JdbcTemplate为每个查询创建单独的事务
 社区干货
社区干货
计算引擎在K8S上的实践|社区征文
和我们单独提交Spark Jar包任务到集群是一样的,也会启动一个Driver和多个Executor。因此这一步要做的其实就是将其提交到K8S集群上,并启动Driver对应的pod和Executor对应的pod。具体实现过程如下:## 基于deploym... template: metadata: labels: app.kubernetes.io/name: spark-thrift-server-test app.kubernetes.io/version: v3.1.1 spec: serviceAccountName: thrift-server hos...
达梦@记一次国产数据库适配思考过程|社区征文
创建脚本**,出现双引号则在实际的sql方言中也需要加上双引号,否则执行sql会抛出视图或表不存在,字段列名不存在的异常。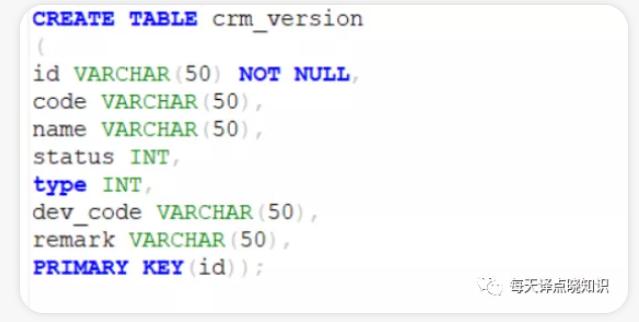若是通过**Mysql或Oracle或其他数据库,文件等方式迁移导入**。这里记录一下迁移过程中遇到的问题,**在迁移的时候,报某些字段超长**。于是,查看了MySql中那些字段的类型及长度,都...
干货|揭秘字节跳动对Apache Doris 数据湖联邦分析的升级和优化
如不支持事务、数据缺乏一致性、缺乏隔离性、无法保证数据质量等,导致数据湖管理复杂,如果管理不善,数据湖将会退化成数据沼泽。 于是,2020年湖仓一体的概念被提出,主要指在数据湖中建设存储、湖上建仓。... 再创建各种 Table。 除了 OLAP 内表模式外,还支持创建各种类型的外表,如 Hive 外表、Iceberg 外表、JDBC 外表和 ElasticSearch 外表等。 基于 Doris 原生外表模式,也可以访问数据湖中的数据源...
基于 Flink 构建实时数据湖的实践
然后通过 Flink SQL Gateway 和 Session Mode 的 Flink Cluster 进行 OLAP 查询,提供了 JDBC 和 REST API 两种接口的返回结果。当然我们也需要使用 Catalog 管理元数据,这里不仅仅指 Iceberg 的元数据,还包括了其他... Iceberg 默认的 Flinksink 会给每一个需要写入的 Parquet 文件创建一个 Streamwrtier,而这个 Streamwriter 的 Schema 是固定的,否则 Parquet 文件的写入就会报错。上图示例中原始 Schema 是 id、name、age,在 Sche...
 特惠活动
特惠活动
 JdbcTemplate为每个查询创建单独的事务
-优选内容
JdbcTemplate为每个查询创建单独的事务
-优选内容
 JdbcTemplate为每个查询创建单独的事务
-相关内容
JdbcTemplate为每个查询创建单独的事务
-相关内容
基于 Flink 构建实时数据湖的实践
然后通过 Flink SQL Gateway 和 Session Mode 的 Flink Cluster 进行 OLAP 查询,提供了 JDBC 和 REST API 两种接口的返回结果。当然我们也需要使用 Catalog 管理元数据,这里不仅仅指 Iceberg 的元数据,还包括了其他... Iceberg 默认的 Flinksink 会给每一个需要写入的 Parquet 文件创建一个 Streamwrtier,而这个 Streamwriter 的 Schema 是固定的,否则 Parquet 文件的写入就会报错。上图示例中原始 Schema 是 id、name、age,在 Sche...
基于 Flink 构建实时数据湖的实践
然后通过 Flink SQL Gateway 和 Session Mode 的 Flink Cluster 进行 OLAP 查询,提供了 JDBC 和 REST API 两种接口的返回结果。当然我们也需要使用 Catalog 管理元数据,这里不仅仅指 Iceberg 的元数据,还包括了其他... Iceberg 默认的 Flinksink 会给每一个需要写入的 Parquet 文件创建一个 Streamwrtier,而这个 Streamwriter 的 Schema 是固定的,否则 Parquet 文件的写入就会报错。上图示例中原始 Schema 是 id、name、age,在 Sche...
