kafka的scala版本
 社区干货
社区干货
聊聊 Kafka:Topic 创建流程与源码分析 | 社区征文
假如你配置的是 localhost:2181/kafka 带命名空间的这种,则不要漏掉了。### 2.2 Kafka 版本 >= 2.2 支持下面的方式(推荐)```./bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --partition... .asScala .map(name => name -> topic.configsToAdd.getProperty(name)) .toMap.asJava newTopic.configs(configsMap) // 调用 adminClient 创建 Topic v...
消息队列选型之 Kafka vs RabbitMQ
Scala 语言开发的一个分布式、多分区、多副本且基于 Zookeeper 协调的分布式消息系统,现已捐献给 Apache 基金会。它是一种高吞吐量的分布式发布订阅消息系统,以可水平扩展和高吞吐率而被广泛使用。目前越来越多的开源分布式处理系统如 Cloudera、Apache Storm、Spark、Flink 等都支持与 Kafka 集成。* **RocketMQ** 是阿里开源的消息中间件,目前已经捐献个 Apache 基金会,它是由 Java 语言开发的,具备高吞吐量、高可用性、适合...
Kafka数据同步
用户只需要通过简单的consumer配置和producer配置,启动MirrorMaker,即可实现实时数据同步。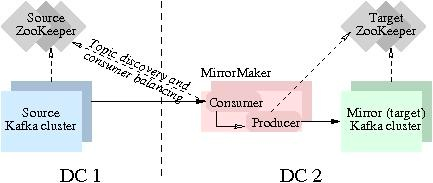本实验主要聚焦跑通Kafka MirrorMaker (MM1)数据迁移流程。实验中的Source Kafka版本为2.12,基于本地机器搭建。现实生产环境会更加复杂,如果您有迁移类的需求,欢迎咨询[技术支持服务](https://console.volcengine.com...
我的大数据学习总结 |社区征文
# 学习的体系在开始学习大数据时,我参考过许多学习路线的建议,但觉得直接照搬别人的学习顺序未必适合自己。最后结合工作需要和个人经历,我制定了一套适合自己的学习路线:开始学习Linux命令和系统基本概念。然后分别学习Java、Python以及Scala这几种在大数据开发中常用的编程语言。然后着重学习Hadoop核心技术如HDFS和MapReduce;接触数据库Hive后,学习数据流技术Kafka和分布式协调服务Zookeeper。深入研究Yarn和求执行引擎Spark...
 特惠活动
特惠活动
 kafka的scala版本-优选内容
kafka的scala版本-优选内容
 kafka的scala版本-相关内容
kafka的scala版本-相关内容
通过 Kafka 协议消费日志
可以将日志主题作为 Kafka 的 Topic 进行消费,每条日志对应一条 Kafka 消息。在实际的业务场景中,通过开源 Kafka SDK 成功对接日志服务后,可以使用 Kafka Consumer 将采集到指定日志主题的日志数据消费到下游的大数据组件或者数据仓库,适用于流式计算或大数据存储场景。通过 Kafka 协议消费日志时,支持消费者或消费组形式消费;不支持跨日志项目进行消费。 限制说明Kafka 协议消费功能支持的 Kafka Client 版本为 0.11.x~2.0.x。 ...
使用前必读
消息队列 Kafka版是一款火山引擎提供的消息中间件服务。Kafka 基于高可用分布式集群技术,提供了高可靠、可扩展、灵活路由的托管消息队列,泛应用于秒杀、流控、系统解耦等场景。 调用说明消息队列 Kafka版提供了全新版本 V2 OpenAPI,您可以通过发送 HTTPS 请求调用消息队列 Kafka版的 V2 API。调用 V2 API 时,您需要向火山引擎消息队列 Kafka版 API 的服务端地址发送 HTTPS 请求,并参考各个业务接口文档,在 HTTPS 请求中填入正确的...
