ApachePDFBox中使用Boxable进行表格/行对齐的问题。
 社区干货
社区干货
居家办公更要高效 - 自动化办公完美提升摸鱼时间 | 社区征文
pdf 甚至 txt 文本文件,需要对这些文档做各种操作,有很多还是比较机械化的重复工作,枯燥且无味,花时间勉强能够处理,就是有点废手,特别是作为开发人员,有时候需要给大量数据做分析,要对 excel 表格和 csv 中数据整理... myTable = shape.table for row in myTable.rows: for i in range(0, len(myTable.columns)): tx = row.cells[i].text_frame.text.strip() ...
干货丨字节跳动基于 Apache Hudi 的湖仓一体方案及应用实践
Lambda 架构同样存在一系列尚待优化的问题, **涉及到计算、运维、成本等方面** : **●** 实时与批量计算结果不一致引起的数据口径对齐问题:由于批量和实时计算走的是两个计算框架和计算程序,计算结果往... 针对图中的分布情况,为了方便大家进一步的理解,图中涉及到的各部分含义如下: **●** Table:对应一张 Hudi 表;**●** Partition:可以按照指定字段进行分区,对应的是一个 Storage 的目录(类似 Hive 分...
[数据库系统] 业界列式存储浅析
Hive也在2014年发表论文介绍了广为人知的Apache ORC【9】;然后在2015年,Apache Kudu【10】论文发表。这些具有代表性的列存系统记录了列存的发展和演进。# 代表系统介绍## C-Store/Vertica### 架构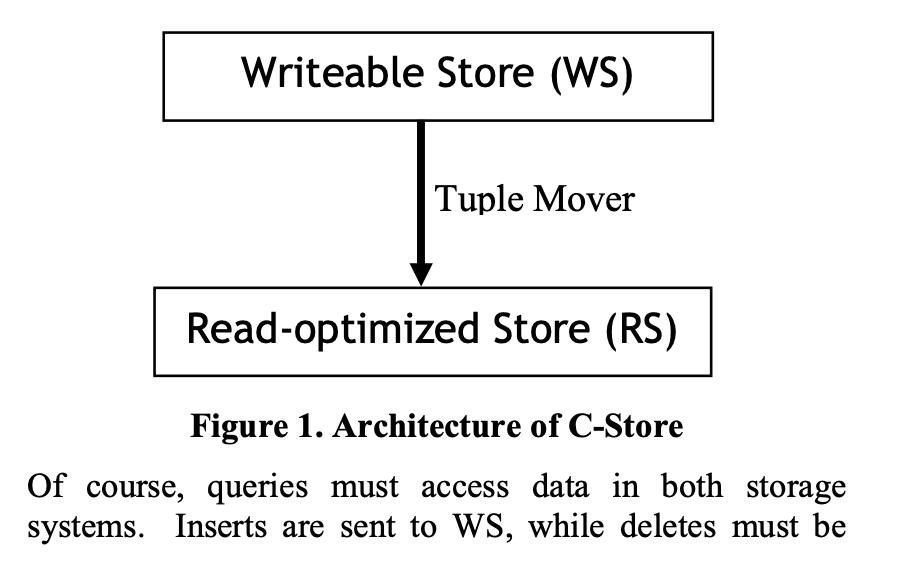系统分为两层:1. WS:Writeable store,作用是提供高性能的 inserts和 updates;1. RS: R...
火山引擎DataLeap数据质量动态探查及相关前端实现
**抽样能力:对数据进行基于质量分布特征的抽取。**目前做的是随机抽样,后续尝试基于特征来抽样。2. **数据展现:大容量的数据载体,支持对数据处理的实时展现。**前端目前是基于虚拟滚动Table做的,后续打算迁... 上下对齐位置会比较麻烦,为了解决这个问题,火山引擎DataLeap这块增加了自动定位功能,演示效果如下: 特惠活动
特惠活动
 ApachePDFBox中使用Boxable进行表格/行对齐的问题。
-优选内容
ApachePDFBox中使用Boxable进行表格/行对齐的问题。
-优选内容
 ApachePDFBox中使用Boxable进行表格/行对齐的问题。
-相关内容
ApachePDFBox中使用Boxable进行表格/行对齐的问题。
-相关内容
火山引擎 DataLeap 构建Data Catalog系统的实践(三):关键技术与总结
火山引擎 DataLeap 研发人员基本参照了Apache Atlas的设计与实现。一些基本概念简单介绍如下:- 类型(Type):描述一类元数据,由多个属性组成。例如,hive table是一类元数据,hive_db也是一类元数据。Type可具备继... 概念上可对齐Flink的source operator。- **Diff** **Operator**:接收source的输出,并从Catalog Service拉取当前系统中的全量元数据,做差异对比,产出差异的部分。概念上对齐Flink中的某一种自定义的ProcessFunct...
