kafka是基于什么的系统
 社区干货
社区干货
Kafka 消息传递详细研究及代码实现|社区征文
## 背景新项目涉及大数据方面。之前接触微服务较多,趁公司没反应过来,赶紧查漏补缺。Kafka 是其中之一。Apache Kafka 是一个开源的分布式事件流平台,可跨多台计算机读取、写入、存储和处理事件,并有发布和订阅事... 整个查询过程基于二分法,顺序为: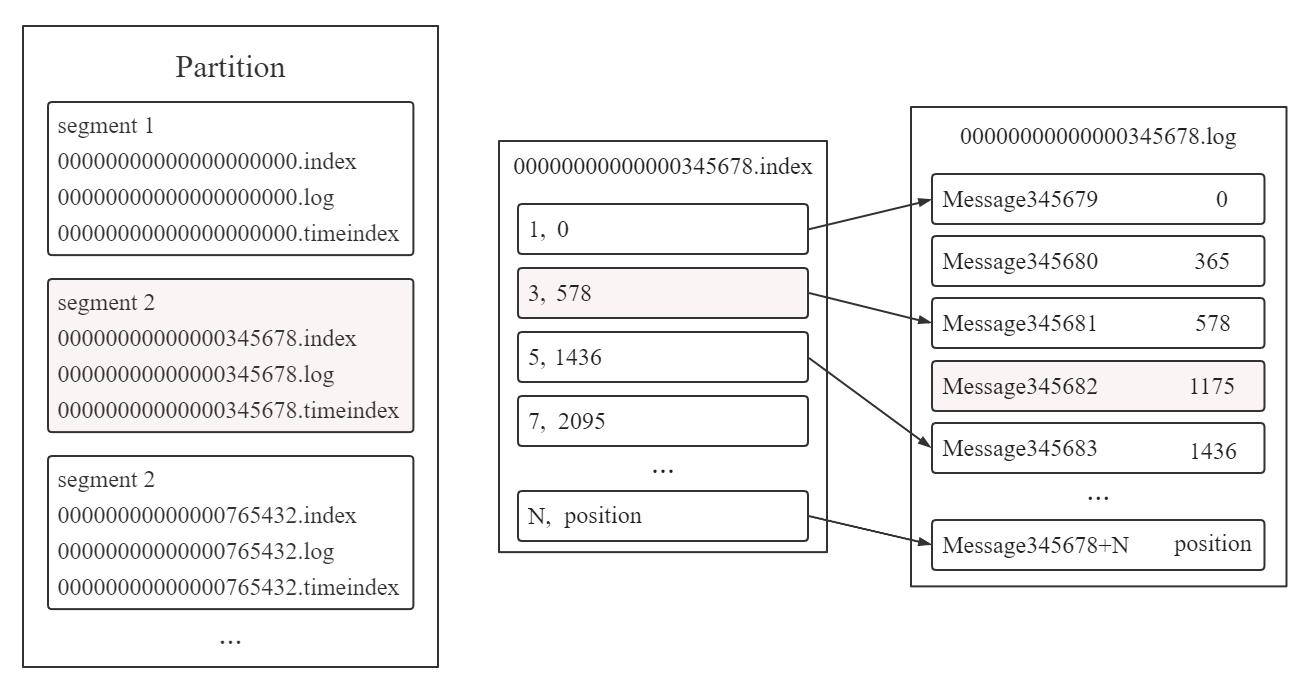(1) 利用二分法找到小于 345682 且离其最近的...
字节跳动基于Apache Atlas的近实时消息同步能力优化 | 社区征文
文 | **洪剑**、**大滨** 来自字节跳动数据平台开发套件团队# 背景## 动机字节数据中台DataLeap的Data Catalog系统基于Apache Atlas搭建,其中Atlas通过Kafka获取外部系统的元数据变更消息。在开源版本中,每台服务器支持的Kafka Consumer数量有限,在每日百万级消息体量下,经常有长延时等问题,影响用户体验。在2020年底,我们针对Atlas的消息消费部分做了重构,将消息的消费和处理从后端服务中剥离出来,并编写了Flink任务承担...
消息队列选型之 Kafka vs RabbitMQ
最初起源于金融系统,用于在分布式系统中存储转发消息。RabbitMQ 发展到今天,被越来越多的人认可,这和它在可靠性、可用性、扩展性、功能丰富等方面的卓越表现是分不开的。* **Kafka** 起初是由 LinkedIn 公司采用 Scala 语言开发的一个分布式、多分区、多副本且基于 Zookeeper 协调的分布式消息系统,现已捐献给 Apache 基金会。它是一种高吞吐量的分布式发布订阅消息系统,以可水平扩展和高吞吐率而被广泛使用。目前越来越多的开...
Kafka数据同步
其实现原理是通过从 Source 集群消费消息,然后将消息生产到 Target 集群从而完成数据迁移操作。用户只需要通过简单的consumer配置和producer配置,启动MirrorMaker,即可实现实时数据同步。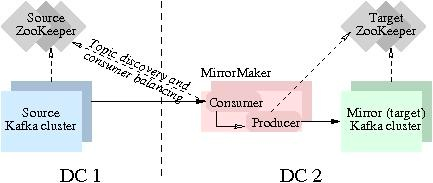本实验主要聚焦跑通Kafka MirrorMaker (MM1)数据迁移流程。实验中的Source Kafka版本为2.12,基于本地机器搭建。现实生产...
