zsh的typeset -t命令是用来做什么的?
 社区干货
社区干货
云原生环境下的日志采集、存储、分析实践
开源方案一般采用单机 yaml 做采集配置,当节点数很多的时候,配置非常繁琐。- 开源系统的采集配置难以管理,数据源也比较单一。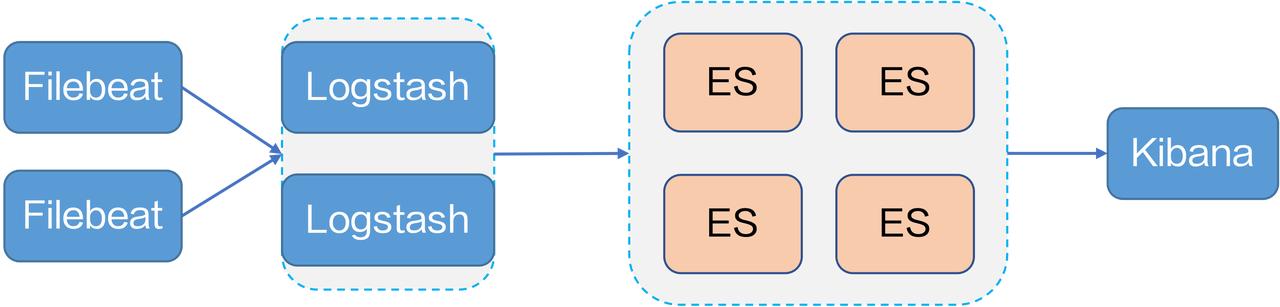### Kubernetes 下的日志采集Kubernetes 下如何采集日志呢? 官方推荐了四种日志采集方案:- DaemonSet:在每台宿主机上搭建一个 DaemonSet 容器来部署 Agent。业务容...
干货| 火山引擎在行为分析场景下的ClickHouse JOIN优化
(https://p3-volc-community-sign.byteimg.com/tos-cn-i-tlddhu82om/09168afb5eee44faaec400468faa7c2d~tplv-tlddhu82om-image.image?=&rk3s=8031ce6d&x-expires=1716049254&x-signature=5VH7757ddApPRvTZsHdzZmDD... JOIN需要基于内存构建hash table且需要存储右表全部的数据,然后再去匹配左表的数据。而IN查询会对右表的全部数据构建hash set,但是不需要匹配左表的数据,且不需要回写数据到block。``` SELECT e...
在字节跳动,一个更好的企业级 SparkSQL Server 这么做
但是相比Hive等引擎来说,由于SparkSQL缺乏一个类似Hive Server2的SQL服务器,导致SparkSQL在易用性上比不上Hive。很多时候,SparkSQL只能将自身SQL作业打包成一个Jar,进行spark-submit命令提交,因而大大降低Spark的... (TGetInfoReq req) throws org.apache.thrift.TException;public TExecuteStatementResp ExecuteStatement(TExecuteStatementReq req) throws org.apache.thrift.TException;public TGetTypeInfoResp GetTypeInf...
云原生环境下的日志采集、存储、分析实践
作者:刘卯银|火山引擎日志系统架构师> 本文整理自火山引擎开发者社区 Meetup 第八期演讲,主要介绍了火山引擎 TLS 日志服务的架构实现、设计优化以及实践案例。谈到日志系统,首先要从日志说起,日志在 IT 系统里... Kubernetes 下如何采集日志呢? 官方推荐了四种日志采集方案:- DaemonSet:在每台宿主机上搭建一个 DaemonSet 容器来部署 Agent。业务容器将容器标准输出存储到宿主机上的文件,Agent 采集对应宿主机上的文件。 -...
 特惠活动
特惠活动
 zsh的typeset -t命令是用来做什么的?-优选内容
zsh的typeset -t命令是用来做什么的?-优选内容
 zsh的typeset -t命令是用来做什么的?-相关内容
zsh的typeset -t命令是用来做什么的?-相关内容
云原生环境下的日志采集、存储、分析实践
开源方案一般采用单机 yaml 做采集配置,当节点数很多的时候,配置非常繁琐。- 开源系统的采集配置难以管理,数据源也比较单一。### Kubernetes 下的日志采集Kubernetes 下如何采集日志呢? 官方推荐了四种日志采集方案:- DaemonSet:在每台宿主机上搭建一个 DaemonSet 容器来部署 Agent。业务容...