干货 | 看 SparkSQL 如何支撑企业级数仓
Hive 有 JDBC 客户端,支持标准 JDBC 接口访问的 HiveServer2 服务器,管理元数据服务的 Hive Metastore,以及任务以 MapReduce 分布式任务运行在 YARN 上。标准的 JDBC 接口,标准的 SQL 服务器,分布式任务执行,以... 一个查询可以快速出结果,像 Presto,Doris,ClickHouse 虽然也可以处理海量数据,甚至达到 PB 及以上,但是主要还是是用在交互式分析上,也就是基于数据仓库的 DM 层,给用户提供基于业务的交互式分析查询,方便用户快速进...
揭秘字节跳动对 Apache Doris 数据湖联邦分析的升级和优化
查询数据湖中的海量数据,势必将会给企业带来更高的价值。 数据湖和实时数仓具备不同特点: **● 数据湖:** 提供多模存储引擎,如 S3、HDFS 等,也支持多计算引擎,如 Hive、Spark、Flink 等。在事务性方面,数据湖... 再创建各种 Table。 除了 OLAP 内表模式外,还支持创建各种类型的外表,如 Hive 外表、Iceberg 外表、JDBC 外表和 ElasticSearch 外表等。 基于 Doris 原生外表模式,也可以访问数据湖中的数据源,但存在如下缺点...
字节跳动湖平台在批计算和特征场景的实践
是个独立的、没有副作用的操作流程,不会涉及到重写数据文件等操作;* Time travel:用户可任意读取历史时刻的相关数据,并使用完全相同的快照进行重复查询;* MVCC:Iceberg 通过 MVCC 来支持事务,解决读写冲突的问题... 可通过指定对应的 Snapshot ID ,实现数据回溯。**2.事务性提交*** 写操作:记录当前元数据的版本——Base Version,创建新的元数据以及 Manifest 文件,原子性将 Base Version 替换为新的版本;* 原子性替换:原...
字节跳动湖平台在批计算和特征场景的实践
是个独立的、没有副作用的操作流程,不会涉及到重写数据文件等操作。- **Time travel**:用户可任意读取历史时刻的相关数据,并使用完全相同的快照进行重复查询。- **MVCC**:Iceberg 通过 MVCC 来支持事务,解决... 可通过指定对应的 Snapshot ID ,实现数据回溯。**2.事务性提交**- 写操作:记录当前元数据的版本——Base Version,创建新的元数据以及 Manifest 文件,原子性将 Base Version 替换为新的版本。- 原子性替换...
干货|字节跳动EMR产品在Spark SQL的优化实践
这样用户只需要指定catalog即可,无需再手动输出很多指令。** **其次在Spark与Hive跨引擎分析场景下** 使用Iceberg,Spark正常创建表,Presto/Trono可以正常读写,但Hive无法正常读写,这个问题官方的文档也没有清... 提供标准的JDBC访问接口,Spark SQL引擎同样实现了Thrift 接口,Spark SQL引擎在服务启动的时候便已经被提交至Yarn,处于等待状态。当业务任务到达的时候,由SQL服务器实现引擎的筛选,匹配一个已经存在的引擎,或者重新...
字节跳动 EMR 产品在 Spark SQL 的优化实践
这样用户只需要指定catalog即可,无需再手动输出很多指令。****其次在Spark与Hive跨引擎分析场景下**使用Iceberg,Spark正常创建表,Presto/Trono可以正常读写,但Hive无法正常读写,这个问题官方的文档也没有清晰的描... 提供标准的JDBC访问接口,Spark SQL引擎同样实现了Thrift 接口,Spark SQL引擎在服务启动的时候便已经被提交至Yarn,处于等待状态。当业务任务到达的时候,由SQL服务器实现引擎的筛选,匹配一个已经存在的引擎,或者重新...
干货|DataLeap数据资产实战:如何实现存储优化?
**火山引擎DataLeap作为一站式数据中台套件,**汇集了字节内部多年积累的数据集成、开发、运维、治理、资产、安全等全套数据中台建设的经验,助力企业客户提升数据研发治理效率、降低管理成本。 Data Catalog是一种元数据管理的服务,会收集技术元数据,并在其基础上提供更丰富的业务上下文与语义,通常支持元数据编目、查找、详情浏览等功能。 **目前Data Catalog作为火山引擎大数据研发治理套件DataLeap产品的核心功能之...
