Kafka-connect是否必须使用Schemaregistry?
 社区干货
社区干货
「火山引擎」数智平台 VeDI 数据中台产品双月刊 VOL.03
Kafka、ClickHouse、Hudi、Iceberg 等大数据生态组件,100%开源兼容,支持构建实时数据湖、数据仓库、湖仓一体等数据平台架构,帮助用户轻松完成企业大数据平台的建设,降低运维门槛,快速形成大数据分析能力。## **产... 支持用户在 ByteHouse 中灵活定义并使用函数,实现高性能的查询。 - 正式发布物化视图能力,通过定义物化视图实现查询加速,简化查询逻辑。 - 支持 ETL 工具 DBT connector,进一步完善任务调度、上下游对...
数据库顶会 VLDB 2023 论文解读 - Krypton: 字节跳动实时服务分析 SQL 引擎设
数据通过 Kafka 流入不同的系统。对于离线链路,数据通常流入到 Spark/Hive 中进行计算,结果通过 ETL 导入到 HBase/ES/ClickHouse 等系统提供在线的查询服务。对于实时链路, 数据会直接进入到 HBase/ES 提供高并发低... Coordinator 会访问 Meta Server 得到 Schema 和数据的最新版本号,生成分布式执行 Plan 下发给 Data Server,Data Server 负责 Query Plan 的执行。Krypton 的 Query Processor 采用了 MPP 的执行模式。 - 为了...
「火山引擎数据中台产品双月刊」 VOL.06
Kafka、ClickHouse、Hudi、Iceberg 等大数据生态组件,100%开源兼容,支持构建实时数据湖、数据仓库、湖仓一体等数据平台架构,帮助用户轻松完成企业大数据平台的建设,降低运维门槛,快速形成大数据分析能力。## **产... 需要同时具备数据权限及加脱敏权限,才可查看未被脱敏的原始数据。- **【新增血缘查询功能】** - 支持记录 SQL 作业中参与计算的所有表,并在作业管理页面展示。- 【**优化** **JDBC** **连接功能】*...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(中)
意味着用户可以接入任意一个服务节点(当然如果有需要,也可以隔离开),并且可以水平扩展,意味着平台具备支持高并发查询的能力。- **元数据服务**元数据服务(Catalog Service)提供对查询相关元数据信息的读写。Metadata 主要包括 2 部分:Table 的元数据和 Part 的元数据。表的元数据信息主要包括表的 Schema,partitioning schema,primary key,ordering key。Part 的元数据信息记录表所对应的所有 data file 的元数据,主要包括...
 特惠活动
特惠活动
 Kafka-connect是否必须使用Schemaregistry?
-优选内容
Kafka-connect是否必须使用Schemaregistry?
-优选内容
 Kafka-connect是否必须使用Schemaregistry?
-相关内容
Kafka-connect是否必须使用Schemaregistry?
-相关内容
通过 ByteHouse 消费日志
您需要根据日志服务中源日志结构设计新的表结构,建议仅创建需要保存或用于后续分析的列。 单击创建。 新建 Kafka 数据源。在顶部导航栏单击数据加载。 在页面左上角单击数据源。 在数据源页面中,单击 + 连接新源... 此处应固定为 JSON_KAFKA。 选择目标表。 配置 说明 目标数据库 日志服务日志数据在 ByteHouse 中存储的数据库名称。 目标表 日志服务日志数据在 ByteHouse 中存储的表名称。 定义 Schema 映射。 设置日志...
流式导入
当前已经支持的 Kafka 消息格式为: JSON Protobuf 支持的 Kafka/Confluent Cloud 版本:0.10 及以上 必备权限要将 Kafka 数数据迁移到ByteHouse,需要确保 Kafka 和 ByteHouse 之间的访问权限配置正确。需要在Kafka中... 需要身份验证,您可以选择授权模式并提供对应凭证。4. 选择数据源后,您可以进一步选择要加载的导入任务的 Topic。您可以选择为该 Topic 创建一个消费者组。然后您可以指定已支持的消费格式。5. 定义 Topic Schema 解...
「火山引擎」数智平台 VeDI 数据中台产品双月刊 VOL.03
Kafka、ClickHouse、Hudi、Iceberg 等大数据生态组件,100%开源兼容,支持构建实时数据湖、数据仓库、湖仓一体等数据平台架构,帮助用户轻松完成企业大数据平台的建设,降低运维门槛,快速形成大数据分析能力。## **产... 支持用户在 ByteHouse 中灵活定义并使用函数,实现高性能的查询。 - 正式发布物化视图能力,通过定义物化视图实现查询加速,简化查询逻辑。 - 支持 ETL 工具 DBT connector,进一步完善任务调度、上下游对...
数据库顶会 VLDB 2023 论文解读 - Krypton: 字节跳动实时服务分析 SQL 引擎设
数据通过 Kafka 流入不同的系统。对于离线链路,数据通常流入到 Spark/Hive 中进行计算,结果通过 ETL 导入到 HBase/ES/ClickHouse 等系统提供在线的查询服务。对于实时链路, 数据会直接进入到 HBase/ES 提供高并发低... Coordinator 会访问 Meta Server 得到 Schema 和数据的最新版本号,生成分布式执行 Plan 下发给 Data Server,Data Server 负责 Query Plan 的执行。Krypton 的 Query Processor 采用了 MPP 的执行模式。 - 为了...
