ucos消息队列实验
 社区干货
社区干货
字节跳动基于数据湖技术的近实时场景实践
实验性质比较强,需要在底层加工的时候进行跨数据域的关联。不嵌入到具体的产品功能或者业务流程中,所以对延迟和质量 SLA 的容忍度较高。 - 面向运维型的需求,主要用户是数据研发人员和数据运维人员。这类场景需要... 需要将消息队列和存储组件中的的数据落盘,以往的方式是:离线小时表的形式同步到Hive中,又或者是落盘到成本较高的OLAP数据库中。但是当前,可以通过将中间结果近实时增量同步至数据湖,在湖中支持多种类型的分析监控,...
基于国产化环境的金融级业务系统性能优化实践|社区征文
建议进行多轮测试验证后敲定一套JVM内存使用参数,可以达到更好的效果。最后要选择合理的GC算法,合理的GC算法可以有效提升CPU和内存的操作效率,从而提升Java应用的性能。合理的JVM参数需要经过多轮的验证测试,逐个实验,从而达到最佳效率。- 优化参数```js-XX:CMSInitiatingPermOccupancyFraction:当永久区占用率达到这一百分比时,启动CMS回收-XX:CMSInitiatingOccupancyFraction:设置CMS收集器在老年代空间被使用多少后触发...
干货|从数据治理看,如何打赢“双11”的数字化战争
整个队列的资源就会极度紧张。 ****************************●**************************** **任务管理工作量大。**在几个万个任务的时候,需要匹配优先级,整个的管理工作量非常大。 ... hbo调优策略借鉴算法A/B实验,更好地评估调优策略效果。 、Gang 调度、堆叠调度等。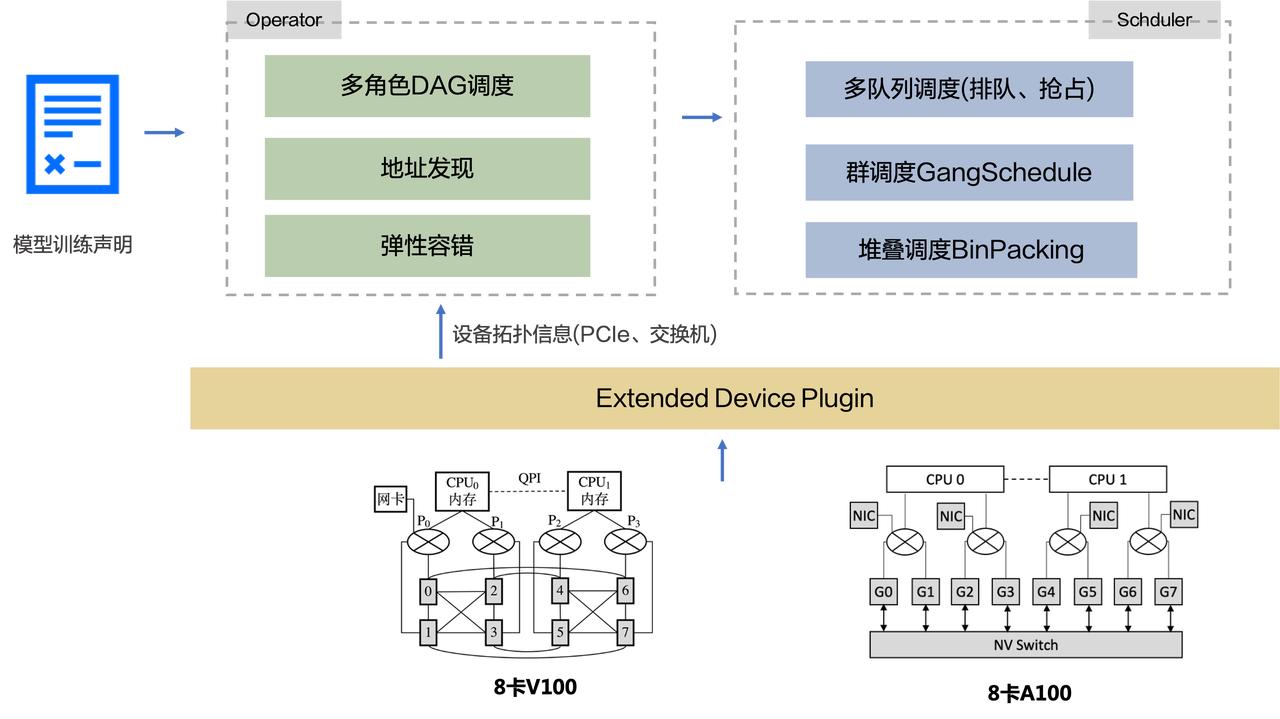#### 云原生存储...