干货 | 字节跳动构建Data Catalog数据目录系统的实践(下)
基本参照了Apache Atlas的设计与实现。一些基本概念简单介绍如下:* 类型(Type):描述一类元数据,由多个属性组成。例如,hive table是一类元数据,hive\_db也是一类元数据。Type可具备继承关系。按面向对象的编程思想... 概念上可对齐Flink的source operator。* **Diff Operator** :接收source的输出,并从Catalog Service拉取当前系统中的全量元数据,做差异对比,产出差异的部分。概念上对齐Flink中的某一种自定义的ProcessFunction...
字节跳动使用 Flink State 的经验分享
在使用 Flink State 时是否经常会面临以下问题:* 某个状态算子出现处理瓶颈时,加资源也没法提高性能,不知该如何排查性能瓶颈* Checkpoint 经常出现执行效率慢,barrier 对齐时间长,频繁超时的现象* 大作业的 ... WriteBuffer 写满后转换为 Immutable Memtable 结构,再通过 RocksDB 的 flush 线程从内存 flush 到磁盘上;读取过程中,会先尝试从 WriteBuffer 和 Immutable Memtable 中读取数据,如果没有找到,则会查询 Block Cach...
MAD,现代安卓开发技术:Android 领域开发方式的重大变革|社区征文
**Stable Release** | 稳定发行版,最新版为 `Arctic Fox|2020.3.1` || **Release candidate** | 即将发布的下一代版本,可以提前体验新特性和优化,最新版为 `Bunblebee|2021.1.1` || **Cana... 强制执行垃圾回收以及跟踪内存分配以定位**内存方面的问题*** Battery:会监控 CPU、网络无线装置和 GPS 传感器的使用情况,并直观地显示其中每个组件消耗的电量,了解应用在**哪里耗用了不必要的电量*** Netwo...
基于Flink+Paimon的流式湖仓探索|社区征文