干货| 火山引擎在行为分析场景下的ClickHouse JOIN优化
(https://p3-volc-community-sign.byteimg.com/tos-cn-i-tlddhu82om/09168afb5eee44faaec400468faa7c2d~tplv-tlddhu82om-image.image?=&rk3s=8031ce6d&x-expires=1716049254&x-signature=5VH7757ddApPRvTZsHdzZmDD... JOIN需要基于内存构建hash table且需要存储右表全部的数据,然后再去匹配左表的数据。而IN查询会对右表的全部数据构建hash set,但是不需要匹配左表的数据,且不需要回写数据到block。``` SELECT e...
在字节跳动,一个更好的企业级 SparkSQL Server 这么做
但是相比Hive等引擎来说,由于SparkSQL缺乏一个类似Hive Server2的SQL服务器,导致SparkSQL在易用性上比不上Hive。很多时候,SparkSQL只能将自身SQL作业打包成一个Jar,进行spark-submit命令提交,因而大大降低Spark的... (TGetInfoReq req) throws org.apache.thrift.TException;public TExecuteStatementResp ExecuteStatement(TExecuteStatementReq req) throws org.apache.thrift.TException;public TGetTypeInfoResp GetTypeInf...
干货 | 在字节跳动,一个更好的企业级SparkSQL Server这么做
但是相比Hive等引擎来说,由于SparkSQL缺乏一个类似Hive Server2的SQL服务器,导致SparkSQL在易用性上比不上Hive。很多时候,SparkSQL只能将自身SQL作业打包成一个Jar,进行spark-submit命令提交,因而大大降低Spark... 首先需要实现TCLIService.Iface下的所有接口,下面用代码+注释的方式来讲述这些Thrift接口的含义,以及如果实现一个SparkSQL服务器,需要在这些接口做什么内容:``` public class SparkSQLThriftSer...
获取并运行 iOS 示例项目
用于运行示例项目。 操作步骤下载并解压缩示例项目。 【附件下载】: BytedanceHTTPDNS_Demo-develop.zip,大小为 46.48KB 在示例项目的 example 目录运行 pod 命令安装依赖。如果您收到 out-of-date source repo... objectivec [[TTDnsResolver shareInstance] setHttpDnsAuthenticationBlock: ^(void) { TTHttpDnsAuthenticationInfo* info = [[TTHttpDnsAuthenticationInfo alloc] init]; info.httpDnsAccount = @...
安装多云安全终端防护 Agent
exit 1;fi;${GETTER} "http://hids${REGION}.tos-${REGION}.ivolces.com/agent/install_volc_online_18224.sh" bash' Windows 系统说明 请使用命令提示符(管理员)执行安装命令。 Bash set SPECIFIED_CLOUD_PROVI... Start-Process $env:temp\$FILE_NAME -ArgumentList '/S'" 边缘计算资源安装 Agent 如您需要为火山引擎边缘计算资源添加终端防护能力,您可以参考以下步骤执行客户端安装操作。 Linux 系统如果待安装客户端的服务器...
分析一例 mysqldump bug
mysql> select * from processlist;ERROR 1356 (HY000): View 'sys.processlist' references invalid table(s) or column(s) or function(s) or definer/invoker of view lack rights to use them```检查 RDS,发现 RDS 工作正常,并未出现 sys schema 损坏的情况。# 问题复现客户的命令中使用了 --all-databases 参数,备份命令如下:```sqlmysqldump -h 111.62.xx.xx -urudonx -p$password --all-databases --set-gtid-p...
干货 | 在字节跳动,一个更好的企业级SparkSQL Server这么做
但是相比Hive等引擎来说,由于SparkSQL缺乏一个类似Hive Server2的SQL服务器,导致SparkSQL在易用性上比不上Hive。很多时候,SparkSQL只能将自身SQL作业打包成一个Jar,进行spark-submit命令提交,因而大大降低Spark的... (TGetInfoReq req) throws org.apache.thrift.TException;public TExecuteStatementResp ExecuteStatement(TExecuteStatementReq req) throws org.apache.thrift.TException;public TGetTypeInfoResp GetTypeI...
配置 volcengine-cli
SecretKey 和地域(region)信息,因此需要在 volcengine-cli 中进行配置。可通过新建配置和环境变量两种方式进行配置。 新建配置新建配置需要执行以下 configure 命令: shell volcengine-cli configure set --profil... volcengine-cli 补全脚本依赖工具 bash-completiom,因此需要先安装并启用 bash-completion。可以用命令 type _init_completion 检查 bash-completion 是否已安装。 使用以下命令安装 bash-completion: shell yum ...
