自增计算问题
 社区干货
社区干货
如何解决 MySQL 主从切换后自增列数值不一致问题?
# 问题描述客户反馈主从切换后,表的中记录的最大值比自增列的值要大,导致插入异常报错 **"Duplicate entry 'xxxx' for key 'PRIMARY'"**# 问题复现### 1.主库插入测试数据```sqlmysql> drop test_autoinc;ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'test_autoinc' at line 1mysql> drop table test_...
如何解决MySQL中73924返回值为0的问题
# 问题描述客户在含有自增主键的表格中成功插入数据后,使用73924 查询,发现返回值为 0# 问题分析因为默认会用到 MySQL 的连接池复用功能,不同语句不能保证一定在同一个连接上执行,所以会导致即使数据成功插入,但是后续查询返回值为 0 的异常。# 问题复现1.模拟批量的插入数据和73924的操作```bashfor i in `seq 10000`;do mysql -h rds-mysql-h2******.rds.ivolces.com -udemo -p******** -e "use dbtest;insert into exe...
干货|一套方案,让OLAP引擎在广告投放场景更高效
通常要求计算时间不能超过 5 秒。  特惠活动
特惠活动
 自增计算问题
-优选内容
自增计算问题
-优选内容
 自增计算问题
-相关内容
自增计算问题
-相关内容
Flink OLAP 在字节跳动的查询优化和落地实践
某些情况下会导致集群出现严重的性能问题,但是在流式和批式下只需要执行一次通常不会出现问题。因此,针对以上不同,在 OLAP 场景下进行了很多查询相关的优化,比如 Plan 的构建加速和初始化等相关优化。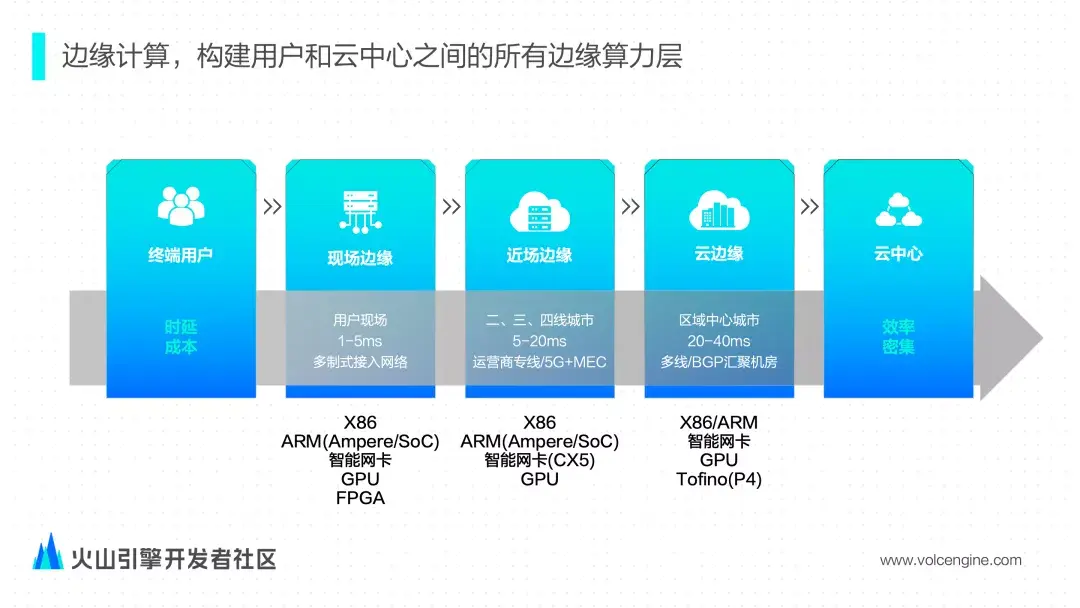\提到边缘计算云平台,首先跟大家分享一下我们对边缘计算的定义:我们把从用户到云中心之间所有的算力层都定义为边缘计算。- 首先,“**现场边缘**”主要位于用户现场或用户自己的机房。...
企业级数据平台云原生转型之路|社区征文
计算脚本。第二:Ad-Hoc(即席查询)的能力,可以在可视化页面中输入 SQL 语句来预览结果。第三:自己写计算脚本,然后提交到平台中运行。 以上三种在不同的实现上可以满足不同使用人群的需求,比如业务分析人员不太擅长写 SQL,可以通过拖拉拽的方式来生成,开发人员可以使用 Ad-Hoc 或者自己写脚本上传的方式,因为平台本身提供了环境隔离,会定期的来清理一些脏数据,所以,开发人员不需要担心集群环境方面的问题1. **数据调度...
