Scala在底层使用Java集合实现吗?
 社区干货
社区干货
转型,技术人绕不开的坎
但是性能和生态远不能和java相比。随着近几年大数据,人工智能的兴起,互联网已经进入下半场。百度CEO李彦宏曾经说过:互联网只是前菜,人工智能才是主菜!那么在互联网下半场,人工智能这片蓝海中,我们技术人要不要转型,能否抓住这波红利,或许是值得每个人认真思考的问题......从研究生毕业到现在差不多工作4年,中间也经历了几次大大小小的转型,毕业跨专业找工作,从底层硬件到操作系统,再到上层应用,目前除了Android原生,也会兼任...
在线学习FTRL介绍及基于Flink实现在线学习流程|社区征文
现在做在线学习和CTR常常会用到逻辑回归( Logistic Regression),google先后三年时间(2010年-2013年)从理论研究到实际工程化实现的FTRL(Follow-the-regularized-Leader)算法,在处理诸如逻辑回归之类的带非光滑正则化... wget https://archive.apache.org/dist/flink/flink-1.13.0/flink-1.13.0-bin-scala_2.11.tgztar -xf flink-1.13.0-bin-scala_2.11.tgz && cd flink-1.13.0./bin/start-cluster.sh```### 提交flink 任务```...
亿级用户背后的字节跳动云原生计算最佳实践
为了更好地实现生态对接,基础架构的工程师们在底层计算引擎上封装了一套 Python 的接口,各业务作业通过 Python 框架使用流式计算引擎。得益于 Python 框架的存在,底层引擎从 JStorm 变更为 Flink 的工作得以在... 涵盖 SQL/Java/Scala/Python 多种语言。资源核数达 500 万 Core,在这其中包括了大量的大规模在离线混部资源。在 Spark 引擎不断发展的过程中,字节批式计算团队的工程师们同样遇到了诸多挑战。1. **如何提...
亿级用户背后的字节跳动云原生计算最佳实践
为了更好地实现生态对接,基础架构的工程师们在底层计算引擎上封装了一套 Python 的接口,各业务作业通过 Python 框架使用流式计算引擎。得益于 Python 框架的存在,底层引擎从 JStorm 变更为 Flink 的工作得以在业... 涵盖 SQL/Java/Scala/Python 多种语言。资源核数达500万 Core,在这其中包括了大量的大规模在离线混部资源。在 Spark 引擎不断发展的过程中,字节批式计算团队的工程师们同样遇到了诸多挑战。- **如何** **提升...
 特惠活动
特惠活动
 Scala在底层使用Java集合实现吗?
-优选内容
Scala在底层使用Java集合实现吗?
-优选内容
 Scala在底层使用Java集合实现吗?
-相关内容
Scala在底层使用Java集合实现吗?
-相关内容
亿级用户背后的字节跳动云原生计算最佳实践
为了更好地实现生态对接,基础架构的工程师们在底层计算引擎上封装了一套 Python 的接口,各业务作业通过 Python 框架使用流式计算引擎。得益于 Python 框架的存在,底层引擎从 JStorm 变更为 Flink 的工作得以在业... 涵盖 SQL/Java/Scala/Python 多种语言。资源核数达500万 Core,在这其中包括了大量的大规模在离线混部资源。在 Spark 引擎不断发展的过程中,字节批式计算团队的工程师们同样遇到了诸多挑战。- **如何** **提升...
亿级用户背后的字节跳动云原生计算最佳实践
为了更好地实现生态对接,基础架构的工程师们在底层计算引擎上封装了一套 Python 的接口,各业务作业通过 Python 框架使用流式计算引擎。 得益于 Python 框架的存在,底层引擎从 JStorm 变更为 Flink 的... 涵盖 SQL/Java/Scala/Python 多种语言。资源核数达500万 Core,在这其中包括了大量的大规模在离线混部资源。 在 Spark 引擎不断发展的过程中,字节批式计算团队的工程师们同样遇到了诸多挑战。 ...
Flink on K8s 企业生产化实践|社区征文
清理和重建:不像是虚拟环境以镜像进行分发部署起来对底层系统环境依赖小,所需要的包都可以集成到镜像中,重复使用。- 更好的隔离性与安全性,应用部署以pod启动,pod之间相互独立,资源环境隔离后更安全。- k8s集... K8S被称为云时代的操作系统(其中的镜像就类似软件安装包)- 旨在提供“跨主机集群的自动部署、扩展以及运行应用程序容器的平台”- 调度、资源管理、服务发现、健康检查、自动伸缩、滚动升级…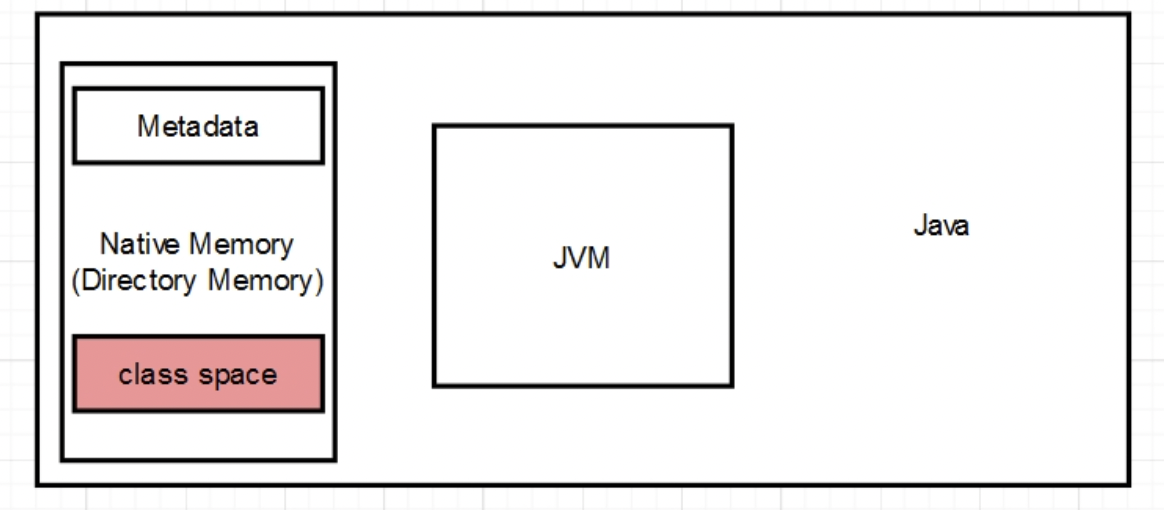两者都是和直接内存有关...
什么是云原生?
Kubernetes 在 2017 年脱颖而出成为容器编排的事实标准。各大公有云厂商也把 Kubernetes 作为容器编排产品的底层技术,并称其为云原生操作系统。Kubernetes 是 CNCF 托管的的第一个项目。CNCF,全称 Cloud Nati... 而是把它作为最底层的一个容器运行时的实现。同时 Kubernetes 还支持上文提到的 crun、kata-runtime、gVisor 等符合 OCI 标准的容器运行时。容器本身的价值虽然大,但是如果想要让其产生商业价值或者说对云计算...
