K8s新手问题:如何让minikube运行singularity-cri
 社区干货
社区干货
KubeWharf | 大规模K8S集群管理系统
kubernetes官方表示单个kubernetes集群能稳定运行的机器节点规模在5K左右,超出规模之后kubernetes的存储系统、pod调度性能、容器请求路由性能等都会受到影响。另外在大规模集群管理上,也会存在很多其他问题,比如多集群管理、多租户、事件异常追踪等。开源项目KubeWharf就是用来解决管理和使用大规模kubernetes集群面临的各种问题的,接下来和大家分享一下自己对KubeWharf的各个子项目的理解。## 1.kubebrain 当k8s集群规模...
KubeWharf:为什么说 k8s 是新时代的 Linux|社区征文
为了应对云原生浪潮下的大规模集群状态信息存储的可扩展性和性能问题,字节实现并开源了 KubeBrain 这个项目。> KubeBrain 是字节跳动针对 Kubernetes 元信息存储的使用需求,基于分布式 KV 存储引擎设计并实现的取代 etcd 的元信息存储系统,支撑线上超过 20,000 节点的超大规模 Kubernetes 集群的稳定运行。---From 字节跳动云原生工程师薛英才[《 基于分布式 KV 存储引擎的高性能 K8s 元数据存储项目 KubeBrain》](https://mp....
计算引擎在K8S上的实践|社区征文
# 背景由于公司近一年开始朝向在云原生方向开始发展,已经将部分业务应用迁移至Kubernetes上运行,并且形成了一套一站式应用研发全生命周期管理体系,提供了如项目管理、代码托管、CI/CD等功能。因此数据平台也面临着从Hadoop到云原生的探索。我们做了一些尝试:首先是存储,使用OSS等对象存储替代了HDFS。其次就是计算,也是本篇文章将要介绍的,将Spark计算任务从Yarn迁移至K8S上运行。# 最初的尝试spark-thrift-server考虑到我们...
云原生时代,如何从 0 到 1 构建 K8s 容器平台的 LB(Nginx)负载均衡体系|社区征文
[TOC]# 万字解读云原生时代,如何从 0 到 1 构建 K8s 容器平台的 LB(Nginx)负载均衡体系> 万字长文,解读云原生时代下,一个中大型公司,该如何从 0 到 1 构建大规模 Kubernetes 容器平台的 LB(Nginx)负载均衡体系... 不管你怎么升级,服务都还是固定在这些机器上,因此这个时代这样的维护方式,并没有太多问题,大家以往也都维护的挺和谐。在容器化时代,基于 Kubernetes 的容器化平台下,LB 的建设有哪些差异呢?主要分为两大块:* 后...
 特惠活动
特惠活动
 K8s新手问题:如何让minikube运行singularity-cri-优选内容
K8s新手问题:如何让minikube运行singularity-cri-优选内容
 K8s新手问题:如何让minikube运行singularity-cri-相关内容
K8s新手问题:如何让minikube运行singularity-cri-相关内容
容器服务发布 Kubernetes v1.26 版本说明
或容器镜像不包含调试工具而导致 kubectl exec 无用时,在现有 Pod 中运行临时容器。详情请参见 临时容器特性。 cgroups v2 进入 Stable 阶段,该特性用来约束分配给进程的资源。详情请参见 cgroups v2文档。 在 Kubernetes v1.25,进一步优化 Kubernetes 对 Windows 系统的支持。 在 Kubernetes v1.25,容器镜像仓库k8s.gcr.io迁移到registry.k8s.io。详情请参见 k8s.gcr.io Redirect to registry.k8s.io。 在 Kubernetes v1.25,网络...
