支持使用火山硬盘或者用户自有硬盘,用户只需要在数据闪送控制台创...
免费公测|火山引擎大数据文件存储公测现已开启!
计算资源和存储资源扩容速度不匹配 ,不同时期需要不同的存储空间和计算能力配比,导致机器选型不便;2. 计算资源和存储资源按某一比例强绑定,系统扩容必须按节点数目增加,导致内存或磁盘的浪费;3. 在云计算场景下,因计算集群中包含数据,导致不能实现真正的弹性计算。企业可以通过云上存算分离架构,以低成本的对象存储作为存储底座,完美地解决以上问题。而针对在大数据和机器学习场景下,由对象存储带来的诸如存储性能(IO...
免费公测|火山引擎大数据文件存储公测现已开启!
3. 在云计算场景下,因计算集群中包含数据,导致不能实现真正的弹性计算。企业可以通过云上存算分离架构,以低成本的对象存储作为存储底座,完美地解决以上问题。而针对在大数据和机器学习场景下,由对象存储带来的诸如存储性能(IO 瓶颈)、接口兼容性等问题,火山引擎推出自研的**大数据文件存储(CloudFS)** 作为解决方案。火山引擎大数据文件存储以对象存储为底座,针对大数据和机器学习场景进行了完整的兼容和优化,助力更多企业...
火山引擎云存储选型指南 x 自动驾驶场景最佳实践
在大部分业务场景中做云存储大类的选型是相对容易的,比如要为云服务器配置系统盘或数据盘会使用块存储,存放视频、图片、游戏安装包等文件优选对象存储,但在某些业务场景(AI、HPC、大数据等)用户往往面临多样化的选... 用户可以将需要迁移的数据写入硬盘或磁盘阵列等物理设备,然后将物理设备通过邮寄等形式运输到火山引擎机房,实现数据的离线迁移。数据闪送服务支持使用火山硬盘或者用户自有硬盘,用户只需要在数据闪送控制台创建服...
搭建Ceph
Ceph是一种开源分布式文件系统,具有高可靠、自动重均衡、灵活扩展等特点,支持对象存储、块存储以及文件存储。本文为您介绍如何搭建Ceph。 Ceph充分利用节点的计算能力,通过Crush算法计算文件位置,使数据均衡分布,避... 在设置密钥保存位置时回车即可。 ssh-keygen -t rsa -P ''ssh-copy-id ceph-node1ssh-copy-id ceph-node2ssh-copy-id ceph-node3ssh-copy-id ceph-client 安装 Ansible。 执行以下命令,安装 Ansible。 yum instal...
ECS 云服务器自定义镜像导入
## 实验名称云服务器自定义镜像导入## 实验介绍本期实验练习介绍了如何向火山引擎导入一个自定义镜像文件,并转换为镜像。在开始实验前需要先进行如下准备工作:- TOS对象存储中创建存储桶- 安装VirtualBox虚拟... 选择现在创建虚拟硬盘,并点击下一步。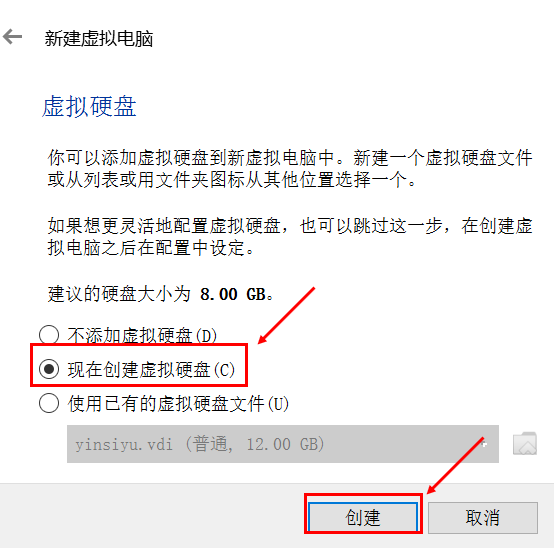4. 磁盘类型选择VDI,下一步。,您需要根据的对象数量预估需要的磁盘占用量,保证足够磁盘空间。迁移完成后,删除迁移任务会自动删除这些中间结果...
新功能发布记录
2024-03-14 对象存储卷支持挂载根目录 对象存储卷支持通过控制台配置挂载根目录,提升用户使用体验。 华北 2 (北京) 2024-03-18 使用对象存储静态存储卷 华南 1 (广州) 2024-03-13 华东 2 (上海) 2024-03-14 对接 ... 2023-03-09 支持集群审计功能 集群审计支持将 API Server 的每个请求事件采集并保存到日志服务中。当集群发生重大事件时,管理员可以通过查看集群审计的日志,追溯重大事件发生的时间、原因。能够满足服务的安全合规...
字节跳动 EB 级 Iceberg 数据湖的机器学习应用与优化
传统样本存储是将样本**直接存放在** ******HDFS** **、对象存储或者** ******Hive** ******上的方案**。这种方案在处理海量样本时会遇到性能瓶颈。由于采用了单点 List 操作,扫描海量样本时会变得非常缓慢。另外,... 溢出磁盘引起额外 IO 等。此外 Hudi 不支持原生 Python API,只能通过 PySpark 的方式对于算法工程师来说不太友好。- Apache Iceberg 是一种开放的表格式,记录了一张表的元数据:包括表的 Schema、文件、分区、统...
