S3和CloudFront托管的静态网站,每次页面重新加载都会导致403错误。
 社区干货
社区干货
Apache Pulsar 在火山引擎 EMR 的集成与场景
但是这个意义上的托管并不是“全托管”,而是“半托管”——用户有足够的自主性、灵活性,可以登录到自己集群的节点的命令行环境中,执行灵活的运维操作,如脚本执行、软件安装与部署等,以满足用户的个性化需求。也就是... CloudFS、表格式等)、数据调度引擎(如 YARN 等)、各种面向不同场景的大数据计算、存储组件以及贯穿整个 EMR 服务端到端的管控面。EMR 向上可以对接火山引擎的大数据研发治理套件 DataLeap,支持用户构建数据仓库,赋...
基于 Flink 构建实时数据湖的实践
***云原生大数据特惠专场:https://www.volcengine.com/activity/cloudnative***实时数据湖是现代数据架构的核心组成部分,随着数据湖技术的发展,用户对其也有了更高的需求:需要从多种数据源中导入数据、数据湖与数... 底层使用 K8s 作为容器编排和管理平台。存储层支持 HDFS 或 S3。由于 Iceberg 良好的文件组织架构和生态,所以选择了 Iceberg 作为 Table Format。计算层则使用 Flink 进行出入湖,其中 Flink SQL 是最常用的出入湖方...
火山引擎云搜索服务升级云原生新架构;提供数十亿级分布式向量数据库能力
搜索技术就绽放出了惊人的社会和经济价值。随着信息社会快速发展,数据呈爆炸式增长,搜索技术通过数据收集与处理,满足信息共享与快速检索的需求。 云搜索服务 ESCloud 是火山引擎提供的**完全托管在线分布式... 因此对每个推送的内容都会进行相似度识别并消重。每个文案通过 BERT 模型生成 Embedding,在云搜索中检索一次。如果相似度低于阈值,判定为新的文案,会写入 k-NN 向量数据库中,逐渐完善成一个文案库;如果相似度高于阈...
火山引擎上云迁移指南(二):迁移实施