从 Kafka 导入数据
日志服务导入功能支持导入火山引擎消息队列 Kafka 集群和自建 Kafka 集群的数据。创建导入任务后,您可以通过日志服务控制台或服务日志查看导入任务详情。此外,日志服务还会为导入的日志数据添加以下元数据字段。 字段 说明 __content__ Kafka 消息。 __path__ 字段值为空。 __source__ Kafka 集群的服务地址。 注意事项从 Kafka 导入数据功能的限制项如下: 限制 说明 Kafka 版本 Kafka 版本需为 0.11.x 以上。 并发...
Kafka/BMQ
Kafka 连接器提供从 Kafka Topic 或 BMQ Topic 中消费和写入数据的能力,支持做数据源表和结果表。您可以创建 source 流从 Kafka Topic 中获取数据,作为作业的输入数据;也可以通过 Kafka 结果表将作业输出数据写入到 Kafka Topic 中。 注意事项使用 Flink SQL 的用户需要注意,不再支持 kafka-0.10 和 kafka-0.11 两个版本的连接器,请直接使用 kafka 连接器访问 Kafka 0.10 和 0.11 集群。Kafka-0.10 和 Kafka-0.11 两个版本的连接...
Kafka
1. 概述 Kafka Topic 数据能够支持产品实时数据分析场景,本篇将介绍如何进行 Kafka 数据模型配置。 温馨提示:Kafka 数据源仅支持私有化部署模式使用,如您使用的SaaS版本,若想要使用 Kafka 数据源,可与贵公司的客户成功经理沟通,提出需求。 2. 快速入门 下面介绍两种方式创建数据连接。 2.1 从数据连接新建(1)在数据准备模块中选择数据连接,点击新建数据连接。(2)点击 Kafka 进行连接。(3)填写连接的基本信息,点击测试连接,显示连...
限制说明
消息队列 Kafka版对一些指标和性能进行了限制,请您在使用过程中注意不要超过相应的限制值,避免出现异常。 限制类型 限额 说明 实例数量 8 个 单个地域(Region)内的消息队列 Kafka版实例数。您也可以通过配额中... 消息队列 Kafka版不暴露 ZooKeeper。 登录部署消息队列 Kafka版的机器 不支持 无 变更实例的地域 不支持 无 Kafka 版本 2.2.2 2.8.2 目前仅支持 Kafka 2.2.2 和 2.8.2 版本。 连接数 20000 每个 Kafka...
使用 Kafka 协议上传日志
限制说明支持的 Kafka 协议版本为 0.11.x~2.0.x。 支持压缩方式包括 gzip、snappy 和 lz4。 为保证日志传输的安全性,必须使用 SASL_SSL 连接协议。对应的用户名为日志服务项目 ID,密码为火山引擎账号密钥,详细信息请参考示例。 如果日志主题中有多个 Shard,日志服务不保证数据的有序性,建议使用负载均衡模式上传日志。 当使用 Kafka Producer Batch 打包发送数据的时候,一次 Batch 数据的大小不能超过 5MiB,一条消息的大小上限...
Kafka数据同步
用户只需要通过简单的consumer配置和producer配置,启动MirrorMaker,即可实现实时数据同步。本实验主要聚焦跑通Kafka MirrorMaker (MM1)数据迁移流程。实验中的Source Kafka版本为2.12,基于本地机器搭建。现实生产环境会更加复杂,如果您有迁移类的需求,欢迎咨询[技术支持服务](https://console.volcengine.com...
通过 Kafka 消费火山引擎 Proto 格式的订阅数据
数据库传输服务 DTS 的数据订阅服务支持使用 Kafka 客户端消费火山引擎 Proto 格式的订阅数据。本文以订阅云数据库 MySQL 版实例为例,介绍如何使用 Go、Java 和 Python 语言消费 Canal 格式的数据。 前提条件已注册火山引擎账号并完成实名认证。账号的创建方法和实名认证,请参见如何进行账号注册和实名认证。 已安装 protoc,建议使用 protoc 3.18 或以上版本。 说明 您可以执行 protoc -version 查看 protoc 版本。 用于订阅消...