「火山引擎数据中台产品双月刊」 VOL.06
Kafka、ClickHouse、Hudi、Iceberg 等大数据生态组件,100%开源兼容,支持构建实时数据湖、数据仓库、湖仓一体等数据平台架构,帮助用户轻松完成企业大数据平台的建设,降低运维门槛,快速形成大数据分析能力。## **产... 需要同时具备数据权限及加脱敏权限,才可查看未被脱敏的原始数据。- **【新增血缘查询功能】** - 支持记录 SQL 作业中参与计算的所有表,并在作业管理页面展示。- 【**优化** **JDBC** **连接功能】*...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(中)
意味着用户可以接入任意一个服务节点(当然如果有需要,也可以隔离开),并且可以水平扩展,意味着平台具备支持高并发查询的能力。- **元数据服务**元数据服务(Catalog Service)提供对查询相关元数据信息的读写。Metadata 主要包括 2 部分:Table 的元数据和 Part 的元数据。表的元数据信息主要包括表的 Schema,partitioning schema,primary key,ordering key。Part 的元数据信息记录表所对应的所有 data file 的元数据,主要包括...
通过 Flink 消费日志
日志服务提供 Kafka 协议消费功能,您可以使用 Flink 的 flink-connector-kafka 插件对接日志服务,通过 Flink 将日志服务中采集的日志数据消费到下游的大数据组件或者数据仓库。 场景概述Apache Flink 是一个在有界数据流和无界数据流上进行有状态计算分布式处理引擎和框架。Flink 提供了 Apache Kafka 连接器(flink-connector-kafka)在 Kafka topic 中读取和写入数据。日志服务支持为指定的日志主题开启 Kafka 协议消费功能,开启...
达梦@记一次国产数据库适配思考过程|社区征文
最后需关闭连接close,释放资源->rs-ps-con. ```tk.mybatis:mybatis定制的第一大业务增强库。pagehelper:分页控件,mybatis定制的第二大业务增强库。## Q-A NO.3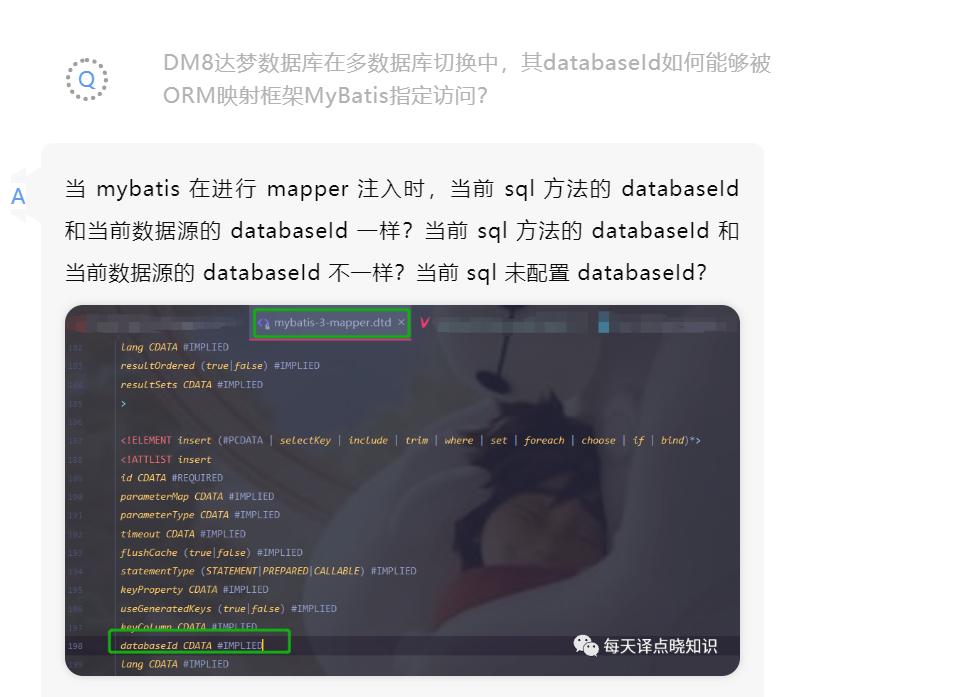其实,这都是需要我们care到的。当mybatis装配时,若是同一个方法被找到多条sql时,首先,会优先使用 databaseId 相同的 sql。若是没有...
读取 Kafka 数据写入 TOS 再映射到 LAS 外表
Kafka -> TOS 的数据流转链路,然后在 LAS 控制台创建外表,从 TOS 数据源读取文件并映射到新建的外表中。 注意事项通过 Flink 任务往 TOS 写入文件时,使用 filesystem 连接器。为确保数据的一致性和容错性,需要在 F... WITH ( 'connector' = 'datagen', 'rows-per-second'='1', 'fields.order_status.length' = '3', 'fields.order_id.min' = '1', 'fields.order_id.max' = '10000', 'fields.order_product_id.min' = '1', 'fields...