云主机数据涉及两部分:系统镜像盘和数据盘的迁移。此外,火山引擎即将上线服务器迁移工具,帮助您快速完成服务器的迁移,敬请期待。#### 迁移系统镜像盘 - **系统镜像重新部署**:各云厂商的cloudinit的脚本不同,... (https://portal.volccdn.com/obj/volcfe/cloud-universal-doc/upload_ef7567c27b7b823b4ec32c12faa8d7a2.png)具体步骤如下:1. 准备工作 提前在火山引擎控制台中创建创建托管版集群。详细说明请参考[创建集...
 特惠活动
特惠活动
 S3和CloudFront托管的静态网站,每次页面重新加载都会导致403错误。-优选内容
S3和CloudFront托管的静态网站,每次页面重新加载都会导致403错误。-优选内容
 S3和CloudFront托管的静态网站,每次页面重新加载都会导致403错误。-相关内容
S3和CloudFront托管的静态网站,每次页面重新加载都会导致403错误。-相关内容
基于火山引擎 EMR 构建企业级数据湖仓
导致了他们在演化过程中变得越来越相似。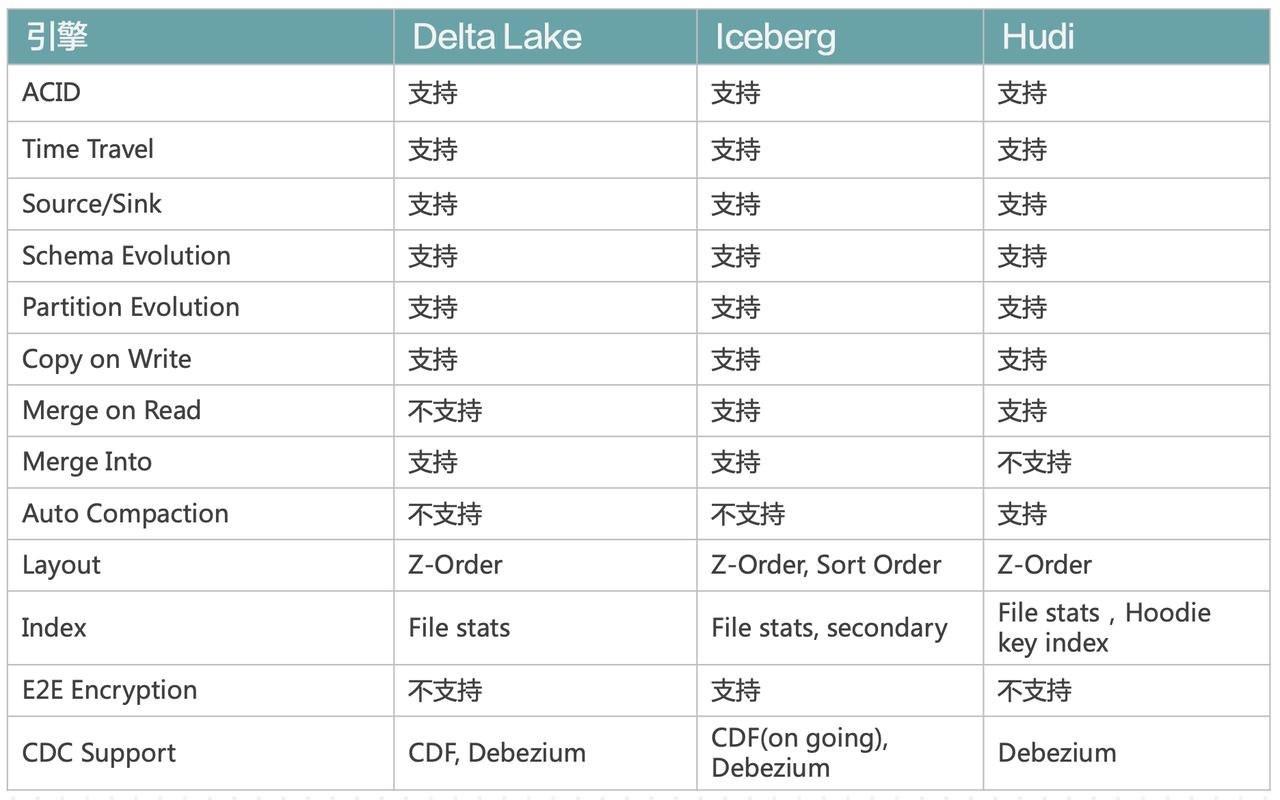可以看到,绝大部分特性这三者都是支持... CloudFS 上。我们在引擎内部内置一些本地缓存,用于缓存热数据。分层缓存能够弥补企业上云之后,数据因保存在对象存储所造成的性能损失。另外 Cloud FS 提供 HDFS 的语义,可便于开源组件切入。#### 云托管,易运维...
Apache Pulsar 在火山引擎 EMR 的集成与场景
但是这个意义上的托管并不是“全托管”,而是“半托管”——用户有足够的自主性、灵活性,可以登录到自己集群的节点的命令行环境中,执行灵活的运维操作,如脚本执行、软件安装与部署等,以满足用户的个性化需求。也就是... CloudFS、表格式等)、数据调度引擎(如 YARN 等)、各种面向不同场景的大数据计算、存储组件以及贯穿整个 EMR 服务端到端的管控面。EMR 向上可以对接火山引擎的大数据研发治理套件 DataLeap,支持用户构建数据仓库,赋...
火山引擎分布式云原生平台 DCP 正式公测!
