Kafka消费者本地批处理队列内存泄露
 社区干货
社区干货
Kafka 消息传递详细研究及代码实现|社区征文
Kafka 是其中之一。Apache Kafka 是一个开源的分布式事件流平台,可跨多台计算机读取、写入、存储和处理事件,并有发布和订阅事件流的特性。本文将研究 Kafka 从生产、存储到消费消息的详细过程。 ## Produce... [**batch.size**](url)当多条消息发送到一个分区时,producer 批量发送消息大小的上限 (以字节为单位)。即使没有达到这个大小,生产者也会定时发送消息,避免消息延迟过大。默认16K,值越小延迟越低,吞吐量和性能也会...
Logstash 如何通过 Kafka 协议消费 TLS 日志
# **问题现象**如何通过修改 Logstash 配置文件,实现通过 Kafka 协议消费日志到其他业务系统。# 问题分析TLS 日志服务支持通过 Logstash 消费日志数据,您可以通过配置 Logstash 服务内置的 logstash-input-kafk... 否则可能导致 AccessKey 泄露,威胁您账号下所有资源的安全, 建议使用 `jaas_path` 参数配置,示例如下```Javajaas_path => "/usr/share/logstash/config/kafka-client-jaas.conf"``````Java[root@lxb-jms con...
Redis 使用 List 实现消息队列有哪些利弊?|社区征文
消息在被处理和删除之前一直存储在队列上。每条消息仅可被一位用户处理一次。消息队列可被用于分离重量级处理、缓冲或批处理工作以及缓解高峰期工作负载。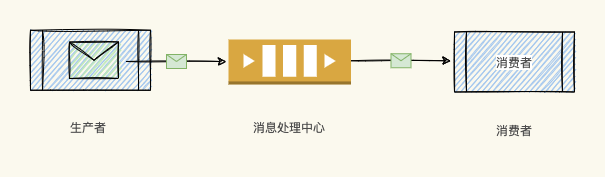- Producer:消息生产者,负责产生和发送消息到 Broker;- Broker:消息处理中心。负责消息存储、确认、重试等,一般其中会包含多个 queue;- Consumer:消息消费者,负责从 Broker ...
大象在云端起舞:后 Hadoop 时代的字节跳动云原生计算平台
消息中间件 BMQ 也是字节跳动用 C++ 重写的一套存算分离架构的消息队列服务,同样支持 Kafka 系统的平滑迁移。在云原生发展趋势下,字节跳动于2016年开始启动 TCE(Toutiao Cloud Engine)云引擎,2018年开始将核心业... 负责流处理和负责批处理的,会按照两个团队来划分任务,流团队负责处理生产上的最新数据,而批处理每天跑一下历史报表。有时候两支团队的数据和程序没办法对齐,会得出不一致的结果,这时候使用流批一体变成一支团队体验...
 特惠活动
特惠活动
 Kafka消费者本地批处理队列内存泄露
-优选内容
Kafka消费者本地批处理队列内存泄露
-优选内容
 Kafka消费者本地批处理队列内存泄露
-相关内容
Kafka消费者本地批处理队列内存泄露
-相关内容
基于火山引擎 EMR 构建企业级数据湖仓
最早它是一个批处理引擎,后来补上了 Streaming 和 AI 的能力;Trino 是一个 OLAP 引擎,现在也在大力发展批式计算;Flink 是一个流引擎,后来加上了批式计算和 AI 的能力;Doris 则在加强 multi-catalog……所以各家引擎... 流引擎 - Flink:流计算逐步扩大市场份额 - Kafka SQL:基于 Kafka 实现实时化分析 - Streaming Database:Materialize 和 RisingWave 在开发的一种产品形态,效果类似于 Data Bricks 的 Data ...
「火山引擎数据中台产品双月刊」 VOL.06
Kafka、ClickHouse、Hudi、Iceberg 等大数据生态组件,100%开源兼容,支持构建实时数据湖、数据仓库、湖仓一体等数据平台架构,帮助用户轻松完成企业大数据平台的建设,降低运维门槛,快速形成大数据分析能力。## **产... 出现消费lag。 - 扩容成本:由于分布式架构数据基本都是本地存储,在扩容以后,数据无法做Reshuffle,新扩容的机器几乎没有数据,而旧的机器上磁盘可能已经快写满,造成集群负载不均的状态,导致扩容并不能起到有效...
「火山引擎」数智平台 VeDI 数据中台产品双月刊 VOL.06
Kafka、ClickHouse、Hudi、Iceberg 等大数据生态组件,100%开源兼容,支持构建实时数据湖、数据仓库、湖仓一体等数据平台架构,帮助用户轻松完成企业大数据平台的建设,降低运维门槛,快速形成大数据分析能力。(**公众号... 出现消费lag。 - 扩容成本:由于分布式架构数据基本都是本地存储,在扩容以后,数据无法做Reshuffle,新扩容的机器几乎没有数据,而旧的机器上磁盘可能已经快写满,造成集群负载不均的状态,导致扩容并不能起到有效...
Pulsar 在云原生消息引擎领域为何如此流行?| 社区征文
#### 3.2.4 Batching(批处理)如果批处理开启,producer 将会累积一批消息,然后通过一次请求发送出去。批处理的大小取决于最大的消息数量及最大的发布延迟。#### 3.2.5 Chunking(分块) - 批处理和分块不能同时启... 然后以相同的顺序分发给消费者(独占/灾备模式)。 消费者将在内存缓存所有的块消息,直到收到所有的消息块。将这些消息合并成为原始的消息 M1,发送给处理进程。在打造 ByteHouse 的过程中,我们经过了多年的探索与沉淀,本文将和大家分享字节跳动过去使用 ClickHouse 的两个典型应用... **Kafka Engine** 的方案,也就是 ClickHouse 内置消费者去消费 Kafka。整体的架构如图:和多种机器学习引擎(TensorFlow, PyTorch, XGBoost, LightGBM, SparkML, Scikit-Learn)连接起来。同时MLX Notebook还在标准SQL的基础上拓展了MLS...
数仓进阶篇@记一次BigData-OLAP分析引擎演进思考过程 | 社区征文
可结合批处理与MPP架构; **4、** 大数据给传统的关系型数据库-DBMS带来巨大挑战,在海量数据场景下,数据实时分析-时延低、并发数高、支持SQL或类SQL,变得尤为重要! ## 现状Oracle,ElasticSearch,MySQL集群架构 目前,Oracle中多个业务库,数据集极其庞大,MySQL中多个业务库,单表数据量超过千万级别...... 