 特惠活动
特惠活动
 ucos消息队列实验-优选内容
ucos消息队列实验-优选内容
 ucos消息队列实验-相关内容
ucos消息队列实验-相关内容
云启万物:如何基于云原生打造云上增长新动力
云原生消息队列等等,开始在为各类技术做着冠名。 对应地火山引擎也推出了面向算力、应用和场景的全栈云原生产品解决方案。在面向算力层,通过VKE、弹性容器可以帮助企业实现更加高效和低成本的资源调度机制;在面向应... 很多研究方式在发生转变:比如从实验研究到数据研究,从假设驱动的研究转向数据驱动的研究,从小样本研究到准全量的大数据研究。新理论的产生,需要数据密集型科研能力的建立和技术支撑。 那么,数据密集型生物科学,之所...
使用Logstash消费Kafka中的数据并写入到云搜索
前言 Kafka 是一个分布式、支持分区的(partition)、多副本的(replica) 分布式消息系统, 深受开发人员的青睐。 云搜索服务是火山引擎提供的完全托管的在线分布式搜索服务,兼容 Elasticsearch、Kibana 等软件及常用开源插件,为您提供结构化、非结构化文本的多条件检索、统计、报表 在本教程中,您将学习如何使用 Logstash 消费 Kafka 中的数据,并写入到云搜索服务中。 关于实验 预计部署时间:20分钟级别:初级相关产品:消息队列 - Ka...
火山引擎大规模机器学习平台架构设计与应用实践
如何先复现实验结果?团队不同的人做了不同的实验,如何对这些实验进行对比?这些都是有挑战的事情。这些管理问题其实也是机器学习模型训练过程中比较大的痛点。本文将针对这些痛点,介绍我们如何进行机器学习平台的... 包括多队列调度(排队、抢占)、Gang 调度、堆叠调度等。#### 云原生存储...
2022年11月
实验创建,拆包,下载,复制移入「更多」中,便于统一管理 增加批量操作:勾选分群包后,可以进行批量删除、批量授权、批量分组等操作,提升效率 新增 上传分群新增ID类型转换功能,便于用户进行转换使用 优化 ... 注意:需注册完成火山Kafka消息队列 新增 系统支持将微信公众号中的数据接入CDP中使用,包括订阅公众号的用户明细数据、用户统计数据、图文统计数据,进一步丰富CDP系统内的数据,便于后续标签构建与人群圈选等应用...
字节跳动 EB 级 Iceberg 数据湖的机器学习应用与优化
我们可以在相对较短的时间内完成训练过程并进行 A/B 测试验证。另外,**特征工程** **越来越自动化、** **端到端** **化**。在传统的机器学习中,特征工程是非常重要的一环,通常需要大量的人工、时间和精力来处理数... 数据湖和消息队列、流式计算可以相互连接,可以通过计算框架提供统一的历史批式、追新流式的管理和接口,同时服务于低延迟的在线流式训练、高吞吐的离线批式训练;并且将消息队列闲置的计算资源用来满足数据湖的数据管...
从 ClickHouse 到 ByteHouse:实时数据分析场景下的优化实践
在字节跳动内部“A/B 实验”应用非常广泛,特别是在验证推荐算法和功能优化的效果方面。最初,公司内部专门的 A/B 实验平台已经提供了 T+1 的离线实验指标,而推荐系统需要更快地观察算法模型、或者某个功能的上线效果... 第三步把构建好的 Part 放入到一个异步索引构建队列中,由后台线程构建索引文件。**效果**:在改成异步后,整体的写入吞吐量大概能提升 20%。**问题二:Kafka 消费能力不足****挑战**:社区版本的 Kafka 表,内部...
20000字详解大厂实时数仓建设 | 社区征文
该层的数据除了存储在消息队列 Kafka 中,通常也会把数据实时写入 Druid 数据库中,供查询明细数据和作为简单汇总数据的加工数据源。命名规范:DWD 层的表命名使用英文小写字母,单词之间用下划线分开,总长度不能超过... 通过实验,最终我们选用了大小几十万的 Batch。第二个问题是,随着数据量的增长,单 QQ 看点的视频内容每天可能写入百亿级的数据,默认方案是写一张分布式表,这就会造成单台机器出现磁盘的瓶颈,尤其是 Clickhouse 底...
Kafka数据同步
实验中的Source Kafka版本为2.12,基于本地机器搭建。现实生产环境会更加复杂,如果您有迁移类的需求,欢迎咨询[技术支持服务](https://console.volcengine.com/ticket/createTicketV2/)。# 关于实验 [#](https://vsop-online.bytedance.net/doc/manage/detail/6627/detail/?DocumentID=173809#%E5%85%B3%E4%BA%8E%E5%AE%9E%E9%AA%8C)* 预计部署时间:40分钟* 级别:高级* 相关产品:消息队列Kafka* 受众: 通用## 环境说明 ...
PHP SDK
实验Meta信息管理接口,可根据业务需要传入自定义实现类,SDK提供默认实现// 第4个缺省值,进组曝光事件上报接口,可根据业务需要传入自定义实现类,SDK提供默认实现// 第5个缺省值,进组信息持久化接口,可根据业务需要传... 避免实时上报基于kafka等消息队列,在实例化AbClient对象时传入EventDispatcherInterface的实现类 php // 基于kafka实现的KafkaEventDispatcher$client = new AbClient("token", null, null, new KafkaEventDispatc...