分布式云原生平台(Distributed Cloud Native Platform,DCP)是一款企业级云原生统一管理平台,覆盖多云多 Kubernetes 集群管理、容灾、迁移等场景。无论用户的应用构建在何种云上,DCP 都能实现 K8s 的统一管理与运维... 支持基于动态/静态集群权重的副本分发- 支持应用已调度集群中副本故障时重调度**统一服务管理**- 应用分发:Kubernetes 原生及 CRD 资源通过关联分发策略实现多集群分发,并可与火山引擎[持续交付 CP](...
大象在云端起舞:后 Hadoop 时代的字节跳动云原生计算平台
支撑这些服务的,是字节跳动打磨的一套云原生大数据技术栈,涵盖了从数据接入、数据存储、数据计算到数据服务的所有环节。其中,存储层是基于 HDFS 进行深度定制的 CloudFS + Iceberg,中间件包括 Kafka 和字节自研的 ... Flink Exactly Once 的特性决定了任何一个单机故障都会导致整个 Flink 作业的重启。在大规模模型训练场景下,需要上千个容器的时候,重启时间一次,要重新调度一次上千个容器,然后要去拉上千个容器的镜像,对线上效果的...
字节跳动流式数仓和实时服务分析的思考与实践
导致数据不一致; 3、**Serving** **性能问题**,有些业务的主要场景比较简单,但也需要消耗大量的资源,比如简单的点查,往往要求高 QPS。如果采用传统大数据的方案,把主键拼起来,那么中间的结合是松耦合的,如果要同时达到高 QPS,这种拼接方案在计算上和资源上的投资都会很大,性能问题也很严重。针对上述困境,字节团队选择了**流式数仓实时服务分析融合的解决方案。** # **流式数仓和实时服务分析实践**## **流数仓和服务...
集简云2月新增/更新:新增4大功能,19款应用,更新15款应用,新增120多个动作
更新应用:畅捷通T+Cloud更新应用:船长BI更新应用:送件侠更新应用:腾讯地图更新应用:百度地图更新应用:高德地图 **功能更新**... 官网:https://qrcode.icu/site/#/front**可用触发动作*** 当有新的图片模板产生时 **可用执行动作*** 获取模板内动态参数* 渲染图片 **应用使用示例****老码十途+企业微...
湖仓一体架构在 LAS 服务的探索与实践
就导致整个企业的技术运维成本逐步提升。基于这个问题,随着技术的进一步发展,在 2020 年,湖仓一体的架构开始被提出。相比起传统数据湖,湖仓一体架构支持原生的 ACID 能力,支持像 BI 分析、报表分析,机器学习和... 再往下就是 LAS 基于火山引擎对象存储服务 TOS 和 CloudFS ,来提供 EB 级的数据存储能力和数据访问的缓存加速能力。以上就是 LAS 整体的技术架构。# **LAS数据湖内核剖析**这一版块将向大家呈现 LAS 数据湖内...
后 Hadoop 时代,字节跳动如何打造云原生计算平台
**存储层是基于 HDFS 进行深度定制的 CloudFS + Iceberg,中间件包括 Kafka 和字节自研的 BMQ,计算引擎使用的是 Spark / Flink,还包括资源调度和混部,以及 HSAP 和外围服务** 。这套系统能管控达到几十万台机器,行... Flink Exactly Once 的特性决定了任何一个单机故障都会导致整个 Flink 作业的重启。在大规模模型训练场景下,需要上千个容器的时候,重启时间一次,要重新调度一次上千个容器,然后要去拉上千个容器的镜像,对线上效果的...
火山引擎 Iceberg 数据湖的应用与实践
所以每次对表的变更都会产生一个新版本的 Metadata File。这个 Metadata File 记录了 Schema 分区方式、快照列表等表级别的元数据,所以在这个 Metadata File 存的快照列表里面,每个快照下层对应的 Manifest List 文... 兼容 HDFS 语义的 CloudFS,然后通过 Iceberg 提供的 Merge Read 还有 Upsert 这些语义,再结合平台的服务支持了数据在 Iceberg 上面批流一体的存储。在数据入湖方面,我们支持从客户自建的数据库或 HDFS 中进行批式...