# 前言各位好,笔者是一名银行业的科技类员工,从2021年底开始接触实时技术,最开始实时数据加工模式是“端到端”的烟囱式开发,经过一年多的实时需求开发积累,发现存在诸多问题,比如:只支持增量计算、基础ETL操作重复... Apache Paimon作为面向流而设计的数据湖,支持大规模更新及流读,可以为用户提供高吞吐、低延迟的数据摄入、流式订阅以及实时查询能力。从使用角度而言,我总结了以下特性:1. 支持Table Format存储抽象。存储形式易...
干货 | 字节跳动数据质量动态探查及相关前端实现
**抽样能力:对数据进行基于质量分布特征的抽取。**目前做的是随机抽样,后续尝试基于特征来抽样。2. **数据展现:大容量的数据载体,支持对数据处理的实时展现。**前端目前是基于虚拟滚动Table做的,后续打算... 上下对齐位置会比较麻烦,为了解决这个问题,这块增加了自动定位功能,演示效果如下: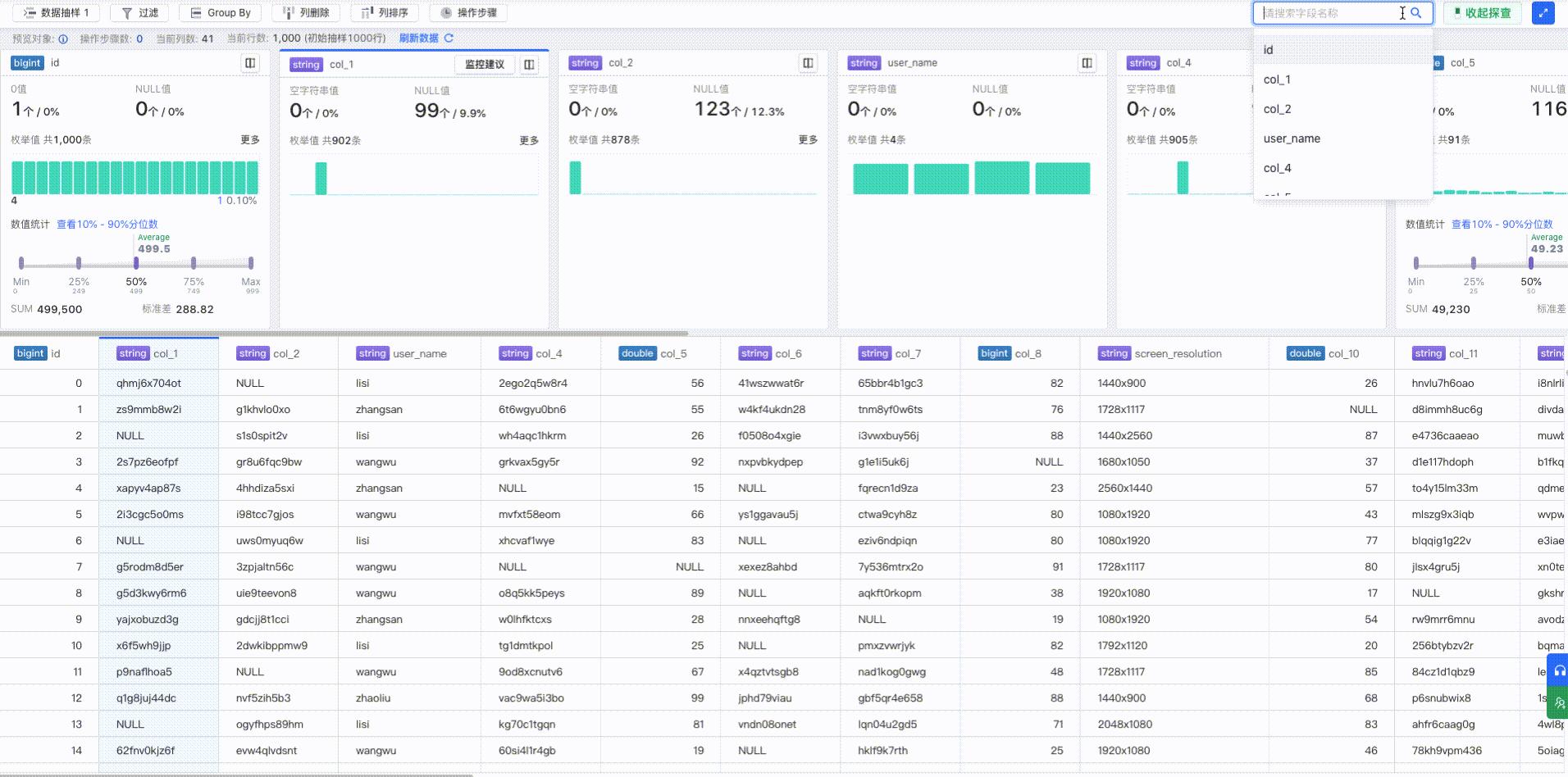...
干货丨字节跳动基于 Apache Hudi 的湖仓一体方案及应用实践
Lambda 架构同样存在一系列尚待优化的问题,**涉及到计算、运维、成本等方面**: **●**实时与批量计算结果不一致引起的数据口径对齐问题:由于批量和实时计算走的是两个计算框架和计算程序,计算结果往往不同,经常... 针对图中的分布情况,为了方便大家进一步的理解,图中涉及到的各部分含义如下: **●** Table:对应一张 Hudi 表; **●** Partition:可以按照指定字段进行分区,对应的是一个 Storage 的目录(类似 Hive 分区的概念...
新功能发布记录
满足通过一条流水线对多个应用或一个应用的多环境进行部署的需求。 全部 2024-02-29 应用部署 Kubernetes 镜像升级任务支持其他工作负载类型 与 v1 版本对齐,v2 版本 Kubernetes 镜像升级任务在支持 Deploymen... 需强制输入工作区名称进行二次确认,避免勿删。 全部 2024-01-15 管理工作区 流水线运行日志优化 解决原有日志过长时日志置底很慢的问题,提升用户使用体验。 全部 2024-01-15 无 通用制品下载 流水线预置制品下载步...