Kubernetes 安全权限管理深度剖析|社区征文
Kubernetes 自身并没有用户管理能力,无法像操作Pod一样,通过API的方式创建/删除一个用户实例,也无法在etcd中找到用户对应的存储对象。在Kubernetes 的访问控制流程中,用户模型是通过请求方的访问控制凭证产生的。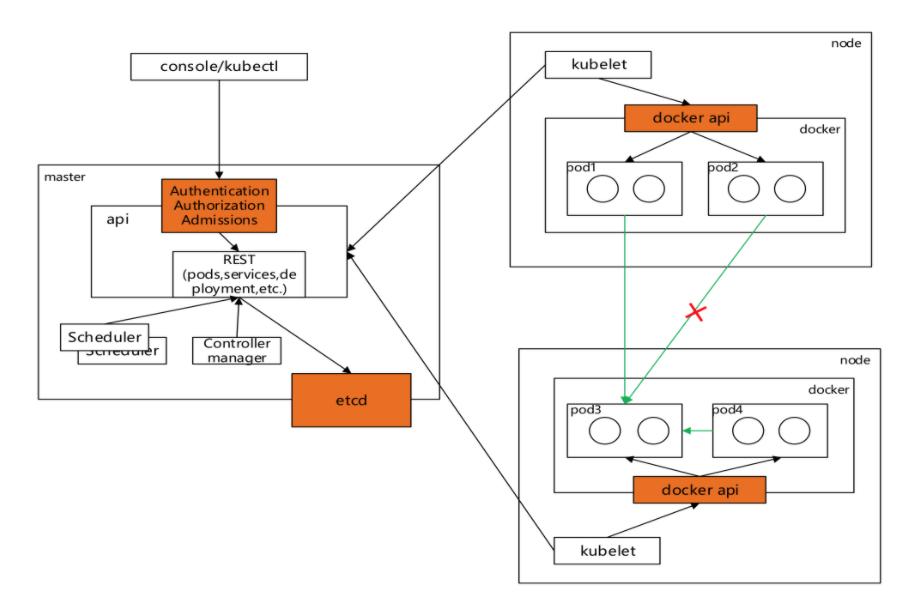上图是k8s的安全全景图,安全控制机制包括两部分:部署态的安全控制和运行态的安全控...
字节跳动大规模K8s集群管理实践
5月31日,CSDN云原生系列在线峰会第6期“K8s大规模应用和深度实践峰会”正式举办,火山引擎资深云原生架构师李玉光在活动中为广大观众解析了《字节跳动大规模K8s集群管理实践》。本文基于演讲内容整理。 字节跳动云原... 为应对大规模集群问题,第一代的集群联邦解决方案实施。从 SRE 的视角来看,平台集成了各种 PaaS 能力,包括数据、运维、监控等能力,构建了统一的部署监控、报警治理一体化的工具矩阵;“推广搜”的物理机服务与在线微...
解决k8s调度不均衡问题
### 前言在近期的工作中,我们发现 k8s 集群中有些节点资源使用率很高,有些节点资源使用率很低,我们尝试重新部署应用和驱逐 Pod,发现并不能有效解决负载不均衡问题。在学习了 Kubernetes 调度原理之后,重新调整了 ... 此策略旨在确保该 Service 关联的 Pod 在不同的节点上运行。 它偏向把 Pod 调度到没有该服务的节点。 整体来看,Service 对于单个节点故障变得更具弹性; || InterPodAffinityPriority | 是 | 1 | 实现了 Pod 间亲和...
Katalyst Memory Advisor:用户态的 K8s 内存管理方案
导致可以出让给离线作业使用的内存量较少,无法实现有效的超卖。针对上述问题,字节跳动将其在大规模在离线混部过程中积累的**精细化**的内存管理经验,总结成了一套**用户态**的 Kubernetes 内存管理方案 Memory A... /oom_score_adj`,从而影响其被 OOM Kill 的顺序:- 对于 Critical Pod 或 Guaranteed Pod 中的容器,将其 `oom_score_adj` 设置为 -997- 对于 BestEffort Pod 中的容器,将其 `oom_score_adj` 设置为 1000-...
《k8s 云原生业务的容器故障排查与思考|社区征文》
跟大家一起探讨如何优化系统的性能、扩展性和容错能力,为读者提供参考和借鉴,以确保系统的高效运行和可靠交付。## 2、业务异常与排障思路用户反馈出现了一个异常任务,它长时间出于“进行中”的状态;用户上传的... 结合云原生组件 kubeproxy 反向代理机制,两者结合引发所导致。下面具体列出分析思路和大致流程,一起讨论下。## 3、故障排查定位### 3.1 业务流程梳理#### 3.1.1 任务流程图