ucos消息队列深度
 社区干货
社区干货
年终学习大礼包|云原生大数据知识地图
火山引擎云原生计算资深产品专家迟慧在会上进行了深度讲解。公众号后台回复“知识地图”获取高清版 特惠活动
特惠活动
 ucos消息队列深度-优选内容
ucos消息队列深度-优选内容
 ucos消息队列深度-相关内容
ucos消息队列深度-相关内容
打造新一代云原生"消息、事件、流"统一消息引擎的融合处理平台 | 社区征文
RocketMQ与其他消息中间件的一大区别就在于,它采用的是经过实践检验的云原生架构。接下来,我们要探讨RocketMQ在云原生架构领域的关键技术进步。## RocketMQ的云原生发展历程随着消息队列行业的发展,Apache Roc... 我们将对RocketMQ5.0版本在技术层面的更新进行评估和深度探讨。我们将按照以下几个主题进行讨论和解析。、循环神经网络(RNN)、长长短期记忆网络(LSTM)等模型,实现对用户行为和商品属性之间关系的建模,并进行训练和测试。- 数据服务:通过 Kafka、Flume 等消息队列系统,将推荐结果以及其他相关信息以实时或批量形式发布到不同层级和粒度的服务中心,并提供统一且灵活的 API 接口给前端应用。- 数据应用:通过 Echarts、D3.js 等可视化库,将推荐结果以及其他相关信息以图表或地图等...
直播预告|数据湖实时化与智能化实践探索
> 2022年12月18日 9:00-12:50,由火山引擎云原生计算技术负责人李亚坤出品的 DataFunCon 2022 大会「实时与智能数据湖」专场将围绕数据湖技术的实时化与智能化展开深度分享。专场全程直播,欢迎准时收看! 近年... **讲师:张亿皓-小红书数据平台部消息队列负责人****时间**:12月18日 10:35-11:20**议题简介:**1. Lambda 架构与实时数仓开发痛点2. 流批统一存储架构介绍3. 流批统一存储应用实践**听众收益:**1. 为...
火山引擎 DataLeap 计算治理自动化解决方案实践和思考
字节跳动数据平台目前使用了 1 万多个任务执行队列,支持 DTS、HSQL、Spark、Python、Flink、Shell 等 50 多种类型的任务。自动计算治理框架目前已经完成了离线任务的接入,包括 HSQL、Hive to X 的 DTS 任务、AB ... 已完成优化的 TOP20 队列普遍提升了 20%,CPU 使用率普遍达到了 70%-80%,整体运行时长也有提升。另外还有一些激进策略、深度优化和成本优化策略,可以帮助大部分业务在资源利用率和运行效率之间寻求平衡。 4...
一文带你读懂:云原生时代业务监控|社区征文
例如:队列的当前深度可以被定义为一个计量单元,在写入或读取时被更新统计;输入 HTTP 请求的数量可以被定义为一个计数器,用于简单累加;请求的执行时间可以被定义为一个柱状图,在指定时间片上更新和统计汇总。**(2)Logging**:特点是描述一些离散的(不连续的)事件。例如:应用通过一个滚动的文件输出 debug 或 error 信息,并通过日志收集系统,存储到 Elasticsearch 中;审批明细信息通过 Kafka,存储到数据库(BigTable)中;又或者,特...
干货|字节跳动在湖仓一体领域的最佳实践
底下有基于 Hudi 深度去优化的一个批流一体存储引擎,支持事务及数据实时更新。同时实现了让一份数据在多种多个引擎、多种查询模式下去进行同时分析, 在这种场景下,Presto 的引擎也做了极致的优化,性能是在开源的 3... 消息处理的峰值达到了 90 亿 QPS。这个 QPS 在 LAS 之上,也支持了 Flink SQL 和 Flink Jar 这两种作业类型。并且版本层面我们支持了一个开源最新的 1. 16 的版本,以及经过深度优化打磨过后的1. 11 的版本,基本上能...
字节跳动流式数仓和实时服务分析的思考与实践
依赖于流式的其他消息队列组件的 Log Queue - 基于列存的分布式文件系统两部分结合可以支持流读(Streaming Reading)、批读(Batch Reading)以及 Lookup Join。### 3. **流批一体** Flink 有支持流批一体... 同时也避免业务深度介入运维管理。同时,云原生基于存算分离,弹性很高,能够满足高效的横向扩展。像头条和抖音等产品,在晚上到睡觉之前,用户的使用需求很高,这个时候对实时计算性能要求也非常高,用户睡觉后,使用需...