 特惠活动
特惠活动
 kafka是基于什么的系统-优选内容
kafka是基于什么的系统-优选内容
 kafka是基于什么的系统-相关内容
kafka是基于什么的系统-相关内容
使用Logstash消费Kafka中的数据并写入到云搜索
前言 Kafka 是一个分布式、支持分区的(partition)、多副本的(replica) 分布式消息系统, 深受开发人员的青睐。 云搜索服务是火山引擎提供的完全托管的在线分布式搜索服务,兼容 Elasticsearch、Kibana 等软件及常用开源插件,为您提供结构化、非结构化文本的多条件检索、统计、报表 在本教程中,您将学习如何使用 Logstash 消费 Kafka 中的数据,并写入到云搜索服务中。 关于实验 预计部署时间:20分钟级别:初级相关产品:消息队列 - Ka...
字节跳动基于Apache Atlas的近实时消息同步能力优化 | 社区征文
文 | **洪剑**、**大滨** 来自字节跳动数据平台开发套件团队# 背景## 动机字节数据中台DataLeap的Data Catalog系统基于Apache Atlas搭建,其中Atlas通过Kafka获取外部系统的元数据变更消息。在开源版本中,每台服务器支持的Kafka Consumer数量有限,在每日百万级消息体量下,经常有长延时等问题,影响用户体验。在2020年底,我们针对Atlas的消息消费部分做了重构,将消息的消费和处理从后端服务中剥离出来,并编写了Flink任务承担...
使用 Kafka 协议上传日志
日志服务支持通过 Kafka 协议上传和消费日志数据,基于 Kafka 数据管道提供完整的数据上下行服务。使用 Kafka 协议上传日志功能,无需手动开启功能,无需在数据源侧安装数据采集工具,基于简单的配置即可实现 Kafka Pr... (logstash_output_kafka),可以通过 Kafka 协议采集数据。在通过 ELK 搭建日志采集分析系统的场景下,只需修改 Logstash 配置文件,实现通过 Kafka 协议上传日志数据到日志服务。通过日志服务控制台自动生成 Logstash...
消息队列选型之 Kafka vs RabbitMQ
最初起源于金融系统,用于在分布式系统中存储转发消息。RabbitMQ 发展到今天,被越来越多的人认可,这和它在可靠性、可用性、扩展性、功能丰富等方面的卓越表现是分不开的。* **Kafka** 起初是由 LinkedIn 公司采用 Scala 语言开发的一个分布式、多分区、多副本且基于 Zookeeper 协调的分布式消息系统,现已捐献给 Apache 基金会。它是一种高吞吐量的分布式发布订阅消息系统,以可水平扩展和高吞吐率而被广泛使用。目前越来越多的开...
Kafka数据同步
其实现原理是通过从 Source 集群消费消息,然后将消息生产到 Target 集群从而完成数据迁移操作。用户只需要通过简单的consumer配置和producer配置,启动MirrorMaker,即可实现实时数据同步。本实验主要聚焦跑通Kafka MirrorMaker (MM1)数据迁移流程。实验中的Source Kafka版本为2.12,基于本地机器搭建。现实生产...
Kafka消息订阅及推送
1. 功能概述 VeCDP产品提供强大的开放能力,支持通过内置Kafka对外输出的VeCDP系统内的数据资产。用户可以通过监测Kafka消息,及时了解标签、分群等数据变更,赋能更多企业业务系统。 2. 消息订阅配置说明 topic规范cdp的kafka topic是按集团拆分的,topic格式如下: json cdp_dataAsset_orgId_${org_id}截止到1.21,如果想使用cdp的消息总线消费事件,cdp只会建一个默认的集团topic cdp_dataAsset_orgId_1。如果默认集团id不为1,或者新...
Kafka CPU 消耗场景分析
本文档主要介绍 Kafka 使用过程中可能产生 CPU 大量消耗的场景,并针对各个场景提供客户端使用策略相关的优化建议。 背景信息基于产品定位与产品设计,Kafka 并非计算密集型产品,Kafka 实例的业务数据量主要体现在网络带宽占用与磁盘的吞吐,日常场景下无需关注 CPU 占用率。但是在实际生产环境中,往往存在多样化的使用场景,部分业务模型中 CPU 也会成为服务端的使用瓶颈。目前对于服务端 CPU 消耗比较大的主要场景有请求速率过快、...
聊聊 Kafka:Topic 创建流程与源码分析 | 社区征文
## 一、Topic 介绍Topic(主题)类似于文件系统中的文件夹,事件就是该文件夹中的文件。Kafka 中的主题总是多生产者和多订阅者:一个主题可以有零个、一个或多个向其写入事件的生产者,以及零个、一个或多个订阅这些事件的消费者。可以根据需要随时读取主题中的事件——与传统消息传递系统不同,事件在消费后不会被删除。相反,您可以通过每个主题的配置设置来定义 Kafka 应该保留您的事件多长时间,之后旧事件将被丢弃。Kafka 的性能在...
Kafka 消费者最佳实践
本文档以 Confluent 官方 Java 版本客户端 SDK 为例,介绍使用火山引擎 Kafka 实例时的消费者最佳实践。 广播与单播在同一个消费组内部,每个消息都预期仅仅只被消费组内的某个消费者消费一次,因而使用同一个消费组的... 消费者的所有请求发送和响应几乎都基于消费者poll方法的调用。若客户端使用订阅(Subscribe)的方式进行消费,那么在使用过程中,需要保证poll方法在固定的周期内进行调用,最长不能超过max.poll.interval.ms的配置,默认...