火山引擎大规模机器学习平台架构设计与应用实践
包括多队列调度(排队、抢占)、Gang 调度、堆叠调度等。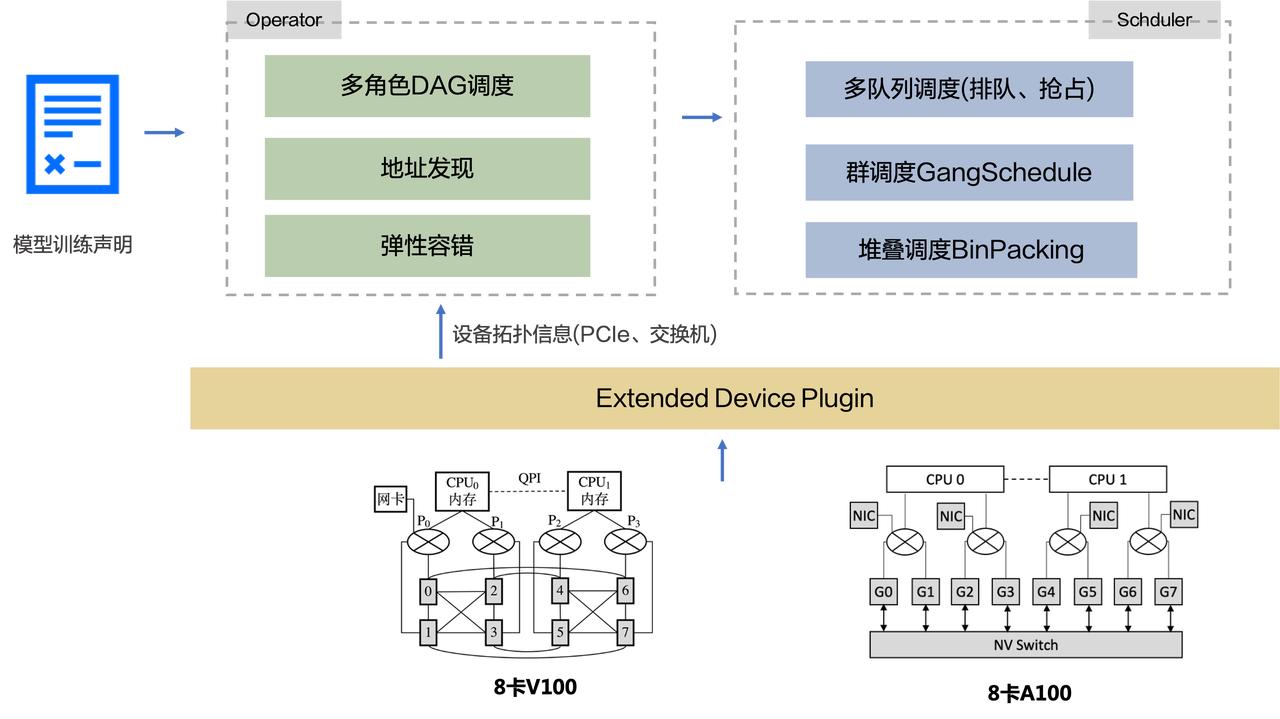#### 云原生存储... Q:对于用在搜索广告推荐领域的大规模稀疏模型,AML 平台上有一些深度的针对性优化吗? A:我们内部的搜广推场景,底层的通信、机器等硬件层面和 CV、语音、NLP 是差不多的方案,谈不上要针对性的优化。如果要针对性的优...
超复杂调用网下的服务治理新思路
就成了团队需要深度探讨的问题。**三是容灾复杂度增大**。在复杂的调用关系下,每个 API 会依赖大量的微服务,而每一个微服务都有一定概率产生故障。我们需要区分强依赖和弱依赖,并辅以特定的降级策略,才能够在不... 微服务基础依赖以及数据库或是消息队列等。字节跳动之所以可以快速孵化新产品,业务层和中台层的建设是一个重要原因。比如新做一个教育应用,我们可以直接调用成熟的账号系统、支付系统、直播模块等,也可以通过向...
